




 广告
广告





















































UniFormer:用统一多视角融合Transformer构建时空BEV表征

arXiv论文“UniFormer: Unified Multi-view Fusion Transformer for Spatial-Temporal Representation in Bird’s-Eye-View“,2022年7月上传,浙江大学、大疆公司和上海AI实验室的工作。

BEV表示是一种基于空域融合的自主驾驶感知形式。此外,时域融合也被引入到BEV表示中,并取得了巨大的成功。这项工作提出一种方法,将空间和时间融合统一起来,并将它们合并到一个统一的数学形式中。统一融合不仅为BEV融合提供了新的视角,而且带来了新的能力。通过提出的统一时空融合,可以支持传统BEV方法难以实现的远距离融合。
此外,BEV融合是时间自适应的,时域融合的权重是可学习的。相比之下,传统方法主要使用固定权重和等权重进行时域融合。并且,所提出的统一融合可以避免传统BEV融合方法中的信息丢失,并充分利用特征。
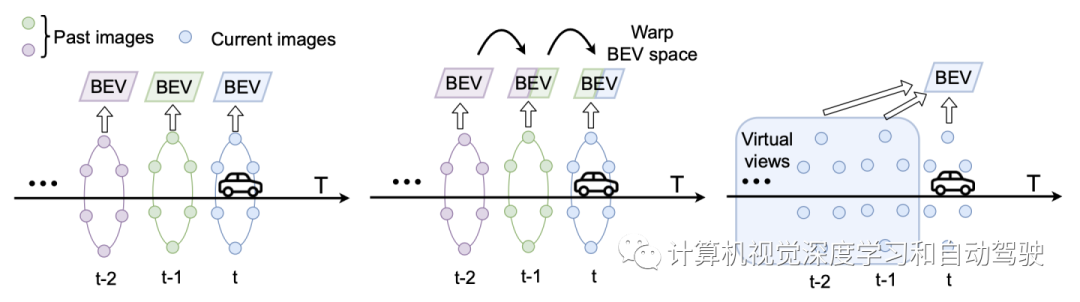
如图介绍BEV时域融合的方法:从左到右,无时域融合、基于warp的时域融合和提出的统一多视图融合。对于无时域融合的方法,仅在当前时间步长用周围图像预测BEV空间;基于warp的时域融合将上一时间步的BEV空间warp,是一种串行融合方法;统一的多视图融合,是一种并行方法,可以支持远距离融合。
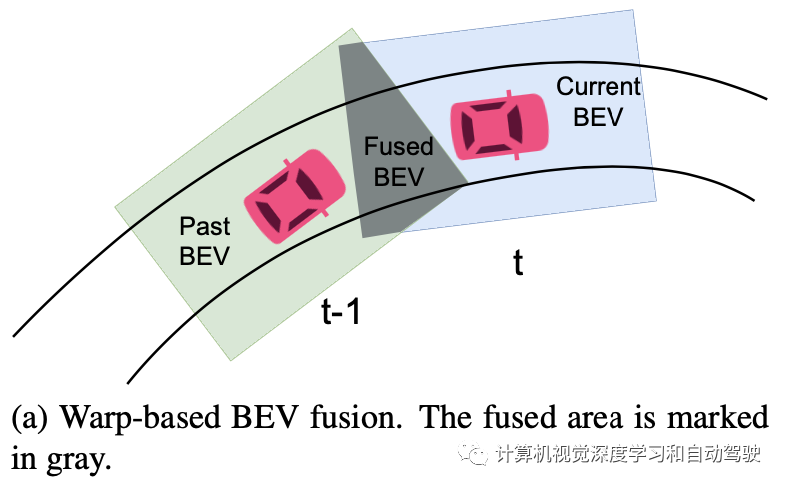
传统的BEV时域融合是基于warp的融合,如图a所示:基于warp的融合基于不同时间步长的自运动来warp过去的BEV特征和信息;由于所有特征在warp之前已经组织在预定义的自车BEV空间中,因此该过程将丢失信息。
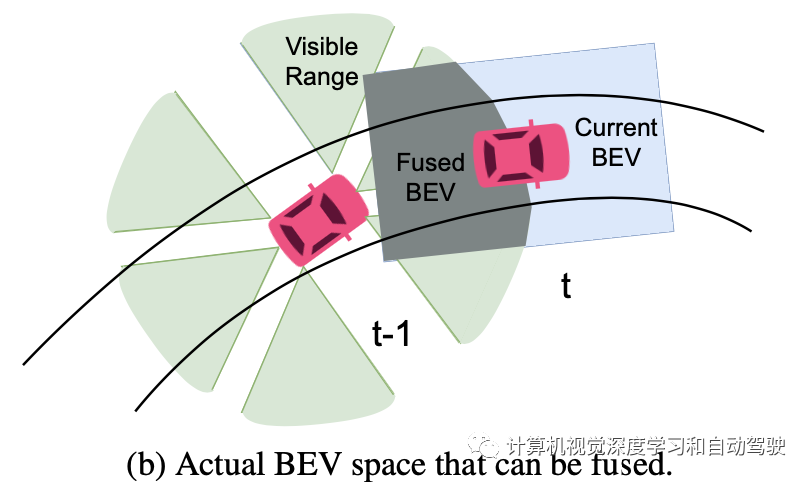
摄像机的实际可见范围远大于BEV空间的可见范围。例如,对于典型的摄像机来说,100m是一个非常小的可见范围,而大多数BEV范围被定义为不超过52m。通过这种方式,可以获得比简单warpBEV空间更好的BEV时间融合,如图b所示。
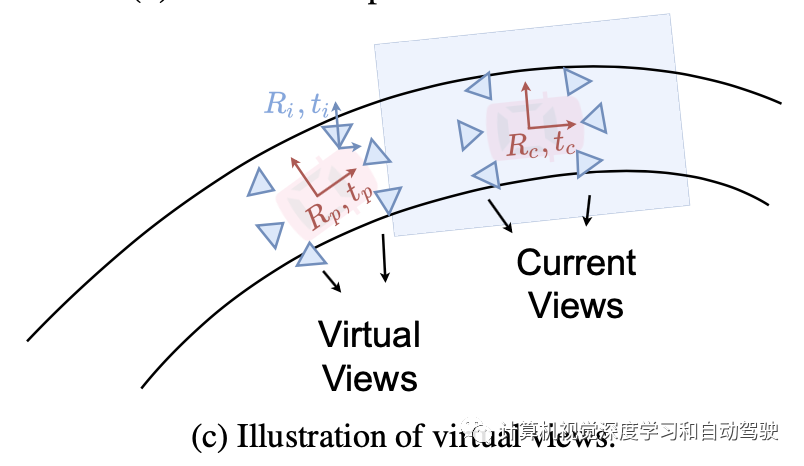
为了实现更好的时域融合,提出了一个概念,虚拟视图(virtual view),如图c所示:虚拟视图定义为当前时间步不存在的传感器视图,这些过去的视图根据自车BEV空间旋转和转换,就像实际存在于当前时间步一样。
如图是BEV融合的模型框架:该网络由主干网、统一多视图融合transformer和分割头三部分组成。
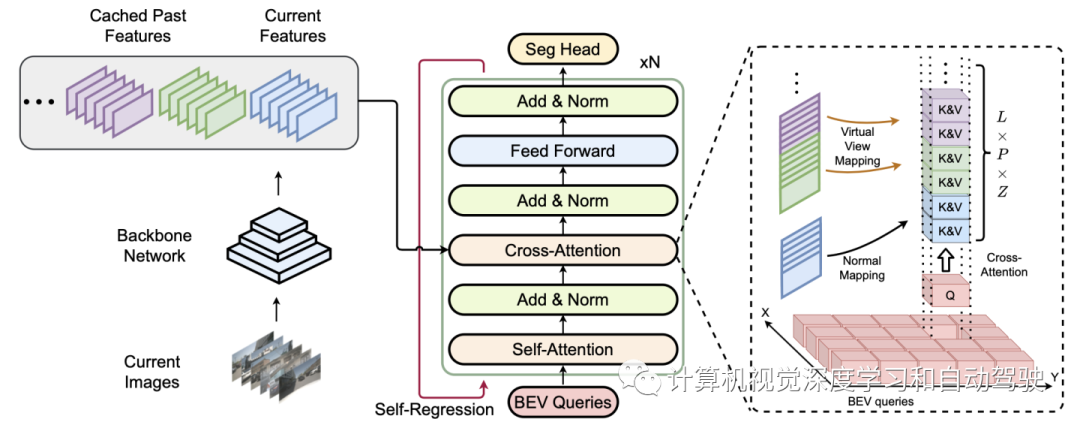
最重要的模块是用于统一多视图时空融合的交叉注意。在统一多视图融合的帮助下,所有时空特征可以映射到同一个自车BEV空间。交叉注意模块的目标是融合和集成映射的时空BEV空间特征。
通过这种方式,用BEV query Q来迭代BEV空间不同位置的特征、时间步、多尺度级和采样高度。可以以统一的方式直接检索来自任何地点和时间的信息,而不会造成任何损失。这种设计还使得远距离融合成为可能,因为无论多久以前的特征,都可以被直接访问,也支持自适应时域融合。
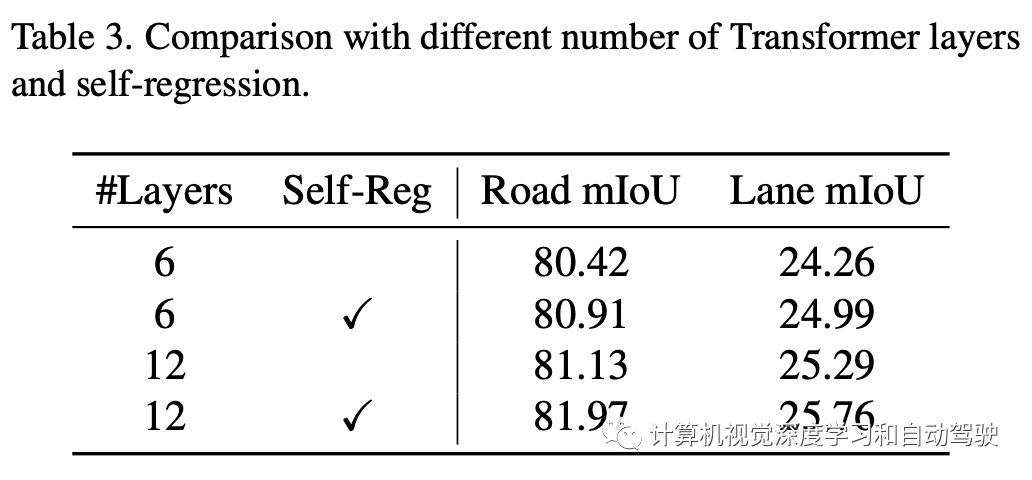
最后一个主要部分是自回归机制。将Transformer的输出与BEV query连接起来作为新输入,并重新运行Transformer获得最终特征。BEVFormer将warp的先前BEV特征与自注意模块之前的BEV query连接起来,实现时域融合。对Transformer的第一次运行,只需将BEV query加倍并叠加做为输入。
在BEVFormer中,warp的BEV特征和BEV query的叠加带来了时域融合,这是性能提高的根本原因。这项工作中,BEV特征和query的连接隐含地加深和加倍了transformer的层数。由于warp的BEV特征已经在之前的时间步让transformer处理,因此叠加视为两个连续transformer的嫁接。这样,无warp的简单自回归可以获得与BEVFormer类似的性能增益。
分割头是ERFNet。
ResNet50、Swin Tiny和VoVNet作为主干网。ResNet50和SWN主干从ImageNet预训练初始化,VoVNet主干从DD3D初始化。Transformer的默认层数设置为12。对于ResNet50和Swin,输入图像分辨率设置为1600×900。
对于VoVNet,用1408×512的图像大小。训练用AdamW优化器,学习速率为2e-4,权重衰减为1e-4。主干的学习速率降低了10倍。批量大小设置为每个GPU 1个,模型用8个GPU训练24个epoch。在第20个epoch,学习率降低了10倍。多尺度特征的数量设置为L=4,先前时间步长的默认数量设置为P=6,采样高度的数量设置为Z=4。高度范围为(−5米,3米],其中stride是2米。
对于100米×100米设置,用50×50 BEV query来表示整个BEV空间,然后将结果上采样4倍去匹配BEV分辨率。对于60米×30米设置,用100×50 BEV query,其上采样与100米×100米设置类似。对于160米×100米设置,用80×50 BEV query,然后向上采样8x去匹配分辨率。用交叉熵(CE)损失在两种设置下进行训练。
对于类不平衡问题,背景类的损失权重默认设置为0.4。由于100米×100米设置中的道路类别是多边形区域,没有类别不平衡问题,因此道路背景类别的损失权重设置为1.0。
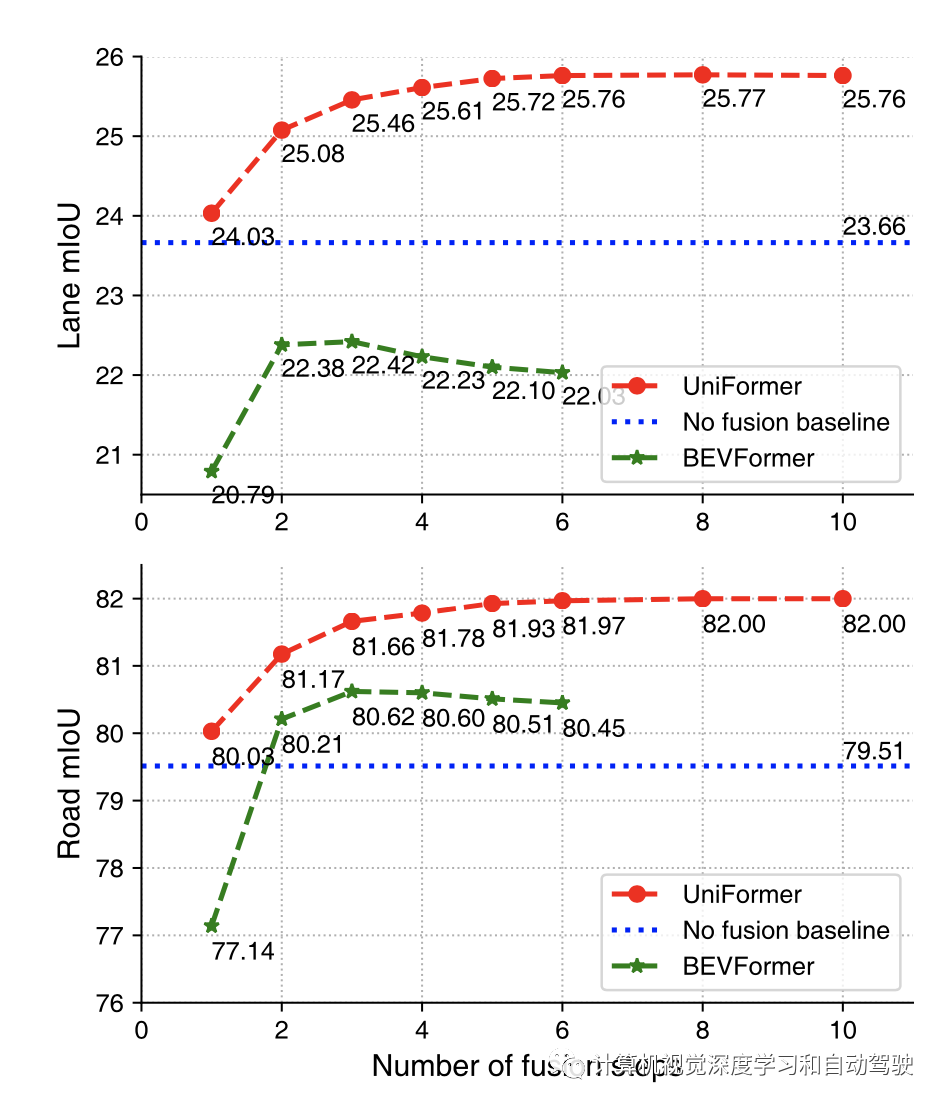
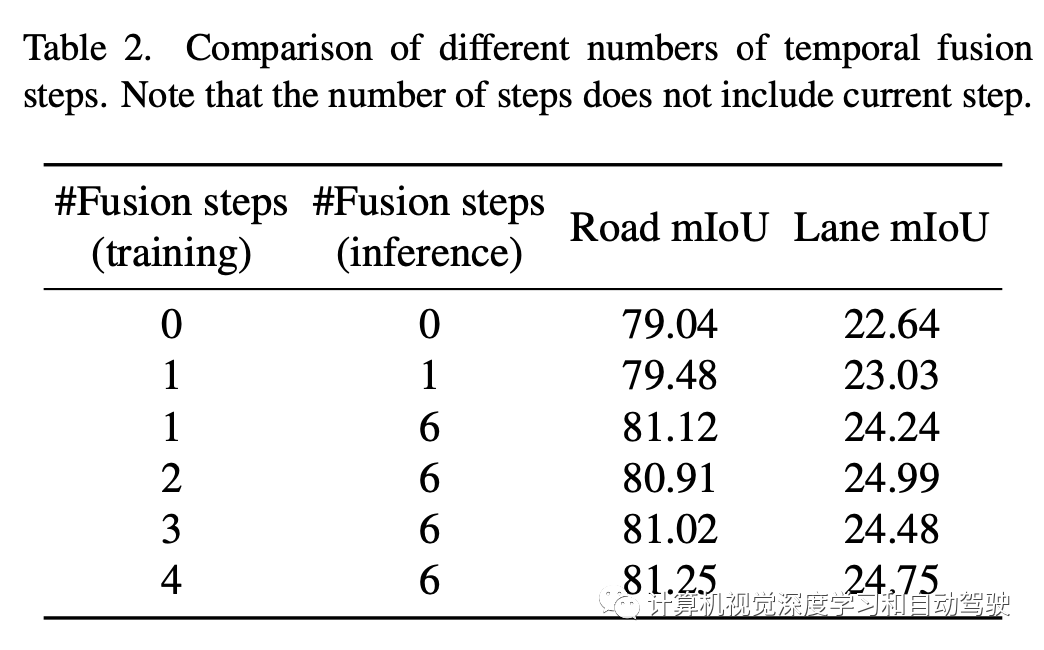
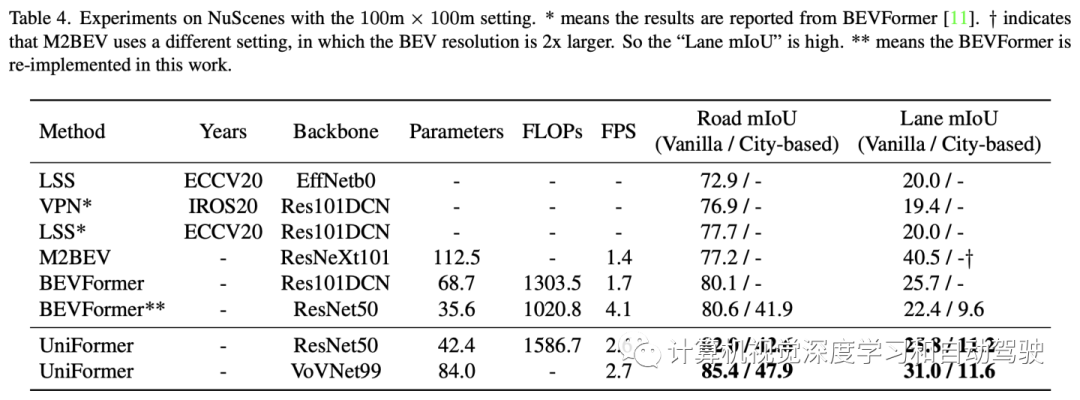
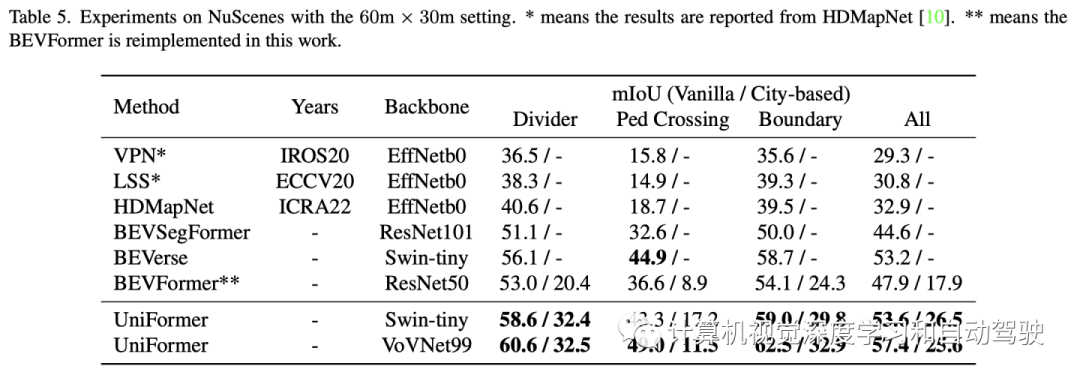
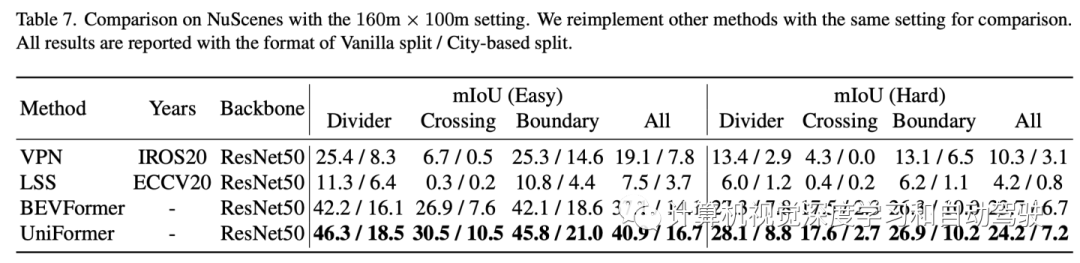
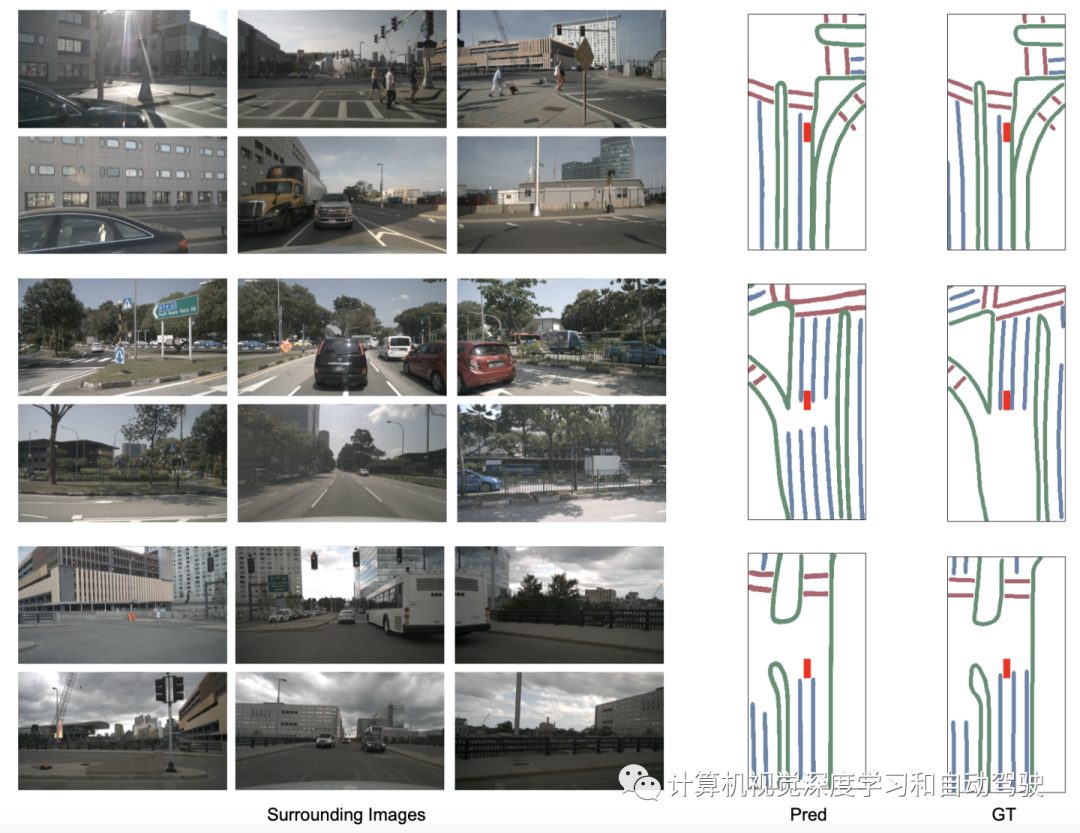
实验结果如下:
- 下一篇:10问新能源汽车800V绝缘设计
- 上一篇:如何设计提高电芯的容量密度?



 广告
广告 



最新资讯
-
使用 HEADlab 测量电流
2026-01-23 17:13
-
奇石乐持续推进全球碳中和战略
2026-01-23 16:47
-
吉利汽车,新公司落户湖北!
2026-01-23 16:12
-
直播|车载光通信技术路线及测试挑战
2026-01-23 13:05
-
重磅!工信部明确新车准入须开展30000km可
2026-01-23 13:05
