




 广告
广告





















































深度霍夫投票在点云3D物体检测中的应用
2021-03-24 11:04:54· 来源:同济智能汽车研究所

编者按:基于点云的3D目标检测是自动驾驶系统重要的一环。3D目标检测的目的是对3D场景中的对象进行定位和识别。更具体地说,在这项工作中,我们的目标是估计定向
编者按:基于点云的3D目标检测是自动驾驶系统重要的一环。3D目标检测的目的是对3D场景中的对象进行定位和识别。更具体地说,在这项工作中,我们的目标是估计定向的3D边界框以及点云对象的语义类。与2D图像相比,3D点云具有精确的几何形状和对光照变化的鲁棒性。但是,点云是不规则的。因此,典型的CNN不太适合直接处理点云数据。在这项工作中,我们提出一个直接处理原始数据、不依赖任何2D检测器的点云3D检测框架。这个检测网络称为VoteNet,是点云3D深度学习模型的最新进展,并受到用于对象检测的广义霍夫投票过程的启发。
本文译自:
《DEEP HOUGH VOTING FOR 3D OBJECT DETECTION IN POINT CLOUDS》
文章来源:
International Journal of Aotumotive Technology,Vol.20,No.5,pp.1033-1042(2019)
作者:
Charles R. Qi 1 Or Litany 1 Kaiming He 1 Leonidas J. Guibas 1,2
原文链接:
https://arxiv.org/abs/1904.08963v1
摘要:当前的3D目标检测方法受2D检测器的影响很大。为了利用2D检测器的架构,它们通常将3D点云转换为规则的网格,或依赖于在2D图像中检测来提取3D框。很少有人尝试直接检测点云中的物体。在这篇论文中,研究人员回归第一原则,为点云数据构建了一个尽可能通用的3D检测架构。然而,由于数据的稀疏性,直接从场景点预测边界框参数时面临一个主要挑战:一个3D物体的质心可能远离任何表面点,因此很难用一个步骤准确地回归。为了解决这一问题,我们提出了VoteNet,这是一个基于深度网络和霍夫投票的端到端3D目标检测网络。该模型设计简单,模型尺寸紧凑,而且效率高,在ScanNet和SUN RGB-D两大真实3D扫描数据集上实现了最先进的3D检测精度。值得一提的是,VoteNet不依赖彩色图像,使用纯几何信息。
关键词:自动驾驶汽车,深度学习,目标检测,霍夫投票
1 引言
为了避免处理不规则点云,目前的3D检测方法在很多方面都严重依赖基于2D的检测器。例如,将Faster/Mask R-CNN等2D检测框架扩展到3D,或者将点云转换为常规的2D鸟瞰图像,然后应用2D检测器来定位对象。然而,这会牺牲几何细节,而这些细节在杂乱的室内环境中可能是至关重要。
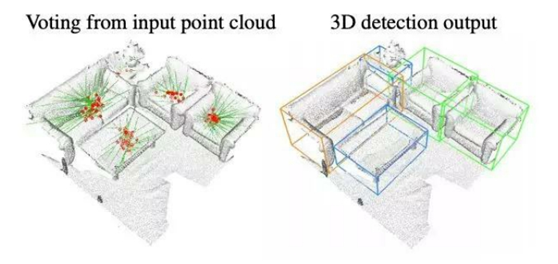
图1 基于深度霍夫投票模型的点云3D目标检测
我们利用了 PointNet++,这是一个用于点云学习的分层深度网络,以减少将点云转换为规则结构的需要。通过直接处理点云,不仅避免了量化过程中信息的丢失,而且通过仅对感测点进行计算,利用了点云的稀疏性。
虽然PointNet++在对象分类和语义分割方面都很成功,但很少有研究使用这种架构来检测点云中的3D对象。
一个简单的解决方案是遵循2D检测器的常规做法,并执行密集物体提案,即直接从感测点提出3D边界框。然而,点云的固有稀疏性使得这种方法不适宜。在图像中,通常在目标中心附近存在一个像素,但在点云中却不是这样。由于深度传感器仅捕获物体的表面,因此3D物体的中心很可能在远离任何点的空白空间中。因此,基于点的网络很难在目标中心附近聚集场景上下文。简单地增加感知域并不能解决这个问题,因为当网络捕获更大的上下文时,它也会导致包含更多的附近的对象和杂物。
为此,我们提出赋予点云深度网络一种类似于经典霍夫投票的投票机制。通过投票,我们基本上生成了靠近对象中心的新的点,这些点可以进行分组和聚合,以生成提案。与传统的多独立模块、难以联合优化的霍夫投票相比,VoteNet是端到端优化的。具体来说,在通过主干点云网络传递输入点云之后,我们对一组种子点进行采样,并根据它们的特征生成投票。投票的目标是到达目标中心。因此,投票集群出现在目标中心附近,然后可以通过一个学习模块进行聚合,生成提案。其结果是一个强大的3D物体检测器,它是纯几何的,可以直接应用于点云。
我们在两个具有挑战性的3D目标检测数据集上评估了我们的方法:SUN RGB-D数据集和 ScanNet数据集。在这两个数据集上,仅使用几何信息的VoteNet明显优于使用RGB和几何甚至多视图RGB图像的现有技术。我们的研究表明,投票方案支持更有效的上下文聚合,并验证了当目标中心远离目标表面时,VoteNet能够提供最大的改进。总之,我们工作的贡献是:
在通过端到端可微架构进行深度学习的背景下,重新制定了霍夫投票,称之为VoteNet。在SUN RGB-D和ScanNet两个数据集上实现了最先进的3D目标检测性能。深入分析了投票在点云3D目标检测中的重要性。
2 相关工作
由于直接 3D 场景识别的复杂性,许多方法都采用某些投影。比如在MV3D和VoxelNet,3D数据在进入其他模块前先降维为鸟瞰图,通过先处理2D输入来减少搜索空间的维度被Frustum PointNets[34]和[20]所采用。类似地,[16]利用3D投影验证了一个分割假设。最近,PointRCNN和GSPN使用点云深度网络来检测3D物体。
物体检测中的霍夫投票:最初在50年代后期推出,霍夫变换将点样本中检测图案转化为在参数空间中检测峰值。广义霍夫进一步拓展到以图象补丁为指标预测复杂物体的存在性。使用霍夫投票的例子包括[24]的开创性工作,它介绍了3D点云的平面提取和隐式形状模型以及6D姿态估计。
霍夫投票也和最新技术相结合。[30]中,投票被分配以不同的权重,该权重通过最大值框架学习得到。[8,7]将霍夫森林引入目标检测。最近,[15]通过使用深度特征提取构建代码本的方式提高了6D位姿估计。[31]也是利用深度特征构建的代码本提高了MRI的语义分割。[14]中,经典霍夫算法应用于在汽车标志中提取圆形图案,随后被输入到一个分类网络。[33]提出2D实例分割的子流行卷积,这也和霍夫投票有关。还有些工作使用霍夫投票来进行3D物体检测[50, 18, 47, 19],但都采用了和2D检测器类似的模块。
点云上的深度学习:最近设计适合点云的网络架构的研究越来越多[35, 36, 43, 1, 25, 9, 48, 45, 46, 22, 17,53, 52, 49, 51],在3D物体分类、部分分割以及场景分割上性能卓越。在3D目标检测领域,VoxelNet[55]通过学习体素中的点来编码体素特征,而[34]用 PointNet在2D边界框切割出的平截头体的点云来定位对象。然而,很少有研究提出如何直接从原始点云中提出和检测3D物体。
3 深度霍夫投票
传统的霍夫投票2D检测器包括离线和在线两个步骤。首先,给定一系列带注释的图像集,使用存储在图像补丁(或他们的特征)和他们到对应物体中心的偏移量之间的映射构建一个代码本。在推理时,从图像中选择兴趣点来提取周围的补丁,将这些补丁和代码本里的补丁相比较,以检索偏移并计算投票。由于对象补丁倾向于投票一致,因此集群将在目标中心附近形成。最后,通过将集群投票追溯到它们生成的补丁来检索对象边界。
我们确定这种技术非常适合我们感兴趣的问题,有两个方面:
首先,基于投票的检测比起 RPN 来更适合稀疏数据,RPN 生成的接近物体中心的提案更可能在一个空的空间,造成额外的计算量。
其次,霍夫投票自底向上的原理,积累少量的局部信息以形成可靠的检测。
然而,传统的霍夫投票是由多个独立的模块组成的,将其集成到点云网络仍然是一个开放的研究课题。为此,我们建议对不同模块进行以下调整:
兴趣点由深度神经网络来描述和选择,而不是依赖手工制作的特性。
投票生成是通过网络学习的,而不是使用代码本。利用更大的感受野,可以使投票减少模糊,从而更有效。此外,还可以使用特征向量对投票位置进行增强,从而实现更好的聚合。
投票聚合是通过可训练参数的点云处理层实现的。利用投票功能,网络可以过滤掉低质量的选票,并生成改进的proposal。
提案的形式是:位置、维度、方向、语义类,都可以直接从聚合特征生成,从而减少了追溯投票起源的需要。
接下来,我们将描述如何将上述所有组件组合成一个名为VoteNet的端到端网络。
4 VoteNet架构
图2描述了我们提出的端到端检测网络VoteNet的架构。整个网络可以分为两部分:一部分处理现有的点来生成投票;另一部分处理虚拟点——投票来提议和分类对象。
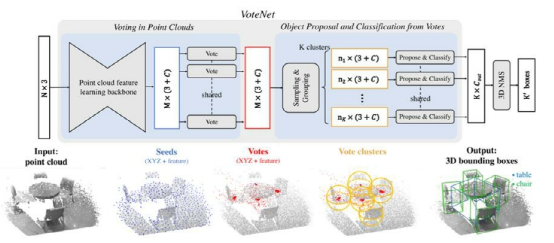
图2 用于点云中3D目标检测的VoteNet架构
(Ⅰ)点云学习投票
给定一个包含N个点和XYZ坐标的输入点云,一个主干网络(使用PointNet++实现),对这些点进行采样和学习深度特性,并输出M个点的子集。这些点的子集被视为种子点。每个种子通过投票模块独立地生成一个投票。然后将投票分组为集群,并由proposal模块处理,生成最终的提案。
(Ⅱ)实现细节
输入和数据增强。输入到目标检测网络的是随机采样的N个点。除了XYZ坐标,我们还包括了每个点的高度特征,代表点到地面的距离。地面高度被估计为所有点高度的1%。为了增强数据,我们随机采样,还在水平方向上随机翻转点云,绕着垂直轴随机旋转场景点[−5°,5°],或者随机缩放[0.9,1.1]。
训练网络。端到端的训练,使用 Adam 优化器,批处理量8和初始学习率0.001。在迭代 80轮后学习率下降10倍,在120轮后再下降10倍。在Volta Quadro GP100 GPU上训练网络 SUN RGB-D用了10小时,ScanNetV2用了少于4小时。
推理。我们的VoteNet能够把整个场景的点云输入并在一次前向传播中生成proposal。接着这些proposal经过IOU阈值0.25的NMS。评价和[42]一样采用平均精度。
5 实验
在这部分我们首先在两个大型3D室内目标检测基准上,将我们基于霍夫投票的检测器与之前最先进的方法进行比较。然后,我们提供了分析实验来了解投票的重要性、不同的投票聚合方法的效果,并展示了我们的方法在紧凑性和效率方面的优势。最后,我们展示了我们的检测器的定性结果。论文附录中提供了更多的分析和可视化。
(Ⅰ)和最新方法比较
给定一个包含N个点和XYZ坐标的输入点云,一个主干网络(使用PointNet++实现),对这些点进行采样和学习深度特性,并输出M个点的子集。这些点的子集被视为种子点。每个种子通过投票模块独立地生成一个投票。然后将投票分组为集群,并由proposal模块处理,生成最终的提案。
SUN RGB-D [40]是用于三维场景理解单视图 RGB-D 数据集。该数据集包含37个类别,其中~5K用于训练,每一个图像都标记了完整带朝向的3D框。我们首先用提供的相机参数将深度图像转为点云作为网络的输入。我们在10个类别上遵循标准的评估方式。
ScanNetV2 [5]是一个带有丰富注释的3D重建网格的室内场景数据集。它包含从数百个房间搜集的~1.2K个训练样本,有18个物体类别的语义和实例分割标注。相比于 SUN RGB-D 的部分扫描,ScanNetV2场景更完整,涵盖更多对象更大区域。我们采样重建网格的顶点作为我们的输入点云。由于ScanNetV2不提供带朝向的3D框,我们改为预测正3D框。
方法的对比。我们比较了多种现有方法。深滑动形状(DSS)[42]和3D-SIS [12]均为3D CNN检测器,结合了几何形状和RGB特征,使用Faster R-CNN [37]的流程。与DSS、3D-SIS引入复杂的传感器融合方案相比(将RGB特征投影到3D体素),因此能够使用多个RGB视图来提高性能。2D驱动[20]和F-PointNet[34]是基于2D的3D检测器,通过检测图像来减少三维检测的搜索空间。梯度点云基于滑动窗口,使用设计的3D HoG特征的检测器。MRCNN 2D-3D直接将Mask-RCNN[11]的实例分割结果投影到3D获得边框估计。GSPN[54]是使用生成模型提出对象实例,其也基于PointNet ++骨干。
表1 SUN RGB-D val数据集上的3D目标检测结果
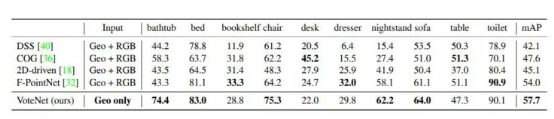
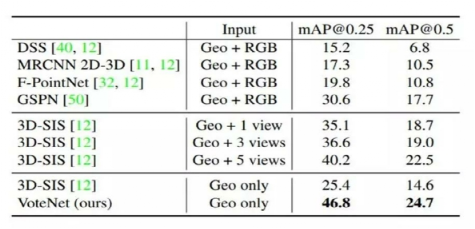
结果如表1和表2所示。在SUN RGB-D和ScanNet两个数据集中,VoteNet的性能都优于先前的方法,分别增加了3.7和18.4mAP。表1表明,当类别是训练样本最多的“椅子”时,我们的方法比以前的最优方法提高11AP。值得注意的是,我们仅使用几何信息就实现了这样的提升,而他们除点云外还使用RGB图像。表2表明,仅使用几何输入时,我们的方法显著优于基于3D CNN的3D-SIS方法,超过了20AP。
表2 ScanNetV2 val数据集上的3D目标检测结果
(Ⅱ)分析实验
投票好还是不投票好呢?我们采用了一个简单的基线网络,称之为 BoxNet,它直接从采样的场景点提出检测框,而不需要投票。BoxNet具有与VoteNet相同的主干,但它不采用投票机制,而是直接从种子点生成框。
表3 VoteNet和no-vote基线的比较

那么,投票在哪些方面有帮助呢?我们认为,由于在稀疏的3D点云中,现有的场景点往往远离目标中心点,直接的proposal可能置信度较低或不准确。投票让这些低置信度的点更接近,并允许通过聚合来强化它们的假设。在图3中,我们在一个典型的ScanNetV2场景中演示了这种现象。从图中可以看出,与BoxNet(图左)相比,VoteNet(图右)提供了更广泛的 “好” 种子点的覆盖范围,显示了投票带来的稳健性。

图3 投票有助于增加检测上下文,从而增加了准确检测的可能性
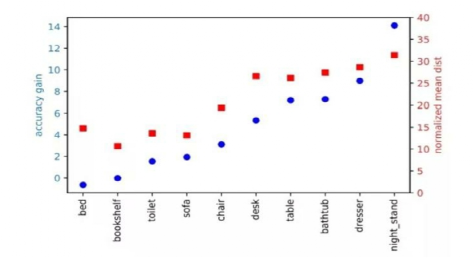
图4 当目标点远离目标中心的情况下,投票更有帮助
图6和图7分别展示了 ScanNet 和 SUN RGB-D 场景中 VoteNet 检测结果的几个代表性例子。可以看出,场景是非常多样化的,并提出了多种挑战,包括杂乱,噪声,扫描的伪像等。尽管有这些挑战,我们的网络仍显示出相当强大的结果。
例如,图6展示了如何在顶部场景中正确地检测到绝大多数椅子。我们的方法能够很好地区分左下角场景中连起来的沙发椅和沙发;并预测了右下角那张不完整的、杂乱无章的桌子的完整边界框。
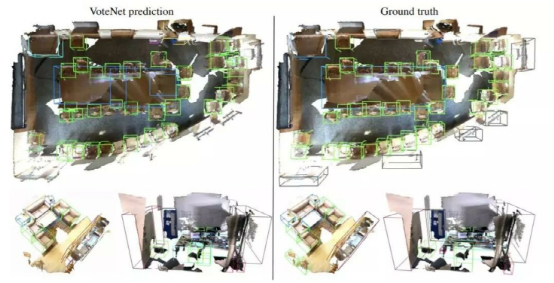
图6 ScanNetV2中3D目标检测的定性结果。左:VoteNet 的结果,右: ground-truth

图7 SUN RGB-D中3D目标检测的定性结果。(从左到右):场景的图像,VoteNet的3D对象检测,以及ground-truth注释
6 结论
在这项工作中,我们介绍了VoteNet:一个简单但强大的3D对象检测模型,受到霍夫投票的启发。该网络学习直接从点云向目标质心投票,并学会通过它们的特性和局部几何信息来聚合投票,以生成高质量的 object proposals。该模型仅使用3D点云,与之前使用深度和彩色图像的方法相比,有了显著的改进。
在未来的工作中,我们将探索如何将RGB图像纳入这个检测框架,并在下游应用(如3D实例分割) 汇总利用我们的检测器。我们相信霍夫投票和深度学习的协同作用可以推广到更多的应用领域,如 6D 姿态估计、基于模板的检测等,并期待在这方面看到更多的研究。
本文译自:
《DEEP HOUGH VOTING FOR 3D OBJECT DETECTION IN POINT CLOUDS》
文章来源:
International Journal of Aotumotive Technology,Vol.20,No.5,pp.1033-1042(2019)
作者:
Charles R. Qi 1 Or Litany 1 Kaiming He 1 Leonidas J. Guibas 1,2
原文链接:
https://arxiv.org/abs/1904.08963v1
摘要:当前的3D目标检测方法受2D检测器的影响很大。为了利用2D检测器的架构,它们通常将3D点云转换为规则的网格,或依赖于在2D图像中检测来提取3D框。很少有人尝试直接检测点云中的物体。在这篇论文中,研究人员回归第一原则,为点云数据构建了一个尽可能通用的3D检测架构。然而,由于数据的稀疏性,直接从场景点预测边界框参数时面临一个主要挑战:一个3D物体的质心可能远离任何表面点,因此很难用一个步骤准确地回归。为了解决这一问题,我们提出了VoteNet,这是一个基于深度网络和霍夫投票的端到端3D目标检测网络。该模型设计简单,模型尺寸紧凑,而且效率高,在ScanNet和SUN RGB-D两大真实3D扫描数据集上实现了最先进的3D检测精度。值得一提的是,VoteNet不依赖彩色图像,使用纯几何信息。
关键词:自动驾驶汽车,深度学习,目标检测,霍夫投票
1 引言
为了避免处理不规则点云,目前的3D检测方法在很多方面都严重依赖基于2D的检测器。例如,将Faster/Mask R-CNN等2D检测框架扩展到3D,或者将点云转换为常规的2D鸟瞰图像,然后应用2D检测器来定位对象。然而,这会牺牲几何细节,而这些细节在杂乱的室内环境中可能是至关重要。
图1 基于深度霍夫投票模型的点云3D目标检测
我们利用了 PointNet++,这是一个用于点云学习的分层深度网络,以减少将点云转换为规则结构的需要。通过直接处理点云,不仅避免了量化过程中信息的丢失,而且通过仅对感测点进行计算,利用了点云的稀疏性。
虽然PointNet++在对象分类和语义分割方面都很成功,但很少有研究使用这种架构来检测点云中的3D对象。
一个简单的解决方案是遵循2D检测器的常规做法,并执行密集物体提案,即直接从感测点提出3D边界框。然而,点云的固有稀疏性使得这种方法不适宜。在图像中,通常在目标中心附近存在一个像素,但在点云中却不是这样。由于深度传感器仅捕获物体的表面,因此3D物体的中心很可能在远离任何点的空白空间中。因此,基于点的网络很难在目标中心附近聚集场景上下文。简单地增加感知域并不能解决这个问题,因为当网络捕获更大的上下文时,它也会导致包含更多的附近的对象和杂物。
为此,我们提出赋予点云深度网络一种类似于经典霍夫投票的投票机制。通过投票,我们基本上生成了靠近对象中心的新的点,这些点可以进行分组和聚合,以生成提案。与传统的多独立模块、难以联合优化的霍夫投票相比,VoteNet是端到端优化的。具体来说,在通过主干点云网络传递输入点云之后,我们对一组种子点进行采样,并根据它们的特征生成投票。投票的目标是到达目标中心。因此,投票集群出现在目标中心附近,然后可以通过一个学习模块进行聚合,生成提案。其结果是一个强大的3D物体检测器,它是纯几何的,可以直接应用于点云。
我们在两个具有挑战性的3D目标检测数据集上评估了我们的方法:SUN RGB-D数据集和 ScanNet数据集。在这两个数据集上,仅使用几何信息的VoteNet明显优于使用RGB和几何甚至多视图RGB图像的现有技术。我们的研究表明,投票方案支持更有效的上下文聚合,并验证了当目标中心远离目标表面时,VoteNet能够提供最大的改进。总之,我们工作的贡献是:
在通过端到端可微架构进行深度学习的背景下,重新制定了霍夫投票,称之为VoteNet。在SUN RGB-D和ScanNet两个数据集上实现了最先进的3D目标检测性能。深入分析了投票在点云3D目标检测中的重要性。
2 相关工作
由于直接 3D 场景识别的复杂性,许多方法都采用某些投影。比如在MV3D和VoxelNet,3D数据在进入其他模块前先降维为鸟瞰图,通过先处理2D输入来减少搜索空间的维度被Frustum PointNets[34]和[20]所采用。类似地,[16]利用3D投影验证了一个分割假设。最近,PointRCNN和GSPN使用点云深度网络来检测3D物体。
物体检测中的霍夫投票:最初在50年代后期推出,霍夫变换将点样本中检测图案转化为在参数空间中检测峰值。广义霍夫进一步拓展到以图象补丁为指标预测复杂物体的存在性。使用霍夫投票的例子包括[24]的开创性工作,它介绍了3D点云的平面提取和隐式形状模型以及6D姿态估计。
霍夫投票也和最新技术相结合。[30]中,投票被分配以不同的权重,该权重通过最大值框架学习得到。[8,7]将霍夫森林引入目标检测。最近,[15]通过使用深度特征提取构建代码本的方式提高了6D位姿估计。[31]也是利用深度特征构建的代码本提高了MRI的语义分割。[14]中,经典霍夫算法应用于在汽车标志中提取圆形图案,随后被输入到一个分类网络。[33]提出2D实例分割的子流行卷积,这也和霍夫投票有关。还有些工作使用霍夫投票来进行3D物体检测[50, 18, 47, 19],但都采用了和2D检测器类似的模块。
点云上的深度学习:最近设计适合点云的网络架构的研究越来越多[35, 36, 43, 1, 25, 9, 48, 45, 46, 22, 17,53, 52, 49, 51],在3D物体分类、部分分割以及场景分割上性能卓越。在3D目标检测领域,VoxelNet[55]通过学习体素中的点来编码体素特征,而[34]用 PointNet在2D边界框切割出的平截头体的点云来定位对象。然而,很少有研究提出如何直接从原始点云中提出和检测3D物体。
3 深度霍夫投票
传统的霍夫投票2D检测器包括离线和在线两个步骤。首先,给定一系列带注释的图像集,使用存储在图像补丁(或他们的特征)和他们到对应物体中心的偏移量之间的映射构建一个代码本。在推理时,从图像中选择兴趣点来提取周围的补丁,将这些补丁和代码本里的补丁相比较,以检索偏移并计算投票。由于对象补丁倾向于投票一致,因此集群将在目标中心附近形成。最后,通过将集群投票追溯到它们生成的补丁来检索对象边界。
我们确定这种技术非常适合我们感兴趣的问题,有两个方面:
首先,基于投票的检测比起 RPN 来更适合稀疏数据,RPN 生成的接近物体中心的提案更可能在一个空的空间,造成额外的计算量。
其次,霍夫投票自底向上的原理,积累少量的局部信息以形成可靠的检测。
然而,传统的霍夫投票是由多个独立的模块组成的,将其集成到点云网络仍然是一个开放的研究课题。为此,我们建议对不同模块进行以下调整:
兴趣点由深度神经网络来描述和选择,而不是依赖手工制作的特性。
投票生成是通过网络学习的,而不是使用代码本。利用更大的感受野,可以使投票减少模糊,从而更有效。此外,还可以使用特征向量对投票位置进行增强,从而实现更好的聚合。
投票聚合是通过可训练参数的点云处理层实现的。利用投票功能,网络可以过滤掉低质量的选票,并生成改进的proposal。
提案的形式是:位置、维度、方向、语义类,都可以直接从聚合特征生成,从而减少了追溯投票起源的需要。
接下来,我们将描述如何将上述所有组件组合成一个名为VoteNet的端到端网络。
4 VoteNet架构
图2描述了我们提出的端到端检测网络VoteNet的架构。整个网络可以分为两部分:一部分处理现有的点来生成投票;另一部分处理虚拟点——投票来提议和分类对象。
图2 用于点云中3D目标检测的VoteNet架构
(Ⅰ)点云学习投票
给定一个包含N个点和XYZ坐标的输入点云,一个主干网络(使用PointNet++实现),对这些点进行采样和学习深度特性,并输出M个点的子集。这些点的子集被视为种子点。每个种子通过投票模块独立地生成一个投票。然后将投票分组为集群,并由proposal模块处理,生成最终的提案。
(Ⅱ)实现细节
输入和数据增强。输入到目标检测网络的是随机采样的N个点。除了XYZ坐标,我们还包括了每个点的高度特征,代表点到地面的距离。地面高度被估计为所有点高度的1%。为了增强数据,我们随机采样,还在水平方向上随机翻转点云,绕着垂直轴随机旋转场景点[−5°,5°],或者随机缩放[0.9,1.1]。
训练网络。端到端的训练,使用 Adam 优化器,批处理量8和初始学习率0.001。在迭代 80轮后学习率下降10倍,在120轮后再下降10倍。在Volta Quadro GP100 GPU上训练网络 SUN RGB-D用了10小时,ScanNetV2用了少于4小时。
推理。我们的VoteNet能够把整个场景的点云输入并在一次前向传播中生成proposal。接着这些proposal经过IOU阈值0.25的NMS。评价和[42]一样采用平均精度。
5 实验
在这部分我们首先在两个大型3D室内目标检测基准上,将我们基于霍夫投票的检测器与之前最先进的方法进行比较。然后,我们提供了分析实验来了解投票的重要性、不同的投票聚合方法的效果,并展示了我们的方法在紧凑性和效率方面的优势。最后,我们展示了我们的检测器的定性结果。论文附录中提供了更多的分析和可视化。
(Ⅰ)和最新方法比较
给定一个包含N个点和XYZ坐标的输入点云,一个主干网络(使用PointNet++实现),对这些点进行采样和学习深度特性,并输出M个点的子集。这些点的子集被视为种子点。每个种子通过投票模块独立地生成一个投票。然后将投票分组为集群,并由proposal模块处理,生成最终的提案。
SUN RGB-D [40]是用于三维场景理解单视图 RGB-D 数据集。该数据集包含37个类别,其中~5K用于训练,每一个图像都标记了完整带朝向的3D框。我们首先用提供的相机参数将深度图像转为点云作为网络的输入。我们在10个类别上遵循标准的评估方式。
ScanNetV2 [5]是一个带有丰富注释的3D重建网格的室内场景数据集。它包含从数百个房间搜集的~1.2K个训练样本,有18个物体类别的语义和实例分割标注。相比于 SUN RGB-D 的部分扫描,ScanNetV2场景更完整,涵盖更多对象更大区域。我们采样重建网格的顶点作为我们的输入点云。由于ScanNetV2不提供带朝向的3D框,我们改为预测正3D框。
方法的对比。我们比较了多种现有方法。深滑动形状(DSS)[42]和3D-SIS [12]均为3D CNN检测器,结合了几何形状和RGB特征,使用Faster R-CNN [37]的流程。与DSS、3D-SIS引入复杂的传感器融合方案相比(将RGB特征投影到3D体素),因此能够使用多个RGB视图来提高性能。2D驱动[20]和F-PointNet[34]是基于2D的3D检测器,通过检测图像来减少三维检测的搜索空间。梯度点云基于滑动窗口,使用设计的3D HoG特征的检测器。MRCNN 2D-3D直接将Mask-RCNN[11]的实例分割结果投影到3D获得边框估计。GSPN[54]是使用生成模型提出对象实例,其也基于PointNet ++骨干。
表1 SUN RGB-D val数据集上的3D目标检测结果
结果如表1和表2所示。在SUN RGB-D和ScanNet两个数据集中,VoteNet的性能都优于先前的方法,分别增加了3.7和18.4mAP。表1表明,当类别是训练样本最多的“椅子”时,我们的方法比以前的最优方法提高11AP。值得注意的是,我们仅使用几何信息就实现了这样的提升,而他们除点云外还使用RGB图像。表2表明,仅使用几何输入时,我们的方法显著优于基于3D CNN的3D-SIS方法,超过了20AP。
表2 ScanNetV2 val数据集上的3D目标检测结果
(Ⅱ)分析实验
投票好还是不投票好呢?我们采用了一个简单的基线网络,称之为 BoxNet,它直接从采样的场景点提出检测框,而不需要投票。BoxNet具有与VoteNet相同的主干,但它不采用投票机制,而是直接从种子点生成框。
表3 VoteNet和no-vote基线的比较
那么,投票在哪些方面有帮助呢?我们认为,由于在稀疏的3D点云中,现有的场景点往往远离目标中心点,直接的proposal可能置信度较低或不准确。投票让这些低置信度的点更接近,并允许通过聚合来强化它们的假设。在图3中,我们在一个典型的ScanNetV2场景中演示了这种现象。从图中可以看出,与BoxNet(图左)相比,VoteNet(图右)提供了更广泛的 “好” 种子点的覆盖范围,显示了投票带来的稳健性。
图3 投票有助于增加检测上下文,从而增加了准确检测的可能性
图4 当目标点远离目标中心的情况下,投票更有帮助
图6和图7分别展示了 ScanNet 和 SUN RGB-D 场景中 VoteNet 检测结果的几个代表性例子。可以看出,场景是非常多样化的,并提出了多种挑战,包括杂乱,噪声,扫描的伪像等。尽管有这些挑战,我们的网络仍显示出相当强大的结果。
例如,图6展示了如何在顶部场景中正确地检测到绝大多数椅子。我们的方法能够很好地区分左下角场景中连起来的沙发椅和沙发;并预测了右下角那张不完整的、杂乱无章的桌子的完整边界框。
图6 ScanNetV2中3D目标检测的定性结果。左:VoteNet 的结果,右: ground-truth
图7 SUN RGB-D中3D目标检测的定性结果。(从左到右):场景的图像,VoteNet的3D对象检测,以及ground-truth注释
6 结论
在这项工作中,我们介绍了VoteNet:一个简单但强大的3D对象检测模型,受到霍夫投票的启发。该网络学习直接从点云向目标质心投票,并学会通过它们的特性和局部几何信息来聚合投票,以生成高质量的 object proposals。该模型仅使用3D点云,与之前使用深度和彩色图像的方法相比,有了显著的改进。
在未来的工作中,我们将探索如何将RGB图像纳入这个检测框架,并在下游应用(如3D实例分割) 汇总利用我们的检测器。我们相信霍夫投票和深度学习的协同作用可以推广到更多的应用领域,如 6D 姿态估计、基于模板的检测等,并期待在这方面看到更多的研究。



 广告
广告 



最新资讯
-
奇石乐持续投资增长型市场,2025年业绩保持
2026-03-13 15:54
-
国际标准《商用车辆 牵引车与挂车之间的电
2026-03-13 13:51
-
比亚迪弗迪电池CEO何龙:二代刀片电池在不
2026-03-13 13:50
-
思看科技AM-CELL C 自动化光学3D检测系统上
2026-03-13 10:40
-
《汽车隔声性能测量与评价方法 第2部分:消
2026-03-12 13:53
