




 广告
广告





















































综述-基于深度学习的计算机视觉方法用于复杂交通环境感知

近年来,计算机视觉在智能交通系统(ITS)和自动驾驶(AD)中的应用逐渐转向深度神经网络架构。数据挑战与训练数据的收集和标记及其与现实世界条件的相关性、数据集固有的偏差、需要处理的大量数据以及隐私问题有关。深度学习(DL)模型对于嵌入式硬件的实时处理来说通常过于复杂,缺乏可解释性和可推广性,很难在现实环境中进行测试。复杂的城市交通环境具有不规则的照明和遮挡,监控摄像头可以安装在不同的角度,收集中的灰尘,在风中的晃动,交通条件高度异质,在拥挤的场景中违反规则和复杂的交互。受到这些问题困扰的一些代表性应用是交通流估计、拥堵检测、自动驾驶感知、车辆交互和用于实际部署的边缘计算。
如图是各种应用及其面临的挑战:
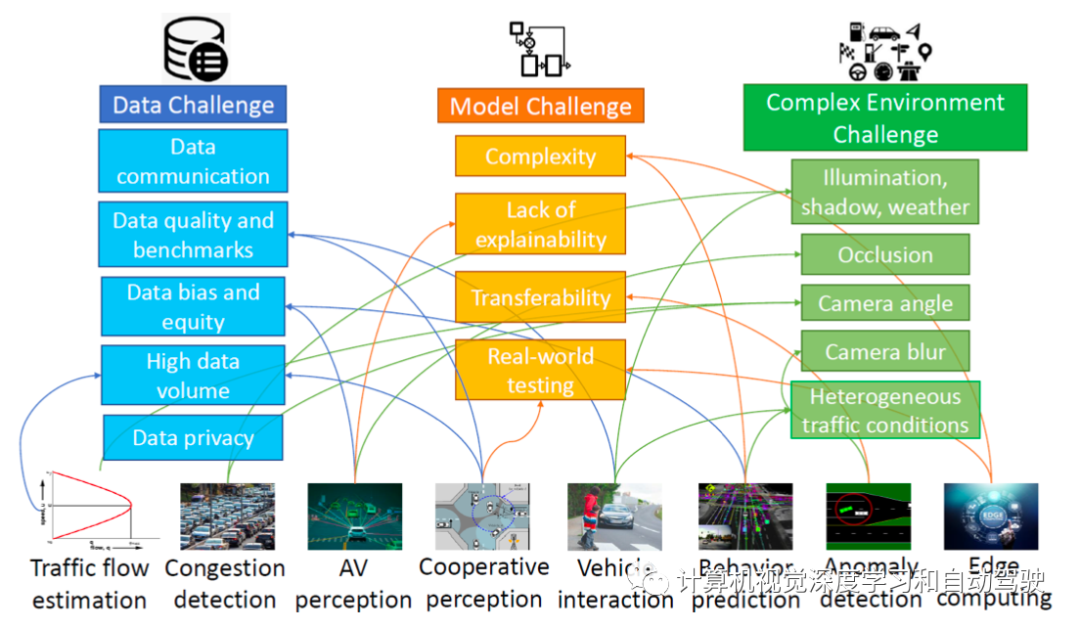
数据通信实践中,单个基于摄像头的深度学习任务通常需要在交通管理中心(TMC)的摄像头和云服务器之间进行数据通信。视频数据量很大,这可能导致潜在的数据通信问题,如传输延迟和数据包丢失。在协作式摄像机传感环境中,不仅与服务器进行数据通信,而且不同传感器之间也进行数据通信。因此,另外两个问题是多传感器标定和数据同步。
协作环境中的标定旨在确定传感器之间的透视转换,以便能够在给定帧合并来自多个视图的采集数据。这项任务在多用户环境中非常具有挑战性,因为传感器之间的变换矩阵随车辆的移动而不断变化。在协作环境中,标定依赖于背景图像元素的同步,以确定静态或移动传感器之间的转换。存在多个同步破坏源,例如时钟之间的偏移或可变通信延迟。虽然时钟可能是同步的,但很难确保在同一时刻触发数据采集,这增加了合并所采集数据的不确定性。同样,不同的采样率需要在采集或预测数据之间进行插值,这也增加了不确定性。
交通摄像头广泛部署在道路和车辆上。TMC不断收集网络范围内的交通摄像头数据,这些数据对各种ITS应用(如事件识别和车辆检测)都很有价值。然而,标记的训练数据远不如未标记的数据常见。随着图形逼真度和模拟物理模型变得越来越有真实感,许多应用程序缺少标注数据集的问题正慢慢被合成数据解决。
除了真实的外观,模拟场景不需要手动标记,因为标签已经由模拟生成,并且可以支持各种照明、视点和车辆行为。2020年AI城市挑战赛车辆重识别获胜者利用混合数据集,通过从真实世界数据中生成示例并添加其他模拟视图和环境,显著提高了性能。然而,如果用合成数据,在真实世界的应用仍然需要额外的学习过程,例如域自适应。低保真度模拟数据用于训练具有域随机化的迁移学习,用于真实世界目标检测器。
缺乏高质量的碰撞和接近碰撞数据通常被认为是一个实际的限制。更多的碰撞数据将更新AD的注意导引,使其能够捕捉长期碰撞特征,从而提高碰撞风险评估。故障或限量的传感器、有限的计算资源以及对任何驾驶场景的可推广性是当前实际部署的障碍。其中一些问题可以通过传感器融合、车联网(IoV)和边缘计算来解决。
尽管当前的车辆检测算法在平衡数据集上表现良好,但在面对不平衡数据集时,在尾部类别上的性能下降。在现实世界场景中,数据往往遵循Zipfian分布,其中大量尾部类别的样本数很少。在长尾数据集中,少数头部类(频繁出现类)贡献了大部分训练样本,而尾部类(罕见出现类)的代表性不足。大多数使用此类数据训练的DL模型将长尾训练数据的经验风险降至最低,并且偏向于头部类别。一些方法,如数据重采样和损失重加权,可以补偿不足的类别。然而,他们需要根据类别频率先验知识将类别划分为几个组。头尾类之间的这种硬性划分带来了两个问题:相邻类别之间的训练不一致,以及对罕见类别缺乏辨别力。
一般的目标检测器可以用迁移学习来改进,此外仅从训练集来看,模型偏差可能并不明显,需要解释性方法来解决这个问题。
视觉数据占互联网流量的90%以上,视频传输、计算和存储在ITS和AV领域面临着越来越大的挑战。通过交通摄像头网络或车联网(IoV)网络,来自路边和车载传感器的大量交通和车辆视频数据构成了无法通过设备解决的计算和带宽瓶颈。由于网联车或自动驾驶车的许多应用依赖于DL,因此车辆-云架构正在成为一种有效的分布式计算技术。通过集成路侧单元(RSU),这些边缘节点可以更快地处理并提供低通信延迟。
隐私问题是一个重要的人为因素,在ITS应用程序的设计和运行中不容忽视。观察和跟踪大量的行人和车辆信息会导致ITS环境中的安全和隐私问题。例如,无人机能够(通过机载摄像机)收集交通数据。然而,隐私问题限制了它们成为ITS传感器网络的常规部分。视频监控系统不断收集人脸和车牌。个人隐私交换的是监控提供的安全或安全服务。如果发送或存储原始视频数据,实际部署的系统可能需要实时识别人脸和车牌。理想情况下,任何处理都将在本地边缘单元完成,限制私人信息的传播。很难保证完全匿名,例如,通过与其他信息(甚至是模糊的车牌)相关,可以追踪一辆罕见车型的车主。
如图是数据挑战:

DL计算机视觉模型在神经网络结构和训练过程方面具有很高的复杂性。许多DL模型设计用于在高性能云中心或AI工作站上运行,而一个好的模型需要数周或数月的训练以及GPU或TPU驱动的高功耗。
在ITS和AV领域的应用中,出于功能和交通安全的考虑,许多应用都需要实时或近实时操作。DL模型的复杂性增加了实时应用中的训练和推理成本;特别是,ITS和AV的趋势是在更接近交通数据的大规模设备进行处理,例如,众包感知。
实时应用程序通常会进行一些修改,如调整视频大小以降低分辨率或模型量化和修剪,这可能会导致性能损失。为了满足效率和精度要求,在许多实际应用中需要降低DL方法的模型复杂性。例如,多尺度可变形注意已与视觉transformer神经网络一起用于目标检测,以实现高性能和快速收敛,从而加快训练和推理。
DNN在很大程度上被视为具有多处理层的黑盒子,其工作情况可以用统计数据进行检查,但学习的网络基于数百万或数十亿个参数,让分析极其困难。这意味着,行为本质上是不可预测的,而且对决策的解释很少。这也使自动驾驶等关键用例无法进行系统验证。
人们普遍认为,复杂的黑盒子是必需的,这一假设受到了挑战。最近的研究试图使DNN更易于解释。
对分布外(out-of-distribution)数据的泛化对人类来说是自然的,但对机器来说却具有挑战性,因为大多数学习算法都强烈依赖于测试数据分布的i.i.d.假设,而在实践中这常常因域迁移而遭破坏。域泛化旨在将模型推广到新领域,但不了解训练期间的目标分布。
大多数现有方法都属于域对齐(domain alignment)的范畴,其主要思想是最小化多个源域之间的差异,学习域不变表征。对源域漂移不变的特征也应该对任何未发现的目标域漂移鲁棒。数据增强是一种常见的做法,用于正则化机器学习模型的训练,避免过拟合并提高泛化能力,这对于过度参数化的DNN尤为重要。
神经网络中的视觉注意可用于突出一个决策中涉及的图像区域,并进行因果过滤以找到最相关的部分。
一般来说,DL方法容易出现欠描述;无论模型类型或应用如何,都会出现这种问题。虽然方法基准分数随模型复杂度和训练数据增加而提高,但使用真实世界的失真进行测试会导致较差且变化的性能,这依赖于用于初始化训练的随机种子。
实际实时处理系统需要在各种低成本硬件的内存和计算方面达到高效。方法包括参数修剪、网络量化、低秩因子分解和模型蒸馏。
行人和自行车使用者等弱势道路使用者(VRU)存在一个问题:可以非常快速地改变方向和速度,并与车辆不同地与交通环境交互。
在ITS中实际部署计算机视觉模型的一些主要障碍,是数据源的异质性、传感器硬件故障以及极端或异常传感情况。此外,最新一些框架(如基于边缘计算的框架)直接暴露了大量无线通信信号,为恶意行为者创造了越来越大的潜在攻击。已经开发了深度学习模型来检测这些攻击,但实时应用和在线学习仍然是积极研究的领域。
IoV面临着基本的实际问题,这是由于移动车辆在边缘节点上呈现可变的处理开销,而每辆车也可以同时运行许多边缘和云相关的应用程序。与自动驾驶汽车边缘计算相关的其他挑战包括,协作感知、协作决策和网络安全。攻击者可以用激光和明亮的红外光干扰摄像头和激光雷达,改变交通标志,并在通信通道重复攻击。
如图是模型挑战:
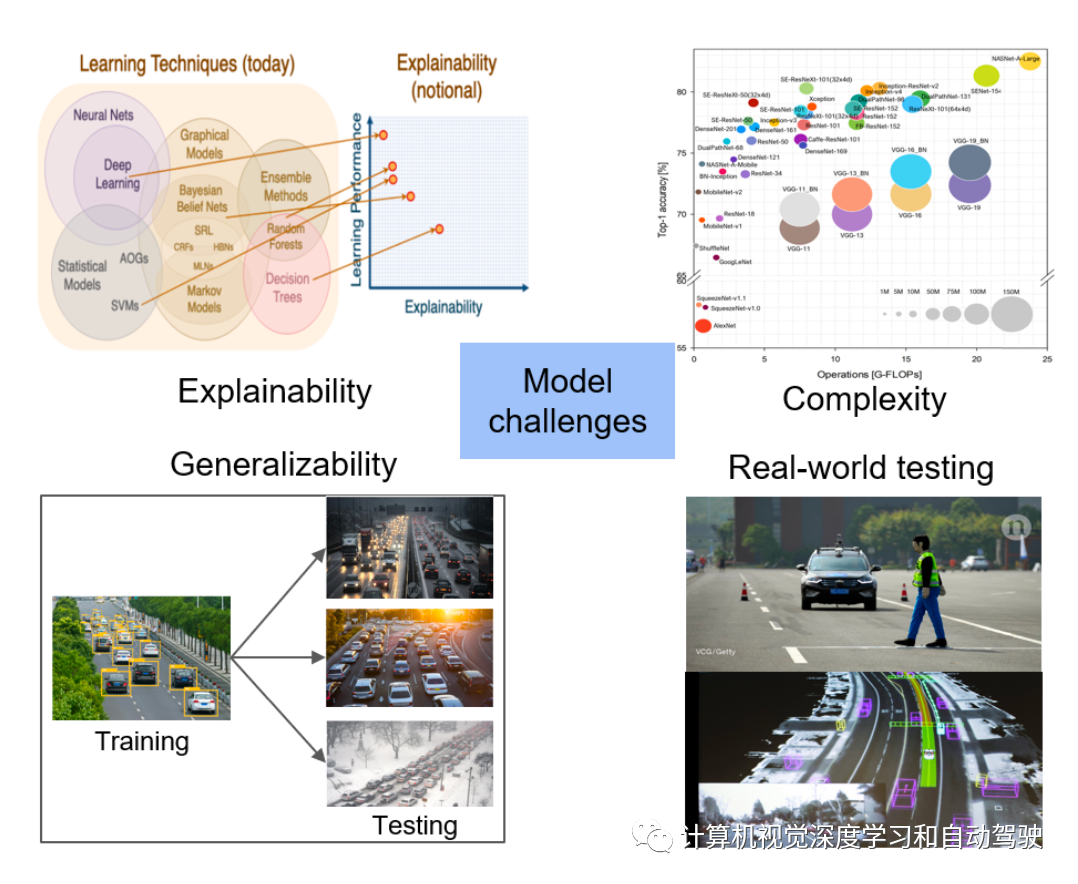
阴影、恶劣天气、背景-前景之间的相似性、现实世界中的强烈照明或不足照明等情况。众所周知,摄像头图像的外观受到不利天气条件的影响,如大雾、雨夹雪、暴风雪和沙尘暴。
[在恶劣的天气条件下,交通监控摄像头捕捉到的车辆会出现曝光不足、模糊和部分遮挡等问题。同时,出现在交通场景中的雨滴和雪花增加了算法提取车辆目标的难度。在夜间或在车辆朝着摄像头行驶的隧道中,由于远光眩光,场景可能被完全掩盖。
遮挡是最具挑战性的问题之一,其中由于另一个前景目标的遮挡,一个目标仅部分可见于摄像头或传感器。遮挡以多种形式存在,从部分遮挡到重遮挡。在AD中,这个目标可以被建筑物和灯柱等静态目标遮挡。诸如移动车辆或其他道路使用者之类的动态目标可能会彼此遮挡,例如人群。遮挡也是目标跟踪中的一个常见问题,因为一旦被跟踪车辆从视野中消失并再现,被视为不同的车辆,导致跟踪和轨迹信息不准确。
在交通基础设施的应用中,监控摄像机的多样性对基于有限视角摄像机视图训练的DL方法提出了挑战。早期对监控视频异常检测的调查得出结论,照明、摄像机角度、异质目标和缺乏真实世界数据集是主要挑战。用于稀疏和密集交通条件的方法是不同的,并且缺乏泛化性。在多视图视觉场景中,匹配不同视图中的目标是另一个主要问题,因为多视图ITS应用程序需要处理同时由不同摄像头捕获的图像数据。
监控摄像机受天气因素影响。水、灰尘和颗粒物质可能积聚在镜头上,导致图像质量下降。强风会导致摄像头抖动,导致整个图像的运动模糊。自动驾驶汽车上的前置摄像头也面临这一问题,因为昆虫会砸到玻璃上,导致摄像头视野中的盲点。具体而言,目标检测和分割算法受到极大影响,除非在模型中做好准备,否则错误检测可能会导致AD的严重安全问题,或者错过监视应用的重要事件。解决这一问题的一些方法包括使用退化图像进行训练、图像恢复预处理和微调预训练网络从退化图像中学习。
密集的城市交通场景充满了复杂的视觉元素,不仅在数量上,而且在各种不同的车辆及其交互中。汽车、公共汽车、自行车和行人在同一个十字路口的存在是自动导航和轨迹计算的一个重要问题。不同的大小、转弯半径、速度和驾驶员行为,被这些道路使用者之间的交互进一步加重。从DL的角度来看,很容易找到异构城市交通的视频,但标记真值非常耗时。模拟软件通常无法捕捉此类场景的复杂动态,尤其是在密集的城市中心出现的交通规则破坏行为。
如图是复杂交通环境的挑战:

应用
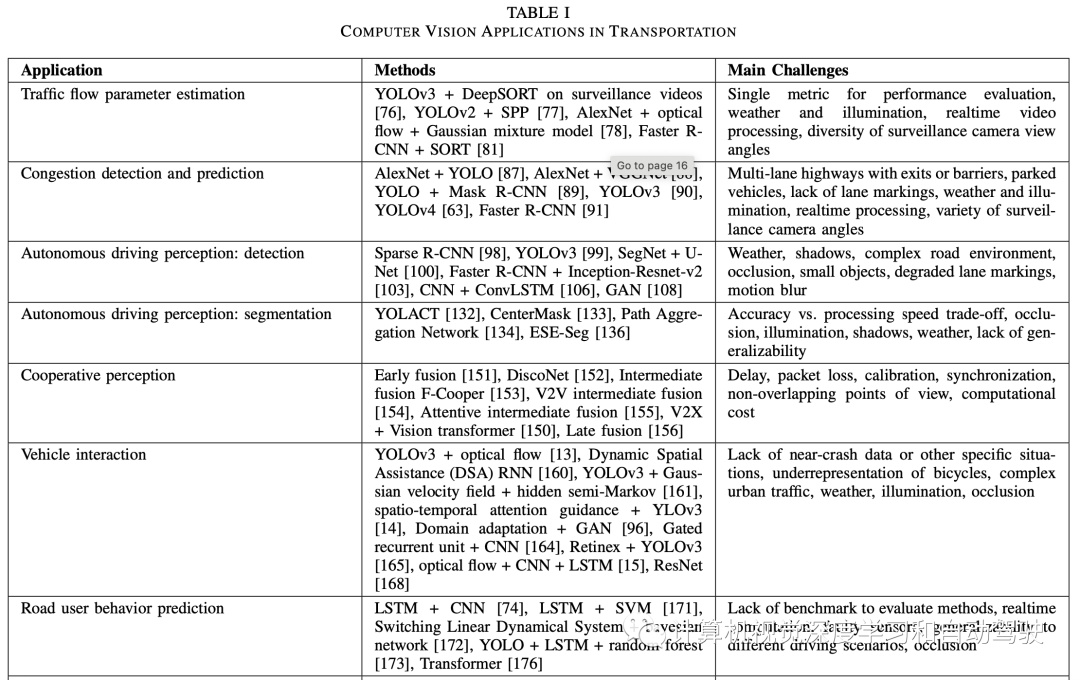
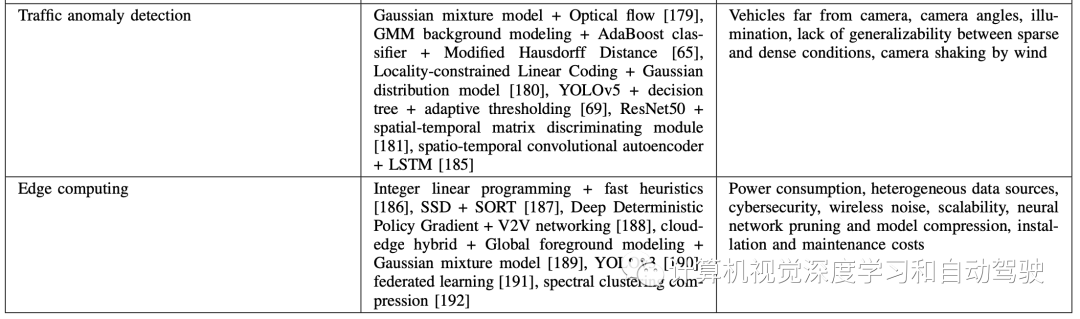
如表1
今后方向
来自arXiv2211.05120论文。



 广告
广告 



最新资讯
-
展会预告 | TCT亚洲展倒计时!思看科技五大
2026-03-10 20:50
-
整车性能测试体系:汽车试验工程的基本框架
2026-03-10 12:54
-
联合国法规R76对轻便摩托车前照灯远近光性
2026-03-10 12:15
-
联合国法规R75对摩托车与轻便摩托车气压轮
2026-03-10 12:14
-
联合国法规R74对L1类车辆灯光与光信号装置
2026-03-10 12:14
