




 广告
广告





















































自动驾驶中的立体视觉
2021-12-06 09:02:39· 来源:汽车ECU开发

如今,自动驾驶的立体视觉变得越来越流行。计算机视觉领域在过去十年中发展迅猛,尤其是基于深度学习的障碍物检测和计算机视觉领域。YOLO 或 RetinaNet 等障碍物
如今,自动驾驶的立体视觉变得越来越流行。计算机视觉领域在过去十年中发展迅猛,尤其是基于深度学习的障碍物检测和计算机视觉领域。
YOLO 或 RetinaNet 等障碍物检测算法提供 2D 边界框,使用边界框给出图像中障碍物的位置。今天,大多数物体检测算法都是基于单目RGB相机,无法返回每个障碍物的距离。
为了返回每个障碍物的距离,工程师们将相机与激光雷达(光探测和测距)传感器融合,利用激光返回深度信息和传感器融合技术融合计算机视觉和激光雷达的输出。
这种方法的问题是使用了昂贵的激光雷达。工程师巧妙地利用对齐两个摄像头并使用几何形状来定义每个障碍物的距离:我们称之为伪激光雷达。

图1 单眼与立体视觉
伪激光雷达利用几何图形来构建深度地图,并将其与目标检测相结合,以获得三维距离。
实现深度估计的五个步骤:
通过两个摄像头,我们可以获得物体的距离。这是三角测量的原理,也是立体视觉背后的核心几何。下面是它的工作原理:
1、立体校准-检索相机的关键参数;
2、对极几何-定义我们设置的三维几何;
3、视差图- 计算视差图;
4、深度贴图- 计算深度贴图;
5、障碍物距离估计- 在 3D 中查找对象,并与深度图匹配。
在本文中,我们将学习如何执行这 5 个步骤来构建 3D 对象检测算法,目标是对于每个对象,我们可以估计 X、Y、Z 位置。
01.立体校准—内部和外部校准
当你在网上看任何图片时,很可能相机已经被校准过了。每个相机都需要校准。校准是指将具有[X,Y,Z]坐标的3D点转换为具有[X,Y]坐标的2D像素。
这一步的输出很简单:我们需要相机的内在参数和外在参数。这些将在稍后用于检索距离。
图像是如何产生的?
当前相机使用针孔成像原理,用一个针孔让少量的光线穿过相机,从而获得清晰的图像。

相机还可以使用镜头来变焦,获得更好的清晰度。如你所见,镜头位于距离传感器f的位置。这个距离f称为焦距。
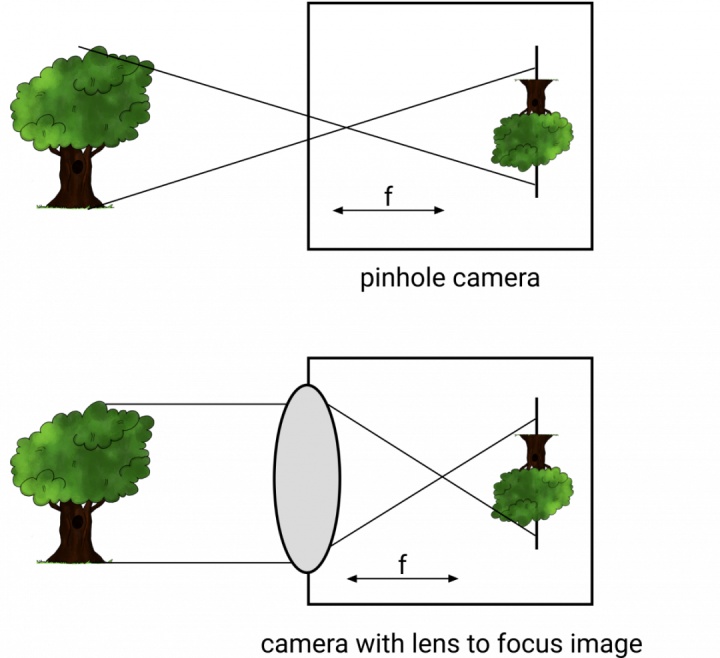
前面提到相机校准的目标是找到合适的内部和外部参数。我还说过,校准的目的是帮助我们取一个3D Point,并将其转换为Pixel,从而创建一个图像。
因此,以下是相机校准在一张图像中的工作方式:
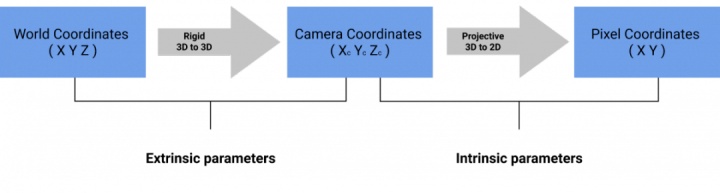
相机校准过程
外部校准
外部校准是从世界坐标到相机坐标的转换。我们通常说“这是一个特定坐标系中的 3D 点。如果我们从相机框架看,这个点的坐标是什么?”。世界中的一个点被旋转到相机框架,然后转换到相机位置。外部参数称为 R(旋转矩阵)和 T(平移矩阵)。
公式如下:

外部校准公式
内部校准
内部校准是从相机坐标到像素坐标的转换。一旦我们有了 3D 点,我们就会使用内在参数将这个 3D 点转换为像素,内在参数是我们称为 K 的矩阵。
这是世界坐标到图像转换的公式:
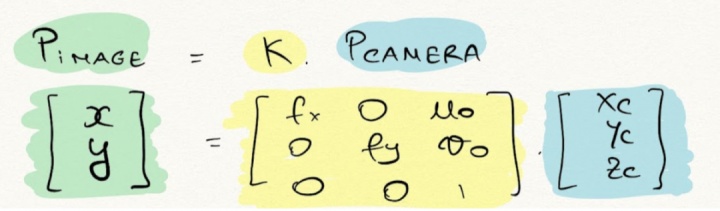
K为本征矩阵。它由f,焦距和(u,v)光学中心组成:这些都是内在参数。
最终公式:
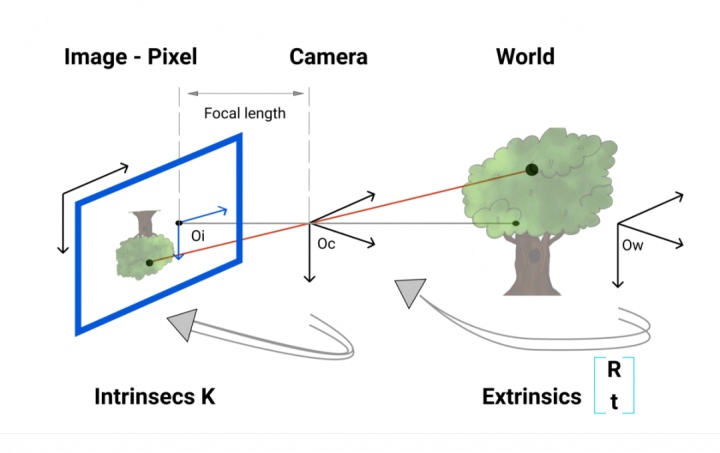
所以,我们现在知道,给定世界上的一个点,我们可以使用外部校准将其转换为相机帧,然后使用内部校准将其转换为像素。
这是我们使用的最终公式:

你可以注意到,外部矩阵已经被修改了,这是因为矩阵乘法需要矩阵形状来匹配,因此我们转向了齐次坐标。
接下来,让我们看看它如何与 OpenCV 配合使用。
相机校准:立体视觉和 OpenCV
通常,我们使用一个棋盘和自动算法来执行它。我们告诉算法棋盘上的一个点(例如:0,0,0)对应于图像中的一个像素(例如:545,343)。

校准示例
为此,我们必须用相机拍摄棋盘,获取一些图像,校准算法通过最小化最小二乘法的损失来确定相机的校准矩阵。
通常,为了消除图像失真,需要进行校准。针孔相机模型包括一个失真,“ GoPro 效应”。为了得到校正后的图像,需要进行校准。畸变可以是径向的,也可以是切向的。校准有助于消除图像的扭曲。

图像校准
在校准过程的最后,你有两个校正图像的参数K, R,和T:

极性几何——立体视觉
02.极性几何—立体视觉
立体视觉是基于两幅图像寻找深度信息。我们的眼睛就像两台相机。他们从不同的角度获取图像,计算两个视角之间的差异,并建立一个距离估计。
在一个立体视觉系统中的两个摄像头,一般在同一高度对齐。那么,我们如何使用设置和几何设计一个系统?
立体相机如何估计深度?
假设你有两个相机,其 Y 轴和 Z 轴坐标一致,唯一的区别就是它们的 X 值。
现在两个相机 CL (相机左)和 CR (相机右)看着一个障碍 O 。通过处理几何关系,我们可以计算障碍物的距离。
相机与障碍物的几何关系
我们的目标是O点的估计Z轴坐标值,即O点的距离(表示图像中的任何像素)。
-
X 是对齐轴
-
Y是高度
-
Z 是深度
-
xL 对应于左侧摄像机图像中的点。右侧图像的 xR 相同
-
b 是两个相机X轴上的距离。
根据上述参数,我们可以用相似三角形得到这张图中的两个方程。
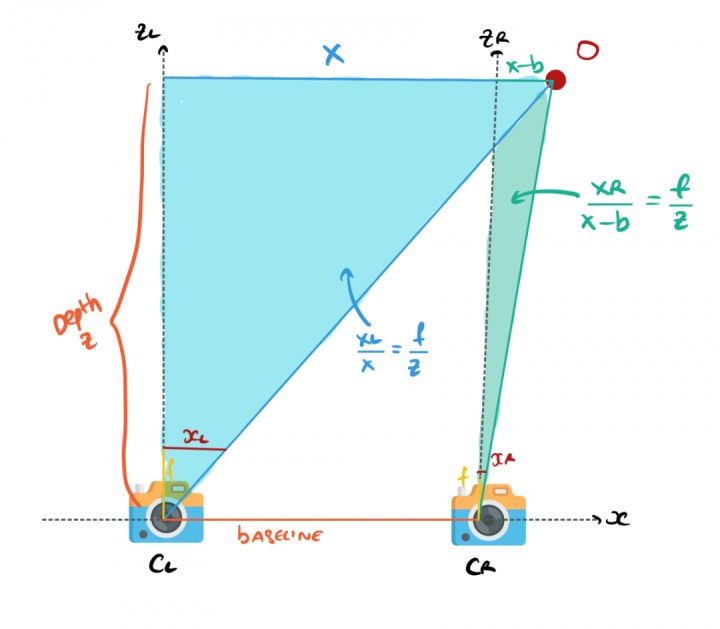
对于左侧相机:
对于右侧相机:
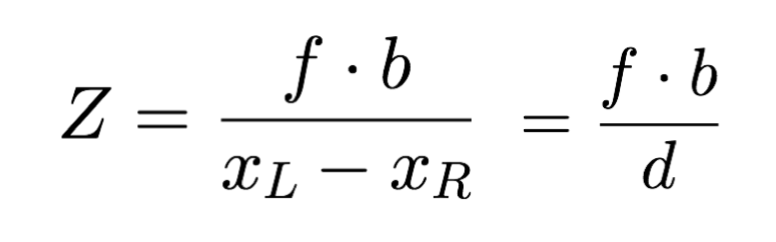
当我们进行数学运算后,我们可以快速得到 Z,甚至可以推导出 X 和 Y。
03.立体视差和映射
什么是视差?
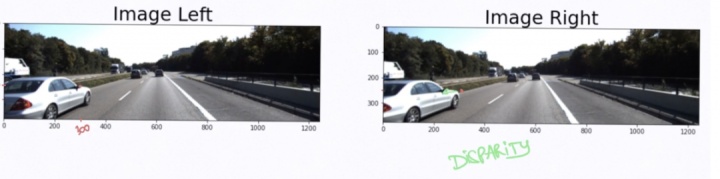
视差是同一 3D 点在 2 个不同相机角度的图像位置差异。
具体来说,如果我取左边图像的侧视镜像素(300,175);其在右边的图像像素位置位(250,175)。
在本例中,xL=300 且 xR=250。视差为 xL-xR;或者是 50 像素。它是通过相同的算法估算出来的。

为每个像素计算视差,你会得到一个视差图!正如下图所示,近距离的物体比远距离的物体要亮,远距离的物体用深色表示。我们已经有了一种深度信息了。

立体匹配
为什么是“对极几何”?
为了计算视差,我们必须找到左侧图像中的每个像素并将其与右侧图像中的每个像素匹配。这称为立体匹配。
为了解决这个问题——
在左侧图像中取一个像素,要在右侧图像中找到对应的像素,只需在极线上搜索。而不需要进行2D搜索,点应该位于这条线上,搜索范围缩小到1D。

在上面的例子中,通过校准和校正后,左右两侧相机在相同的高度上。我们只进行一维搜索。
对级搜索可以通过许多不同的方式进行:局部方法、全球方法、半全球方法、深度学习。OpenCV 的基本功能可以解决这个问题,但不如当前的深度学习方法精确。
04.立体视觉—从视差到深度图
我们有两个视差图,它基本上告诉我们两幅图像之间像素的移动。对于每个摄像机,我们还有一个投影矩阵:P _ left 和 P _ right 。
为了估计深度,我们需要估计 K , R 和 t 。
根据公式:
深度图
现在可以生成深度图了。
深度图使用另一幅图像和视差图告诉我们图像中每个像素的距离。
过程如下:
-
从
- 下一篇:三元锂离子电池高温诱导热失控试验研究
- 上一篇:混合动力汽车噪声和振动特性及其控



 广告
广告 



最新资讯
-
联合国法规R73对货车侧面防护装置的工程化
2026-03-09 12:14
-
联合国法规R72对HS1卤素灯摩托车前照灯的工
2026-03-09 12:13
-
《汽车环境风洞 雪模拟试验及评价方法》国
2026-03-09 10:56
-
《汽车空气动力学与声学风洞 流场校准规范
2026-03-09 10:56
-
电池耐久试验方法的工程逻辑:SRC循环与多
2026-03-09 10:55
