




 广告
广告





















































CoRL 2022 | PolarBEV: 基于极坐标划分和表面高度估计的纯视觉非均匀BEV表示学习

摘要:鸟瞰图(Bird’s Eye View, BEV)表示可以隐式而优雅地将多视图信息进行统一表示,避免了耗时的多视图融合后处理操作,其对于自动驾驶中的环境感知具有很大的实用价值。在CoRL2022上,地平线-天津大学-华中科技大学联合发表了研究成果PolarBEV:基于极坐标划分和表面高度估计的纯视觉非均匀BEV表示学习。不同于基于矩形表示和深度估计的方案,PolarBEV提出将BEV空间沿着角度和半径进行栅格化,并结合迭代的高度估计来确定2D到3D的对应关系,极大地提升了BEV分割的精度和推理速度。
论文链接:https://arxiv.org/pdf/2207.01878.pdf
代码链接:https://github.com/SuperZ-Liu/PolarBEV

简介
本文提出了一个基于极坐标划分和表面高度估计的纯视觉非均匀BEV表示学习方法PolarBEV。相比于之前基于矩形表示和深度估计的方法[1],PolarBEV通过将BEV空间沿着角度和半径进行栅格化来得到非均匀划分的网格点,之后通过将每个网格点的向量映射分解为角度向量映射和半径向量映射来增强每个网格点的表征能力,最后通过迭代的高度估计来确定2D到3D的对应关系。在这一范式下,PolarBEV在Nuscenes[2]数据集语义分割和实例分割任务上的性能都超越了之前的方法,并且在2080Ti GPU上取得了实时的推理速度。
动机
非均匀表示相比均匀表示更有优势
对于自动驾驶来说,自车周围的感知结果相比于远处来说更重要,因此自车周围区域应该需要更高的分辨率。我们通过将BEV空间沿着角度和半径进行划分,从而得到一个距离相关的非均匀的网格分布-密集分布于自车周围,稀疏分布于远处。
对于均匀表示来说,大范围的BEV空间通常需要较多的网格点和更大的计算量。通过在半径上进行长尾不均匀的划分,可以实现以较小的计算成本覆盖较大的BEV空间。
因为相机近大远小的成像特点,相同角度不同距离的同一个物体在成像上应该具有相似外形、尺度不一的特点,而相同距离不同角度的同一物体在成像上应该具有相似尺度、不同外形的特点。通过将BEV空间沿着角度和半径进行划分,可以使得BEV表示和相机的这一成像特点相适应。此外,可以通过将每个网格点的向量映射分解为角度向量映射和半径向量映射来建模圆形BEV表示下每个网格点之间的关系,从而增强每个网格点的特征表示。
高度估计相比于深度估计更有优势
深度估计方法通常需要为每个像素点估计一个深度分布,而这通常限制了该类方法的推理速度。此外,深度的真实范围通常是[0,+∝),网络很难在如此大的解空间中估计出准确的深度。高度估计方法只需要为每个网格点隐式地估计一个高度,这可以极大地加速网络的推理速度,而且高度的估计也比深度的估计要简单的多。
方法
整体框架
PolarBEV的整体框架如图1所示,其总共包含三个部分:1)图像特征抽取部分 2)BEV空间栅格化和重组 3)迭代的表面高度估计和2D到3D的特征变换。
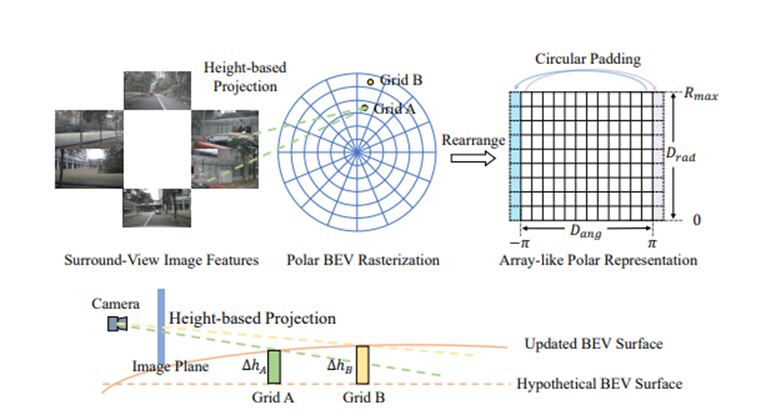
图1 PolarBEV整体框架示意图
极坐标栅格化和重组
本工作首先将BEV空间沿着角度和半径分别进行栅格化,得到
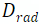
个半径划分和
个角度划分。为了便于后续的处理,该工作将栅格化后的网格点重组成
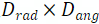
大小的矩形。如图一所示,因为在角度这一维上,
和
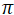
虽然表示相同角度,但是却被分割在矩形的两端,所以需要对重组后的矩形网格点做相应处理才能满足一般的卷积操作。这里,通过在角度这一维上使用循环填充来弥补该缺陷。
极坐标向量映射分解
对于每个角度为θ,半径为 的极坐标点,本工作将其对应的查询向量映射 分解为半径相关的
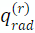
和角度相关的
,这一过程形式化表示为:
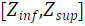
本工作通过该分解来建模圆形BEV表示下每个网格点之间的关系,从而增强每个网格点的特征表示。
迭代的表面高度估计和2D到3D的特征变换
为了确定图像和BEV之间的对应关系,本工作首先设置一个初始高度为
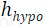
的假设表平面,然后根据每个查询向量映射 来迭代更新每个网格点 的对应高度:
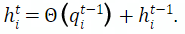
随后,本工作将 归一化到[0,1]范围,再缩放至目标高度范围
:
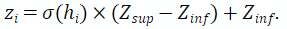
然后,本工作根据每个网格点 对应的极坐标
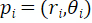
,构造出该网格点的三维齐次坐标 :
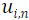
最后,本工作根据相机内参矩阵 和外参矩阵 将 投影到图像平面:
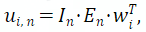
再根据投影点从图像特征中采样得到最终的BEV特征 :

其中
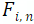
表示从
位置采样出的特征,
是一个用于掩码超出图像边缘的投影点的二值掩膜。
实验结果
语义分割结果
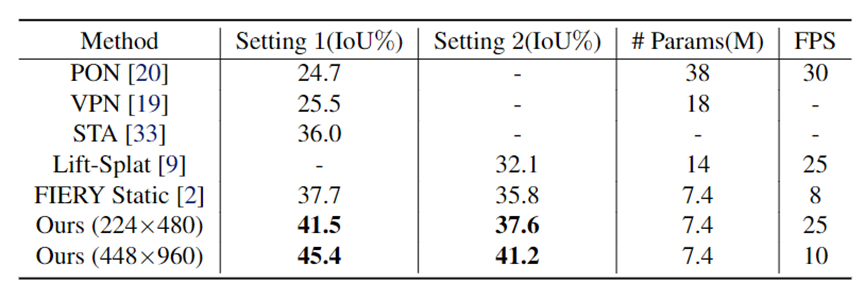
表1和表2分别展示了在不掩码不可见车辆和掩码不可见车辆两种情况下,PolarBEV和其他方法的结果对比。可以看出PolarBEV在使用相同输入分辨率 的设置下,不仅在精度上超过了FIERY Static[1],而且取得了实时的推理速度(25FPS,2080Ti)。
表1 不掩码不可见车辆的BEV语义分割结果
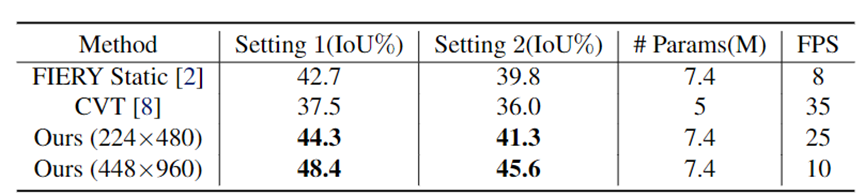
表2 掩码不可见车辆的BEV语义分割结果
实例分割结果
表3展示了PolarBEV相比于FIERY Static[1]在实例分割上的优势,可以看出PolarBEV主要在RQ指标上比FIERY Static高,说明PolarBEV能够更加准确的分类出不同实例。

表3 掩码不可见车辆的实力分割结果
消融实验
表4和表5分别验证了PolarBEV提出的圆形表示相比于矩形表示的优势、基于高度的特征变换相比于基于深度的特征变换的优势。
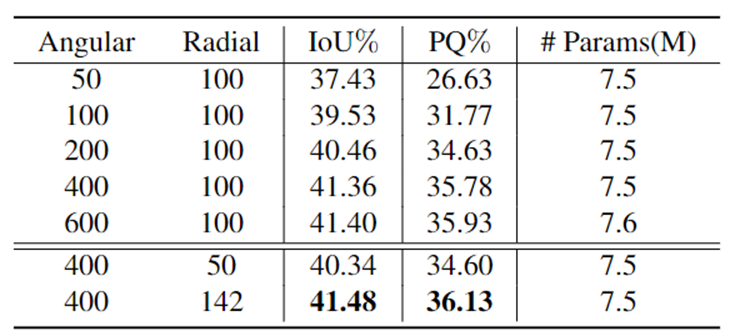
表4 矩形表示和圆形表示对比结果
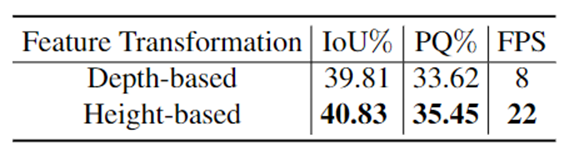
表5 基于深度和基于高度的对比结果
表6验证了PolarBEV提出的各个模块的有效性。在添加环卷积之后,模型在IoU和PQ指标上分别提升了0.33和1.03个点。在环卷积之后,添加向量映射分解(PED)可以使得模型在IoU和PQ指标上进一步提升0.55和0.36个点。

表6 各个模块的消融实验结果
表7验证了圆形BEV表示在分辨率上的消融实验。从该表可以看出无论是增大角度分辨率或是增大半径分辨率,模型的精度都有提升。
表7 圆形BEV表示在分辨率上的消融实验
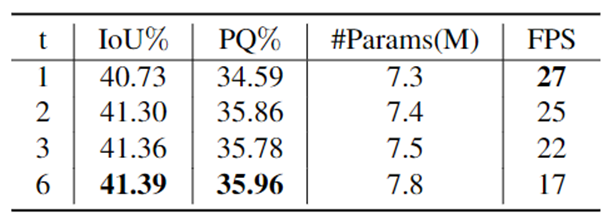
表8验证了迭代次数对模型精度的影响。从该表可以看出,随着迭代次数的增多,模型的精度越来越高。当迭代次数到达3或者6时,模型精度趋向饱和,但是FPS下降明显。
表8 迭代次数的消融实验
可视化结果
图2展示了PolarBEV在不同场景下的分割质量,可以看出PolarBEV即使在复杂环境中依然可以得到准确的分割结果。

图2 PolarBEV在不同场景下分割质量的可视化图
参考文献:
[1] Hu et al. FIERY: Future Instance Prediction in Bird's-Eye View From Surround Monocular Cameras. ICCV 2021.
[2] Caesar et al. nuscenes: A multimodal dataset for autonomous driving. CVPR 2020.
关于CoRL
CoRL的全称为Conference on Robot Learning,是一个以机器人技术和机器学习为主题的年度学术国际会议。自 2017 年首次举办以来,CoRL 已经成为机器人技术与机器学习交叉领域的全球顶级学术会议之一。大会针对机器人学习研究,涵盖了机器人技术、机器学习和控制等广泛主题,包括理论和应用各方面。



 广告
广告 



最新资讯
-
整车性能测试体系:汽车试验工程的基本框架
2026-03-10 12:54
-
联合国法规R76对轻便摩托车前照灯远近光性
2026-03-10 12:15
-
联合国法规R75对摩托车与轻便摩托车气压轮
2026-03-10 12:14
-
联合国法规R74对L1类车辆灯光与光信号装置
2026-03-10 12:14
-
联合国法规R73对货车侧面防护装置的工程化
2026-03-09 12:14
