




 广告
广告





















































技术丨基于数据挖掘的汽车耐候性预测算法

汽车在日常使用过程中,不可避免会受到太阳辐照、温度以及雨水等气候环境因素的破坏作用,而发生老化现象。对于耐候性设计不佳的汽车产品,其零部件往往会过早产生变形、变色、脱胶、开裂等老化失效问题,轻则影响消费者对对汽车品牌的认可度,重则会对汽车的行驶安全产生影响。汽车高分子部件的老化问题主要是受到环境应力的作用所导致,而汽车部件自身温度的变化正是影响其老化的一大关键要素。
本文过提取影响汽车部件温度变化的关键特征作为输入变量,以及把汽车部件表面温度作为输出变量,将琼海冬天和夏天各一个月的试验数据作为训练数据进行模型训练。训练好的模型可对汽车部件在全年气象条件下进行较为精准的预测,从而可以缩短试验时间。该研究对于利用少量的试验数据,预测汽车部件全年气象环境条件下表面温度变化具有一定的指导意义。
作者:李淮、顾泽波、张晓东、祁黎、陈心欣、赵雪茹
单位:中国电器科学研究院股份有限公司 工业产品环境适应性国家重点实验室
简介:李淮,工程师,主要研究方向为机器学习算法及汽车耐候性技术。
引言
为了提高汽车品质及车企形象,车企在研发汽车的过程中会对整车及部件进行自然暴露试验及整车强化腐蚀试验,用于验证汽车的耐候性设计以及材料的耐候性性能是否达标。对于整车强化腐蚀试验主要是考察汽车金属部件的抗腐蚀能力,依据QC/T732-2005标准进行,一般试验进行60~100个循环腐蚀量;而自然暴露试验主要是考察车身的金属及涂镀层的抗腐蚀能力以及非金属材料的抗老化能力,一般的试验周期为1-2年。试验后根据CSAE105-2019标准对整车的耐候性进行评价。
汽车高分子部件的老化问题主要是受到环境应力的作用所导致,而汽车部件自身温度的变化正是影响其老化的一大关键要素。虽然利用仿真技术可计算汽车整车的温度场,但是仿真计算需要预先准确设定各个部件的物理特性、热传导系数等参数,否则计算结果误差会特别大,在实际运用过程中具有一定的局限性。因此研究其它方法来预测汽车自然暴露时的温度变化对于汽车企业具有重要的意义。机器学习算法已在光伏、风电、高分子材料等诸多领域进行了大量的应用,它可以充分的挖掘数据间的内在规律,从而可以构建环境因素与汽车部件表面温度的关系模型,进行精准的预测。本文利用python软件构建机器学习模型,通过提取影响汽车部件温度变化的关键特征作为输入变量,以及把汽车部件表面温度作为输出变量,将琼海冬天和夏天各一个月的试验数据作为训练数据进行模型训练。训练好的模型可对汽车部件在全年气象条件下进行较为精准的预测,从而可以缩短试验时间。该研究对于利用少量的试验数据,预测汽车部件全年气象环境条件下表面温度变化具有一定的指导意义。

整车自然暴露试验介绍
根据GB/T40512-2021标准的要求,将汽车整车静置于琼海湿热自然暴露试验场1年。在汽车内外部重点关注的部件上安装各种传感器,连续实时监测汽车典型零部件表面温度、大气湿度、太阳辐照、风速、降雨量等环境参数,数据形式为每5min记录一次数据。试验车辆及传感器安装情况如图1所示。

图1 试验车辆及传感器安装点
特征工程
01特征数据选取
选取大气温湿度、大气压强、降雨量、太阳总辐照等14项数据作为比较数列,汽车部件(车顶、前保险杠中部、前挡水槽饰板)表面温度为参考数列,分别计算比较列与参考列的相关系数。斯皮尔曼相关系数计算方法为:
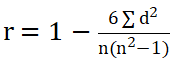
(1)式中:d—参考数列和比较数列的等级差数;n—序列个数。当斯皮尔曼相关系数大于0.6时,表明两列数据之间有较强的相关关系。斯皮尔曼相关性结果如图2所示。

图2 斯皮尔曼相关性系数选取相关系数绝对值大于0.6的气象参数做为特征参数,即大气温度、大气湿度、太阳辐照量、红外辐照量、紫外辐照量、可见光、直接辐照量、日照时数,共8个特征参数作为机器学习模型的输入参数;汽车部件(车顶、前保险杠中部、前挡水槽饰板)的表面温度分别作为模型输出参数,分别构建3个部件的温度预测模型。
02
数据归一化
在将数据带入机器学习模型之前,需要对输入参数进行归一化处理,使得各个特征参数的值在0~1之间。目的是为了防止特征参数的数量级差别较大而造成模型网络预测误差增大。数据归一化主要有两种形式,一种是“最大最小法”,即把所有数据转化成0~1之间的值,函数形式见公式2;另一种是“平均数方差法”,函数形式见公式3。其是移动数据分布,使得数据的平均值为0,标准差为1。
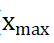
(2)式中:
—数列中的最小数值;
—数列中的最大数值。
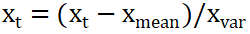
(3)式中:
—数列中的均值;
—数列的方差。本文选取冬天和夏天各一个月(1月和8月)的数据作为训练数据集,其余月份数据为测试数据。在训练集的数据中,按照85:15的比率随机分成训练子集和验证集。本文采用“最大最小法”对数据进行归一化处理。
搭建模型
本文通过python的Scikit-learn库和xgboost库搭建分别搭建BP神经网络、梯度提升机和支持向量机3种机器学习模型。通过对比不同超参数下验证集上的性能表现,确定出最优的超参数,并用最优的超参数重新用训练数据训练得出预测模型,最后在测试数据集上检验模型的预测性能。下面分别构建3种机器学习模型:
1.BP神经网络模型BP神经网络是按照误差逆向传播算法训练的多层前馈神经网络 。其中,神经网络最佳隐含层节点数的选择参考以下公式:
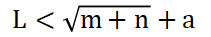
(4)
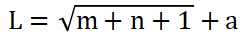
(5)式中:n—输入层节点数;m—输出层节点数;a—0~10之间的常数;L—隐含层节点数。
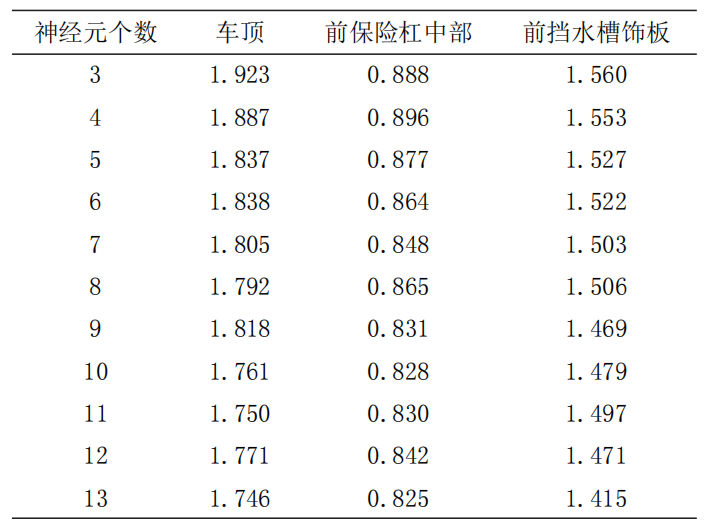
隐含层节点数选取3~13个,分别对训练集数据进行神经网络训练,结果见表1。从表1可以看出三个部件模型的隐含层神经元个数为13时,神经网络的训练性能最优。本文神经网络模型使用python软件Scikit-learn库中的MLPRegressor(多层感知机)构建,其结构为:输入层节点数为8个,输出层节点数为1个(车顶表面温度/前保险杠中部表面温度/前挡水槽饰板表面温度),隐含层节点数为13,激活函数使用sigmoid函数,最大迭代步数设为1000步,学习率为0.002,采用“adam”算法进行权重更新。表1 各部件模型的验证集平均绝对误差
2.梯度提升算法模型梯度提升算法是在函数空间中进行最优函数的搜索。通过Python软件的xgboost第三方库可以快速的构建梯度提升算法模型,在模型中设置参数如下:弱分类器设置为150个(n_estimator=150),最大树深度设置为25(max_depth=25),学习速率设为0.1(learning_rate=0.1),其它参数为默认值。
3.随机森林模型通过Python软件的Scikit-learn库快速构建随机森林算法模型,模型由300棵二叉决策树(CART)组合而成,CART没有最大深度限制(max_depth=None),最大特征设置为总特征乘以0.85(max_features=0.85),其它参数为默认值。相较于决策树,随机森林的抗过拟合能力更强。
预测结果分析
本文从2个维度对模型预测性能进行评估:一是平均绝对误差MAE;二是决定系数R2,函数形式见公式6,该值越接近于1表示数据拟合的效果越好。
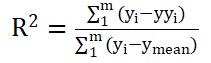
(6)式中:y—实际值;
—实际值的平均值;yy—预测值。
将测试集数据分别代入3个训练好的模型中进行预测,预测结果如图3所示。从图3可以看出神经网络、梯度提升机和随机森林对汽车部件表面温度的预测均有较好的表现,其中随机森林的预测效果最优,神经网络次之。车顶、前保险杠中部和前挡水槽饰板部件的平均绝对误差分别为2.5、1.4和2.1左右,拟合优度R2分别在0.94、0.92、0.94左右。本文采用随机森林的预测结果进行比较详细的分析。
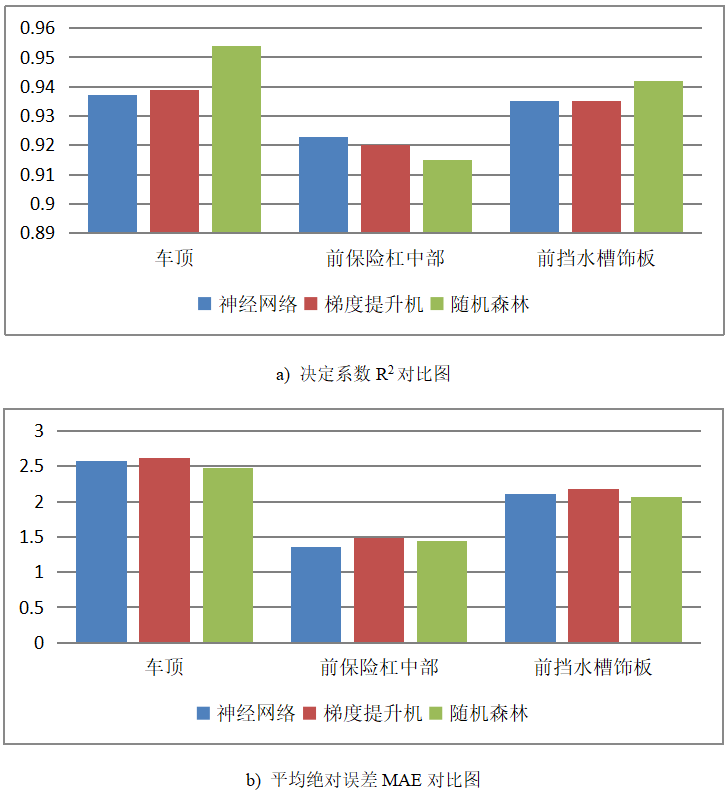
图3 三种机器学习模型预测结果
随机森林对汽车车顶温度预测结果和实际值的对比见图4,三个部件的预测误差分布图见图5所示。从图4可以看出,预测值曲线与真实值曲线基本一致,但在正午左右时分温度变化较为激烈,预测值与真实值有一定的误差。出现该现象可能一方面是因为天气时而出太阳时而多云甚至下雨,使得部件温度变化较为激烈,但在数据上且无法反应出这一情况,导致预测值与真实值存在一定差异;另一方面是所用的机器学习模型属于浅层学习模型,该算法模型无法学习到一些更细小的差别所致。
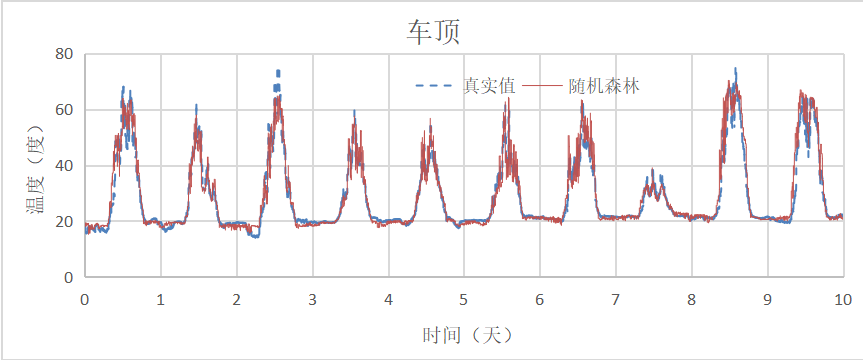
图4 预测结果与实际值对比(部分数据)
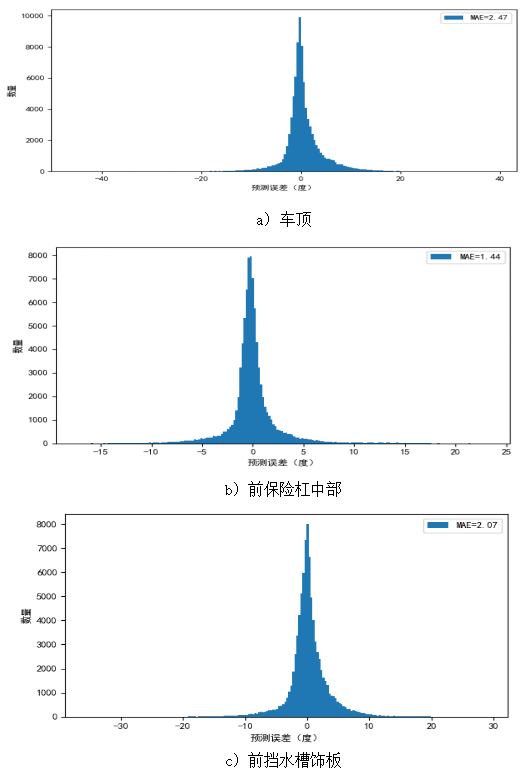
图5 误差分布
从图5可以看出3个部件的误差分布基本上呈现正太分布,均以0°误差为对称轴。对于车顶和前挡水槽饰板部件,预测误差基本在(-10~10)°之间,而前保险杠中部的预测误差基本在(-5~5)°之间。从上述分析可知,机器学习算法模型对汽车部件温度预测效果良好。
结论
通过本文采用的三种机器学习算法对汽车各个部位表面温度预测的研究,可得到如下的结论:1)通过选取8个特征气象参数(大气温度、大气湿度、太阳辐照量、红外辐照量、紫外辐照量、可见光、直接辐照量、日照时数),采用机器学习算法构建汽车部件温度预测模型,可得到较好的预测效果。2)利用试验车少量的试验数据(冬天和夏天各1个月的试验数据)训练机器学习模型(神经网络、梯度提升机、随机森林等),可预测该车部件在全年气象条件下的温度变化情况。3)汽车厂商在获取冬天和夏天的试验数据后,便可通过本文介绍方法预测全年气象条件下的汽车部件温度变化,可在一定程度上缩短户外暴露试验周期。
引用本文:
李淮,顾泽波,张晓东,祁黎,陈心欣,赵雪茹.基于数据挖掘的汽车耐候性预测算法研[J].环境技术,2022,40(02):130-135.
- 下一篇:用中国“芯”,中国汽车“新”突破势在必行
- 上一篇:商用车惯性试验台



 广告
广告 编辑推荐




最新资讯
-
下载《新能源汽车电机耐久试验:基于温度与
2026-04-09 11:35
-
电机高精度效率测试,真正的分水岭在台架和
2026-04-09 11:04
-
来ITES深圳工业展,看思看科技3D扫描天团如
2026-04-09 10:19
-
你的“光学尺子”靠得住吗?四大指标带你读
2026-04-08 18:22
-
2026中国数控机床展览会丨4月21日-25日,思
2026-04-08 18:20
