




 广告
广告





















































基于大模型的仿真系统研究一——三维重建大模型

一 基于大模型的仿真系统框架
传统的仿真测试验证普遍基于场景,而场景的构建主要由道路和场景编辑器来人工搭建静态场景和动态场景,这种方式费时费力,而且也大大限制了场景要素组合的丰富化。针对此痛点问题,赛目推出了基于大模型的仿真系统,利用机器学习、深度学习等人工智能技术,不仅推出自动标注大模型、多模态检测大模型和场景生成大模型等模块,并且引入三维重建大模型加强渲染画面真实性。
通过上述模块,赛目的路采场景转换系统实现了以传感器原始数据或者目标集数据为输入,通过感知融合、场景提取和生成等功能,输出仿真测试所需的静态路网和动态场景进行仿真,大大提高了仿真测试的效率。
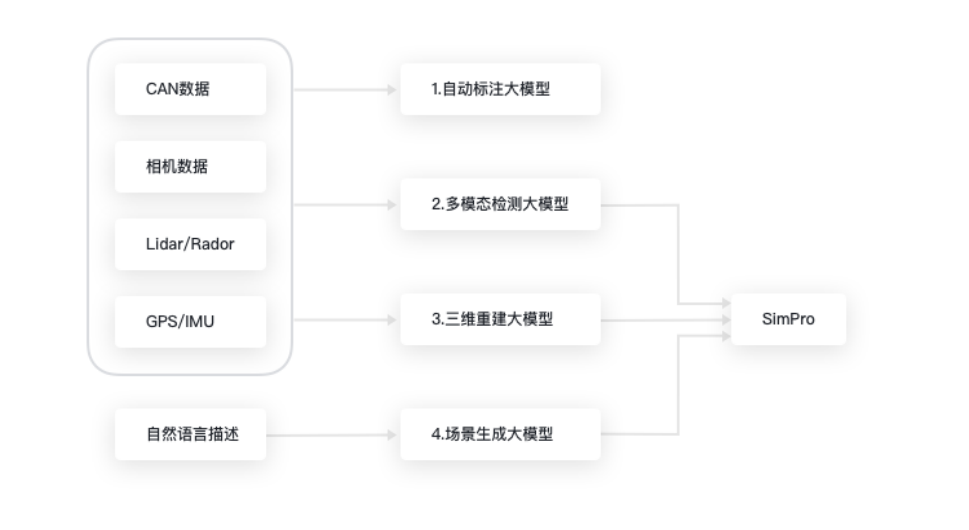
图:基于大模型的仿真系统框架
二 三维重建大模型
本文首先介绍三维重建大模型。
三维重建是指根据单视图或者多视图重建三维信息、构建三维模型的过程。传统的计算机图形学的核心通过复杂的物理模型求解渲染方程。需要的不仅仅是场景中物体的几何和材质信息、相机的内外参信息,更需要复杂的光照模型来模拟自然光照的影响。
上述工作的重大突破来自Ben Mildenhall等人于2020发表的神经辐射场(NeRF),根据对同一物体不同观察视角的多张图像,通过隐式的编码表示场景实现三维重建的过程,利用体渲染生成新视角图像。
NeRF训练渲染流程可以总结如下:
1. 对于给定的相机光线,在光线上进行采样,对采样点的空间坐标及观察方向进行编码,用深度复杂网络存获得辐射场信息;
2. 辐射场输出空间点的颜色和密度;
3. 根据2的输出用体素渲染方程获得生成视角图片;
4. 在训练阶段与原视角图片计算损失更新网络。
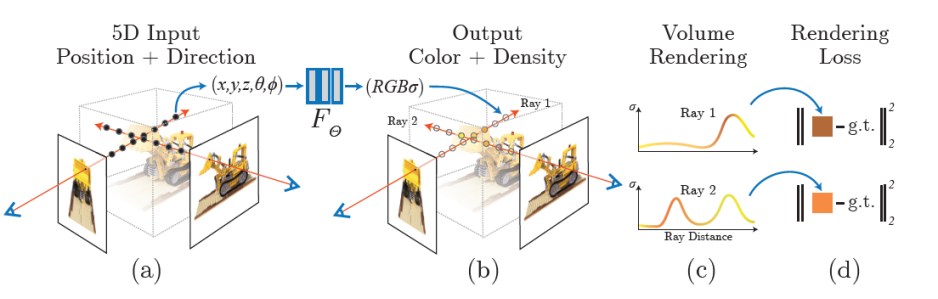
图:NeRF训练管线[1]
下图表示了辐射场的网络结构,其中PE表示位置编码,x为三维坐标点,d为观察方向,MLP为多层感知机,ReLU和Sigmoid分别为不同激活函数。辐射场网络的输入是空间坐标及方差方向,输出为对应的颜色和密度值传递至体渲染模块。
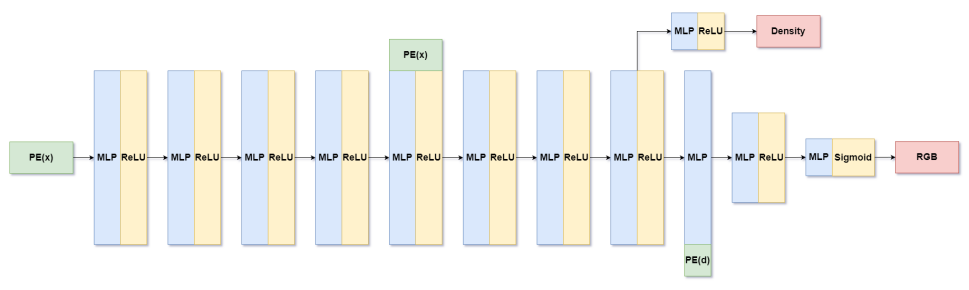
图:NeRF网络结构
体渲染主要为解决云、烟、果冻等非刚性物体进行渲染建模,将其抽象成一团粒子群,表现了光线穿过时光子和粒子交互的过程,产生的辐亮度的变化。其物理过程包括吸收、外散射、内散射、放射。忽略背景光的影响,体渲染方程为:
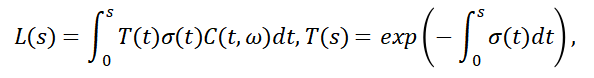

上述方法主要针对室内小型场景进行三维重建,对于户外场景、特别是自驾场景还有许多优化的空间,相关内容将在下节讨论。
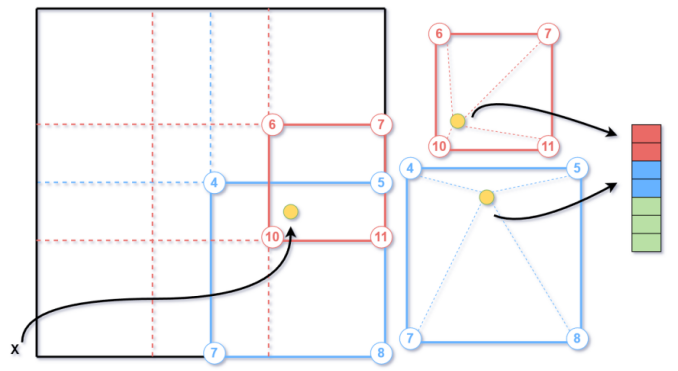
三 三维重建大模型-挑战和对应
对于自驾场景,上述baseline方法面临的挑战包括:
1. 训练和渲染速度:baseline方法需要花费数小时、甚至数天进行训练和生成,这对于仿真来说是难以接受的,同样不利于算法的迭代优化;
2. 生成画质清晰度:自驾场景包括了静态路网、动态环境参与者、背景建筑物、天空等等,需要同时将远景与近景清晰地渲染生成是一个极大的挑战;
3. 算法训练的过拟合现象:与baseline对同一物体360°环视图像获取不同,路采车辆一般沿着固定采集路线前进,对于同一物体的信息收集不够充沛,影响最终的渲染质量。
4. 动态物体的添加和删除:利用三维重建大模型能够获得不同主车视角的成像结果,但是对于测试场景生成需要灵活地控制环境参与者,因此需要模型能够自由地对物体进行添加和删除。
基于上述问题,我们提出了下述的研究路线。
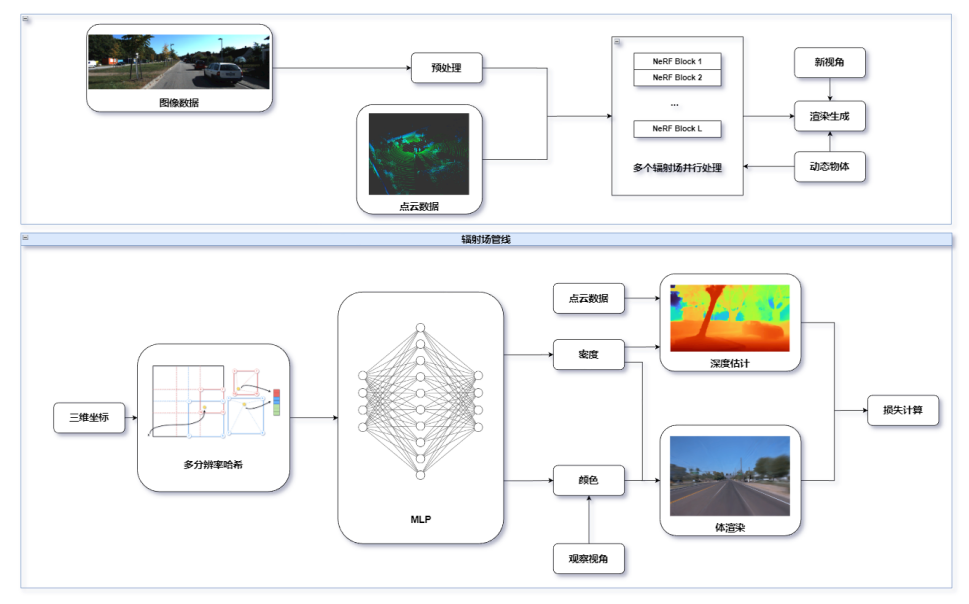
图:三维重建技术路线
对于无边界场景,由于可视范围变大的原因通过NDC坐标变化后的采样过程会将近景采样稀疏化,影响最终成像质量导致物体模糊,保持近距离坐标不变,远距离坐标作非线性转换是一种解决思路。坐标转换形式包括了[2-3]:
1. 半径为r的球面内保持坐标不变,球面外坐标以单位向量以及逆半径重新定义,具体如下
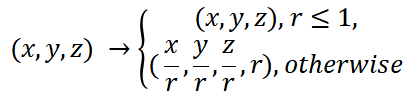
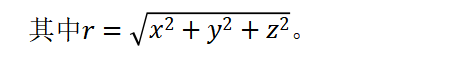

对于[0,1]标准化坐标系内的空间坐标点图片,通过下述方法确定其在不同分辨率下的相邻体素坐标:图片,图片和图片分别为下取整和上取整。然后利用线性插值法获得相应分辨率下的特征,输入至多层感知机中进行训练。特征栅格主要流程如下。
通过上述三维重建大模型方法,可以在自动驾驶仿真领域提升模型的训练和渲染速度、重建画质的清晰度、辐射场中物体深度与表面的准确度等等,同时能够动态添加环境车、行人等交通参与者进行场景泛化,实现更灵活的场景生成需求。
参考文献
[1] Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." Communications of the ACM 65.1 (2021): 99-106.
[2] Zhang, Kai, et al. "Nerf++: Analyzing and improving neural radiance fields." arXiv preprint arXiv:2010.07492 (2020).
[3] Barron, Jonathan T., et al. "Mip-nerf 360: Unbounded anti-aliased neural radiance fields." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[4] Müller, Thomas, et al. "Instant neural graphics primitives with a multiresolution hash encoding." ACM Transactions on Graphics (ToG) 41.4 (2022): 1-15.



 广告
广告 



最新资讯
-
东扬精测|CLNB 2026 苏州|世界顶尖的测试
2026-04-03 09:48
-
EA-BIM 20005多通道电池阻抗测试仪如何赋能
2026-04-03 09:46
-
自动泊车测试进入厘米级时代——从最新测试
2026-04-03 09:10
-
真正决定城市体验的,不是硬件,而是控制系
2026-04-02 14:26
-
LabVIEW传奇工程师亲临现场,NI测试测量技
2026-04-02 14:24
