




 广告
广告





















































一文读懂自动驾驶数据闭环
2021-09-21 18:17:01· 来源:智驾最前沿

5)自动机器学习(AutoML)/元学习(学习如何学习)
一个机器学习建模的工程还有几个方面需要人工干预和可解释性,即机器学习落地流水线的两个主要组件:预-建模和后-建模(如图)。
预-建模影响算法选择和超参数优化过程的结果。预-建模步骤包括多个步骤,包括数据理解、数据准备和数据验证。
后-建模模块涵盖了其他重要方面,包括机器学习模型的管理和部署。

为了降低这些繁重的开发成本,出现了自动化整个机器学习流水线的新概念,即开发自动机器学习(automated machine learning,AutoML) 方法。AutoML 旨在减少对数据科学家的需求,并使领域专家能够自动构建机器学习应用程序,而无需太多统计和机器学习知识。
值得特别一提的是谷歌方法“神经架构搜索”(Neural Architecture Search,NAS),其目标是通过在预定义搜索空间中选择和组合不同的基本组件来生成稳健且性能良好的神经网络架构。
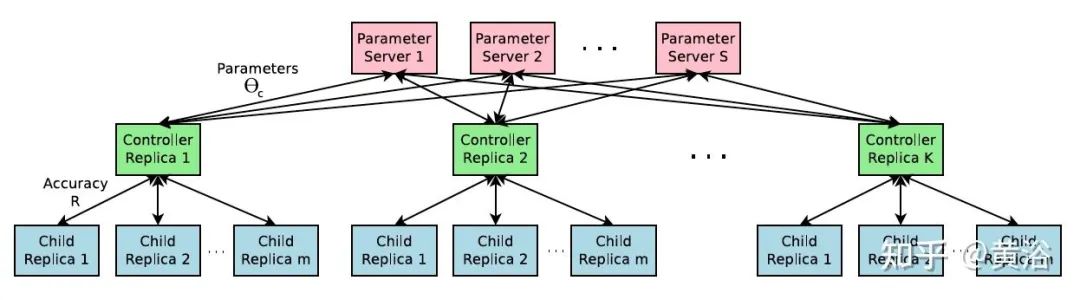
NAS的分布式训练实现
NAS的总结从两个角度了解:模型结构类型和采用超参数优化(hyperparameter optimization,HPO)的模型结构设计。最广泛使用的 HPO 方法利用强化学习 (RL)、基于进化的算法 (EA)、梯度下降 (GD) 和贝叶斯优化 (BO)方法。
如图是AutoML在机器学习平台的应用实例:

注:在谷歌云、微软云Azure和亚马逊云AWS都支持AutoML。
深度学习(DL)专注于样本内预测,元学习(meta learning)关注样本外预测的模型适应问题。元学习作为附加在原始 DL 模型的泛化部分。
元学习寻求模型适应与训练任务大不相同的未见过的任务(unseen tasks)。元强化学习 (meta-RL) 考虑代理与不断变化的环境之间的交互过程。元模仿学习 (meta-IL) 将过去类似的经验应用于只有稀疏奖励的新任务。
元学习与 AutoML 密切相关,二者有相同的研究目标,即学习工具和学习问题。现有的元学习技术根据在 AutoML 的应用可分为三类:
-
1)用于配置评估(对于评估者);
-
2)用于配置生成(用于优化器);
-
3) 用于动态配置的自适应。
元学习促进配置生成,例如,针对特定学习问题的配置、生成或选择配置策略或细化搜索空间。元学习检测概念漂移(concept drift)并动态调整学习工具实现自动化机器学习(AutoML)过程。
6)半监督学习
半监督学习(semi-supervised learning)是利用未标记数据生成具有可训练模型参数的预测函数,目标是比用标记数据获得的预测函数更准确。由于混合监督和无监督方法,半监督学习的损失函数可以具有多种形状。一种常见的方法是添加一个监督学习的损失项和一个无监督学习的损失项。
已经有一些经典的半监督学习方法:
-
“Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks”
-
“Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results“
-
“Self-training with Noisy Student improves ImageNet classification“
最近出现一些新实例方法:
-
“Unbiased Teacher for Semi-Supervised Object Detection“

-
“Pseudoseg: Designing Pseudo Labels For Semantic Segmentation“
-
“Semantic Segmentation of 3D LiDAR Data in Dynamic Scene Using Semi-supervised Learning“

-
“ST3D: Self-training for Unsupervised Domain Adaptation on 3D Object Detection“

-
“3DIoUMatch: Leveraging IoU Prediction for Semi-Supervised 3D Object Detection“

7)自监督学习
自监督学习(self supervised learning)算是无监督学习的一个分支,其目的是恢复,而不是发现。自监督学习基本分为:生成(generative)类, 对比(contrastive)类和生成-对比(generative-contrastive)混合类,即对抗(adversarial)类。
自监督使用借口任务(pretext task)来学习未标记数据的表示。借口任务是无监督的,但学习的表示通常不能直接给下游任务(downstream task),必须进行微调。因此,自监督学习可以被解释为一种无监督、半监督或自定义策略。下游任务的性能用于评估学习特征的质量。
一些著名的自监督学习方法有:
-
“SimCLR-A Simple framework for contrastive learning of visual representations“
-
“Momentum Contrast for Unsupervised Visual Representation Learning“
-
“Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning“
-
“Deep Clustering for Unsupervised Learning of Visual Features“
-
“Unsupervised Learning of Visual Features by Contrasting Cluster Assignments“



 广告
广告 



最新资讯
-
东扬精测|CLNB 2026 苏州|世界顶尖的测试
2026-04-03 09:48
-
EA-BIM 20005多通道电池阻抗测试仪如何赋能
2026-04-03 09:46
-
自动泊车测试进入厘米级时代——从最新测试
2026-04-03 09:10
-
真正决定城市体验的,不是硬件,而是控制系
2026-04-02 14:26
-
LabVIEW传奇工程师亲临现场,NI测试测量技
2026-04-02 14:24
