




 广告
广告





















































自动驾驶汽车场景测评参数生成方法及代表性指标

本文译自:
《Scenario Parameter Generation Method and Scenario Representativeness Metric for Scenario-based Assessment of Automated Vehicles》
文章来源:
IEEE Transactions on Intelligent Transportation Systems (Volume: 23, Issue: 10, October 2022)
作者:
Erwin de Gelder, Jasper Hof, Eric Cator, Jan-Pieter Paardekooper, Olaf Op den Camp,Jeroen Ploeg, Bart de Schutter
原文链接:
https://ieeexplore.ieee.org/document/9730798
摘要:基于自动驾驶汽车功能复杂操作决策域的原因,开发自动驾驶汽车性能的评价方法对自动驾驶技术推广落地尤为重要。通过真实世界道路驾驶数据构建测试用例的场景测评方法是自动驾驶汽车测评方法体系中重要组成部分。但是针对自动驾驶汽车的潜在危险性场景种类繁杂,仅仅使用观测收集的真实场景数据进行测评是远远不够的,因此必须要生成足够数量的附加场景以满足自动驾驶汽车的测评需求。本研究在两个方面做出了贡献,首先本研究提出了一种方法,在降低场景表征参数强假设的基础上,从多维度确定描述用于描述场景参数,通过对场景参数概率密度的估计,生成真实的场景参数值;其次,本研究基于Wasserstein距离构建场景代表性指标,该指标量化了生成参数值的场景在覆盖真实世界场景实际参数变量的同时对于现实世界场景的表征程度。本研究提出的方法与依赖场景参数化和概率密度估计的其它方法进行比较,结果表明本研究提出的方法可以自动确定最佳的场景参数和概率密度估计。此外,本研究的场景代表性指标可用于选择最佳描述场景的参数。本研究提出的方法具有广泛的应用前景,因为参数化和概率密度估计可以直接应用于现有的重要性采样策略,从而加速自动驾驶汽车的测试评价。
关键词:评价方法,概率密度函数,时间序列分析,安全估计,蒙特卡洛方法
一、 引言
自动驾驶汽车开发的一个重要层面是评估自动驾驶汽车在安全性、舒适性、效率性方面的质量和性能[1]-[3]。由于真实开放道路测试昂贵且耗时[4][5],因此提出了一种基于场景的测评方法[2][6]-[11]。基于场景的测评方法在众多场景中对自动驾驶汽车被测系统的响应进行测试,并评估该响应在真实世界的场景中引起变化。场景描述了自动驾驶汽车被测系统所处的状态以及这种状态如何随着时间的推移而变化(在第3-A章节中,提供了属于“场景”的精准定义)。基于场景的测评方法的优点之一是,通过选择对自动驾驶汽车被测系统具有挑战性的场景,测评可以更聚焦于具有挑战性的情况。真实世界的驾驶数据已经被使用作为场景测评的信息资源,从而保证测评场景对真实世界驾驶条件的表征[7]-[9]。
对于基于场景的测评方法,重要的是其生成的测试场景需要表征现实世界可能发生的情况。换句话说,场景应该是现实世界的表征[6]。只有这样,测评的结果才能准确表示自动驾驶汽车被测系统在真实世界中运行的性能[10]。此外,生成的测试场景必须涵盖与真实世界相同的多样性。Riedmaier等人认为,由于真实世界包含无数种情况,因此场景生成方法必须提供大量的变量才能覆盖无限多的真实情况[6]。
本研究采用数据驱动方法,通过观测到的真实场景来生成用于描述新场景的参数值。区别于预设定的信号函数,例如将车辆速度参数拟合到该函数,本研究采用奇异值分解(Singular Value Decomposition, SVD)以数据驱动的方法确定描述场景的最佳参数。接下来,估计参数的概率密度函数(Probability Density Function, PDF),以便可以使用PDF对参数进行采样生成类似的场景。为了不预先假设PDF的分布,因此采用核密度(Kernel Density Estimation, KDE)进行PDF的估计[13][14]。此外,KDE可以对场景参数之间可能存在的关联性进行建模分析。本研究还提出一种称为场景代表性(Scenario Representativeness, SR)指标,用于量化生成的场景在多大程度上具有代表性并且覆盖了多少真实世界的多样性。更具体的说,该指标使用Wasserstein距离[15]将一组生成的场景与一组观测到的真实场景进行比较。
本文章的结构安排如下。第2章节回顾本研究相关的工作;第3章节解释了用于自动驾驶汽车测评场景的生成方法;第4章节提出了一种量化场景生成方法性能的新指标;第5章节进行工况分析;第6章节讨论本研究方法的相关定义以及未来的研究方向;第7章节为结论。
二、相关工作
本章节首先回顾了有关生成测评自动驾驶汽车场景的相关工作,其次介绍与SR指标相关研究。
A. 场景生成
测评自动驾驶汽车的场景方法可以分为三种:基于对真实世界交通观察的场景,基于被测自动驾驶汽车功能的场景,以及综合前两种方法的组合方法。目前大多是研究多聚焦于第一种方法。
参考文献中提出了几种方法,用于生成基于真实世界驾驶数据的评估场景。Lages等人提出了一种通过激光雷达探测到的真实世界数据在虚拟仿真环境中重建真实场景的方法[17]。Zofka等人介绍了基于已记录的传感器数据,通过修改记录的方法创建可能可能导致危险对的场景参数[18]。Stepien等人通过从广义极值分布中采样场景参数值来生成场景,其中分布参数使用从自然驾驶数据中观察到的安全关键场景中提取的场景参数值进行拟合[19]。参数化场景和重要性采样可自动生成用于表征自动驾驶汽车被测系统关键相关(例如安全)行为的场景[10][20]-[24]。此外蒙特卡洛树搜索和遗传编程也可以生成用于表征自动驾驶汽车被测系统关键相关(例如安全)行为的场景[25][26]。Schuldt等人提供了一种使用组合算法生成场景的方法,该算法确保测试工况覆盖自动驾驶汽车被测系统在真实世界中可能面临的各种情况[27]。最近,Spooner等人提出了一个生成式对抗网络(Generative Adversarial Network, GAN)用于生成行人过街场景。
现有文献中,用于评估自动驾驶汽车的场景生成方法具体有以下一个或多的缺点:
• 观测到的场景重建时不增加更多的变化[17]。在这种情况下,除非收集到不切实际的数据量,否则无法覆盖真实世界中发现的所有场景
• 场景过于简单化。例如,车辆的速度曲线遵循预设定的函数[10][19][21]。
• 对场景参数分布的假设可能会影响场景的质量。例如,假设参数符合高斯分布或广义极值分布,或者假设某些参数是不相关的[29][19][24]。
• 因为不知道场景参数的PDF,所以一旦在真实世界道路上部署该系统,就无法对系统的性能进行评价,因为无法确定场景的真实性和可能性。在第3章节将提出一种克服这些缺点的方法。
B. 场景代表性指标
生成的场景应该代表真实世界可能发生的场景。尽管参考文献中存在不同的方法用于生成测评自动驾驶汽车场景,但对于生成的场景与真实交通的比较知之甚少。从第2-A中提到的,只有Shou Feng等人将研究生成的场景与真实自然驾驶数据进行的比较,他们比较了生成场景与真实数据中车速分布和车辆保险杠间距分布[30]。为了量化分布之间的相似性,使用了Hellinger距离和平均绝对误差[30]。这种方法的缺点为:
1)即使生成场景中的车速和保险杠间距的分布与真实自然驾驶数据分布相似,生成的场景可能仍然存在很大差异,
2)仅考虑边缘分布,但是车速和保险杠间距的相关性可能完全不同
三、场景生成
本研究采用数据驱动的方法生成测评自动驾驶汽车的真实场景:使用观察到的场景生成新的场景。为此要将场景参数化,即定义表征场景的参数。例如,场景的持续时间可以是一个参数。接下来,估计参数的PDF。此PDF可用于为新场景生成参数值。此外,PDF包含参数的统计信息,一遍可以估计自动驾驶汽车的性能[10][32]。然而,选择描述场景的参数并非易事:
• 选择少量的参数可能会导致实际场景过于简单化。因此并非所有可能性的场景都要被建模
• 由于维度灾难问题,过多的参数会导致PDF估计过于复杂[33]。
为了解决这个问题,本研究首先考虑采用尽可能多的参数用于完整地描述场景,以避免场景过于简单化。接下来,通过SVD方法使用原始场景参数的线性映射创建一组新的参数。这组新参数将根据这些参数在描述原始场景变化是做出的贡献进行排序,本研究将只考虑最重要的参数以避免丢失太多信息,这样在不依赖预先选择参数的情况下避免了维度灾难。
以下本研究将说明如何使用众多参数来描述一个场景。第3-B章节将使用SVD方法来减少参数的数量。第3-C章节描述如何使用KDE来估计简化参数集的PDF,以及如何使用估计的KDE来生成新场景。
A. 场景参数化
本研究方法的第一步是场景参数化。现阶段没有单一的最佳方法将各种各样的场景参数化,因此为了处理场景多样性难题,本研究使用场景和场景类别的定义区分定量场景和定性场景[34]。
定义1(场景):场景是在初始事件和结束事件的时间间隔内,本车车辆的相关特征活动和目标、静态环境、动态环境以及与本车车辆相关的所有时间的定量描述。
定义2(场景类别):场景类别是对本车车辆、静态环境和动态环境的相关特征活动和目标的定性描述。
场景类别是场景的抽象,因此场景类别包含多个场景[34]。例如,场景类别“切入”包括所有可能的切入场景。本研究方法的目标是根据一组观察到的场景确定同一类别场景的最佳参数化模型,并估计这些参数的PDF,这些参数可用于新场景生成的参数值。
观察到的场景通过场景时间窗口期内变化的场景内容时间序列(例如,车辆速度)和固定的场景内容附加参数(例如,车道线宽度和场景持续时间)进行描述。其中,![]() 表示场景在
表示场景在![]() 内的时间序列,其中
内的时间序列,其中![]() 表示时间序列的维度,
表示时间序列的维度,![]() ,%t_1%表示场景开始和结束的时间,附加参数
,%t_1%表示场景开始和结束的时间,附加参数![]() 由
由![]() 表示。
表示。
为了处理时间序列,连续的时间间隔t被![]() 离散化,使得两个连续的时刻间隔
离散化,使得两个连续的时刻间隔![]() 。公式如下:
。公式如下:

选择![]() 以保证在离散化过程中不会丢失任何重要信息。因为在真实世界中由于传感器读数离散型,时间序列
以保证在离散化过程中不会丢失任何重要信息。因为在真实世界中由于传感器读数离散型,时间序列![]() 是在某些特定时刻而不是在连续时刻上获得的,因此可能需要使用插值技术,例如样条[35],评估
是在某些特定时刻而不是在连续时刻上获得的,因此可能需要使用插值技术,例如样条[35],评估![]() 。
。
本研究假设![]() 个观测到的场景可用于生成新场景。为了表示场景参数y和ɵ属于某一特定场景,使用索引
个观测到的场景可用于生成新场景。为了表示场景参数y和ɵ属于某一特定场景,使用索引![]() ,即第i个场景的参数为
,即第i个场景的参数为![]() 。为了进一步简化表示方法,将
。为了进一步简化表示方法,将![]() 组合成一个向量
组合成一个向量![]() 。
。

B. SVD方法减少参数
如公式(2)所示,个参数用于描述一个场景。即使少量的,,,场景参数的总数也会变得太大而无法保证联合PDF估计置信度。避免维度灾难的一种方法是假设每个参数都是独立的,但公式(1)中的场景参数到是相关的,因此假设参数是独立的并不是一个好的解决方法。
在机械学习领域,主成分分析(Principal Component Analysis, PCA)通常用于问题降维处理[36]。本研究综合PCA方法和SVD方法,将参数转换为参数的低维向量。在应用SVD之前,使用对参数进行加权,赋予参数重要性,用于补偿参数向量中的不平衡。本研究定义了包含场景参数的矩阵:
其中表示向量的元素乘积,并且表示加权场景参数的平均值。
其中X使用SVD方法,得到
和为正交矩阵,因此这两个矩阵都可以分别对应为和的旋转矩阵。矩阵具有跟相同的形式,该矩阵除了对角线皆为。对角线包含奇异值,用表示,。这些奇异值按降序排列,如下所示
随着奇异值的降低,使用旋转矩阵X将数据转移到新的坐标系,使得第一个坐标具有最大的方差,该方差等于。类似上述方差啊,第二大方差等于并且处于第二坐标,以此类推。由于方差减少,场景参数可以仅使用新坐标系的前个坐标来近似,因为这个坐标表述了大部分的场景变化。因此第个场景的参数通过在时进行拟合:
其中是V的第个元素,是的第列,是保留的参数数量。因此第个场景的个参数可以使用个参数来近似。奇异值,向量,和用于将新场景参数映射到加权原始场景参数的近似值,。
的选择并非易事,选择过小的值会导致过多的细节损失,选择过大的值在估计新参数PDF时产生问题。选择值的一种方法是查看有前个奇异值的总体反差值。整体方差随奇异值平方的总和而变化[12],即,
因此前个奇异值通过整体方差进行选择,如下公式所示:
一种方法是设置使得公式(9)超过某个阈值,例如。选择的另一种方法是检查公式(7)中实际近似误差并不断增加直到近似误差不太大。第4章节提出了一种替代方法来确定值,使用量化指标来确定值,即生成的场景代表真实场景并涵盖真实场景的实际多样性。
C. 概率密度函数估计
基于SVD方法构建的公式(7),第个场景由以下向量描述:
当不等于时,和中的各参数无关联性。尽管其具有线性独立性,但由于高阶相关性,中的不同参数可能仍然相互依赖。因此本研究将这些参数视为因变量。为了估计的概率密度函数,本研究采用KDE方法。KDE通常被成为非参数PDF估计方法,因为KDE不依赖与数据自给定参数集的概率分布假设[13][14]。因为KDE生成的PDF会自行适应数据,所以它更适合表征的真实基础分布。KDE方法中,PDF表征如下:
是具有正定对称带宽矩阵的缩放核函数。核函数与缩放核函数的关系如下:
表示矩阵行列式,核函数选择的重要性不如带宽矩阵选择[37][38]。本研究采用高斯核函数,如下所示:
表示的平方。
使用形式的带宽矩阵,其中表示的单位矩阵。带宽通过交叉验证法确定,因为它可以根据Kullback-Leibler散度最小化真实PDF和估计PDF之间的差异[37][41][42]。使用对场景进行采样,首先随机选择一个具有相等似然性的整数,其次从具有协方差H和均值高斯核中随机抽取样本,最后使用公式(7)中的近似值计算场景参数。从计算工作量分析,从KDE中采样场景参数是有效的,因为不需要实际评估PDF。确定最佳带宽矩阵虽然需要更多的计算工作,但是每个数据集只需执行一次即可。用于带宽估计及的交叉验证方法的计算复杂度与成正比。
四、场景代表性指标
理想情况下,生成场景的参数是从具有相同分布的基础真实场景参数得到的。现阶段的问题为以上的分布是未知的。然而可以定义一个指标来量化用于生成场景的参数分布和基础真实场景的参数分布的相似性。第4-A章节将进一步说明SR指标的作用,第4-B章节解释了Wasserstein距离,并将其应用于第4-C章节中的指标。
A. 场景对比问题
参数描述的观察场景集用于生成场景参数。为了简化符号,本研究采用表示观测到的场景集。本研究假设由相同场景类别组成的场景根据函数分布并且相互独立。本研究采用表示生成的场景参数向量集,其中于公式(2)中的参数化类似,是生成场景参数向量的数量。表示生成场景参数向量的PDF,其是采用公式(7)从变化的变量中得到。理想状态下,所以本研究的指标目标是量化的相似性。为了估计的相似性,本研究不能简单的贾昂与进行比较。选取虽然能带了最好的结果,但并不理想,因为理想情况下,生成的参数需要覆盖真实世界的所有场景,而不仅仅是在中观察到的各种场景。因此,需要另一组可用于测试的场景,标记为,其中。因此,和分别称为训练集和测试集。总之,本研究的目标是使用观察到的场景参数集和以及生成场景参数集找到一个指标来量化的相似性。
B.经验Wasserstein指标
第个Wasserstein指标用于比较在集合上定义的两个PDF和。该指标如下所示:
(14)
其中表示从到的距离,将会在下面的章节定义。表示具有边缘分布,的联合分布的集合。只管说,如果将的PDF视为不同形状但质量为的两堆土,通过公式(14)将计算出将土堆改变为土堆所花费的最小消耗,因此Wasserstein也被称为推土机距离[44]。本研究的目标是构建一个度量指标来比较,因为是未知的,所以考虑基于的近似: (15)表示狄拉克函数。考虑到Z的高纬度,使用的Wasserstein指标积分的近似值对估计会导致计算量过大。因此考虑采用基于经验估计的经验Wasserstein指标用于估计[14],如下所示:
(16)将公式(15)(16)的经验估计带入,得到经验Wasserstein指标,如下所示: (17)是变换矩阵第个元素,符合以下条件: (18) (19)(20)对于距离函数,本研究根据第3-B章节中将权重缩放场景参数后,使用场景参数差异的平方数值,如下:
(21)
C.测试场景代表性指标本研究提出的SR指标基于以下假设:假设是的近似值。因为和基于相同的基础PDF,所以和的期望近似。但是,如果地期望明显小于,则表明训练数据过渡拟合,因为生成的场景过于偏向训练数据。为了避免训练数据的过渡拟合,本研究的SR指标在大于情况下的修正,因此SR指标变为:
(22)
β为修正的权重。在第5章节中的案例研究表明,与公式(22)相关联的公式(14)Wasserstein指标比公式(17)经验Wasserstein指标。
五、工况研究
工况研究章节将说明第3章节的生成场景参数和第4章节的SR指标如何应用。第5-A章节解释了研究中考虑的场景类别,并描述了关于场景参数化的选择;第5-B章节说明了使用SVD对原始参数的近似;第5-C章节除了演示了场景参数生成方法,还表明SR指标可用于选择值;第5-D章节将本研究的场景参数生成方法与其它方法进行了比较;第5-E章节表明了跟经验Wasserstein指标相比,SR指标和Wasserstein指标的相关性更好[17][22]。
A. 场景类别和参数
本研究中考虑两种场景类别。第一种场景类别为前方目标车辆减速(LVD)导致后面跟随的本车减速或转向,如图1所示。第二种场景为本车前方目标车辆切入,本车需要刹车或者改变方向以避免碰撞,如图2所示。为了获得场景,使用参考文献中描述的数据集[46]。该数据集来自于一辆自然驾驶车辆,其中 20 名司机被要求按照规定的路线驾驶,共产生 63 小时的驾驶数据,包含 1150个 LVD场景和 289个切入场景,其中大部分场景发生在高速公路上。为了感知周围的交通情况,车辆配备了三个雷达和一个摄像头,通过融合雷达和摄像头的数据来测量周围的交通[47]。为了从具有融合数据的数据集中提取 LVD 和切入场景,本研究在数据中搜索特定驾驶行为:前方目标车辆的减速行为表示 LVD 场景;前方目标车辆的车道变换行为表示切入场景。有关提取场景过程的更多信息,请参阅参考文献[48]。
图1 前方目标车辆减速场景(LVD)
图2 前方目标车辆切入场景(Cut-In)
在1150个LVD场景中,训练数据使用80%(),测试数据使用剩余的20%(),这是根据80/20比例将数据拆分为训练集和测试集。训练数据用于生成个新的场景参数向量。为了描述前方目标车辆的减速行为,使用前方目标车辆在个加速度参数。作为附件参数,考虑场景的持续时间,,目标车辆的初始速度以及目标车辆和本车之间的初始时间间隔(),因此。图3显示了100个随机选择的LVD场景的前方目标车辆的速度。第个权重是通过将选定的常数除以第个参数的标准偏差获得的:
(23)
第k个参数对整体方差的贡献如公式(8)所示只取决于。当选择,前方目标车辆的加速度对整体方差贡献在倍以上,因为有个元素用于描述加速度。针对LVD场景,本研究希望将加速度赋予与其它每个参数相同的重要性,因此选择以及。
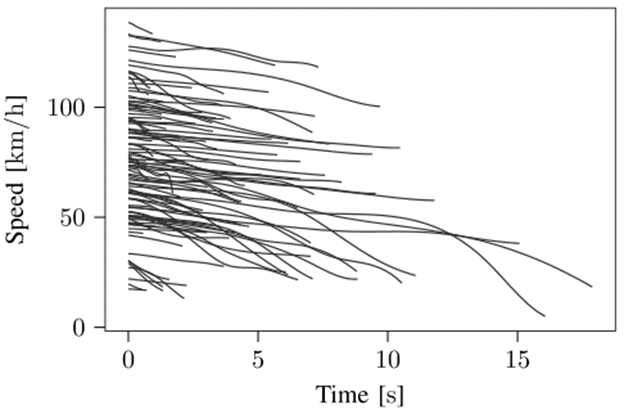
图3 LVD场景前方目标车辆速度
在289个Cut-IN场景中,训练数据使用80%(),测试数据使用剩余的20%(),这是根据80/20比例将数据拆分为训练集和测试集。训练数据用于生成个新的场景参数向量。使用前方变道车辆的速度以及相对于本车车道中心的横向位置在个时间点描述一个临界场景。在左侧切入场景下,当切入车辆岭位于本车车道中心做左侧时,横向位置为正,反之为负。此外,额外参数用于描述切入场景:场景持续时间,本车的初始速度以及切入车辆相对于本车的初始纵向距离。因此。为了对变道车辆的速度,横向位置和其它3个额外参数赋予相同的重要性,使用公式(23)计算权重,其中以及。
B. SVD方法场景拟合
第3-C章节说明使用太多参数会导致对参数PDF估计不佳。本研究使用SVD来减少能够描述原始场景参数的数量。本章节说明使用SVD方法后获得的参数对原始参数的近似情况。
经过公式(7)近似后,缩放参数向量使用的前列的线性组合来近似,即。图4和表1显示了LVD场景和U的前4列。图4显示LVD场景平均以减速开始,以减速结束。表1显示场景平均持续时间为4.73秒,前车平均初始速度为22.11km/h,平均初始时间间隔为1.49秒。由于每种情况都是通过图4和表1的值估计的,因此可以看出近似值不包含复杂的加速度曲线,意味着加速度将被平滑从而丢失部分细节。平滑量取决于值,即用于逼近原始参数向量的U的向量数量。选择值是一种权衡:值越大,平滑度越低,近似误差越小,但过大的值会导致参数PDF估计是出现问题。
表1 3个附加参数经过缩放后和U前4列表征结果
图5显示了五种LVD场景,分别对应跟随车辆最高的平均减速度。1号线表示需要最高平键减速度的LVD场景。表2中列出了的的数值,用于根据共公式(7)近似原始场景。图5中的灰线显示LVD场景的近似速度。表2显示了图5中五个场景的初始时间间隔。这五个场景说明加速是平滑,但场景的主要特征是通过近似值得到的:平均减速度,场景持续时间,初始速度和初始时间间隔。
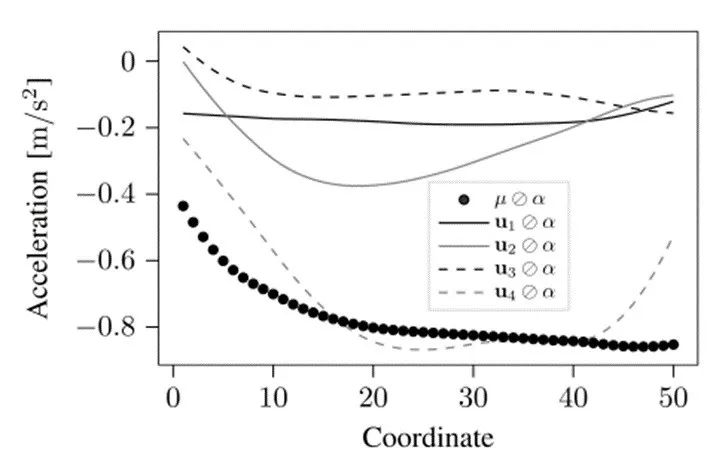
图4 LVD场景50个加速度参数经过缩放后和U前4列表征结果
表2 5个LVD场景跟随车辆的初始间隔及对应加速度
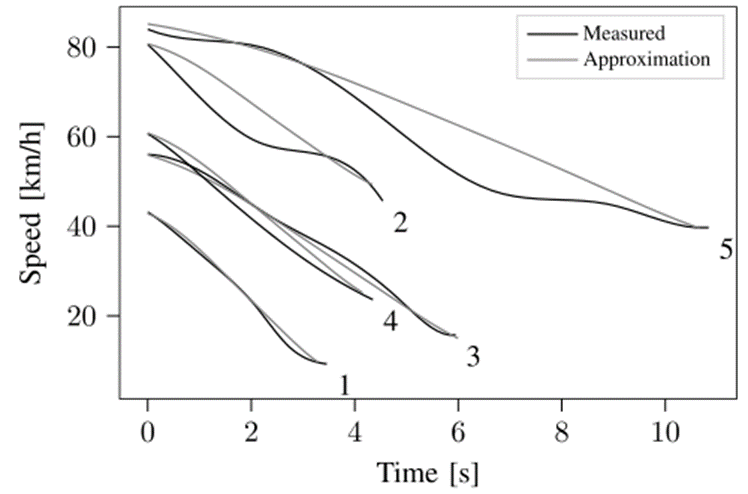
图5 五个LVD场景跟随车辆最高平均减速度。黑线为观测值,灰线为基于d=4的近似值,表2列出相应的初始时间间隔
C. 生成场景参数
生成场景参数向量的一个重要方面为确定缩减参数的数量(d)。一种方法是如公式(9)查看前个奇异值的解释方差,如表3所示。表中前4个奇异值已经表明了LVD场景中90.4%的方差,因此可能是一个合适的选择。图6显示了100个使用的参数生成的LVD场景中前车速度。
表3 LVD场景解释方差-d值
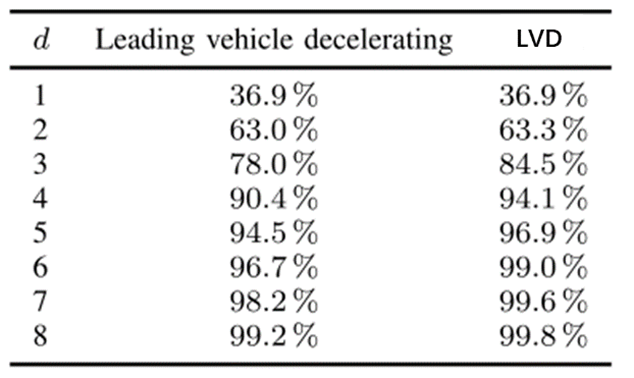
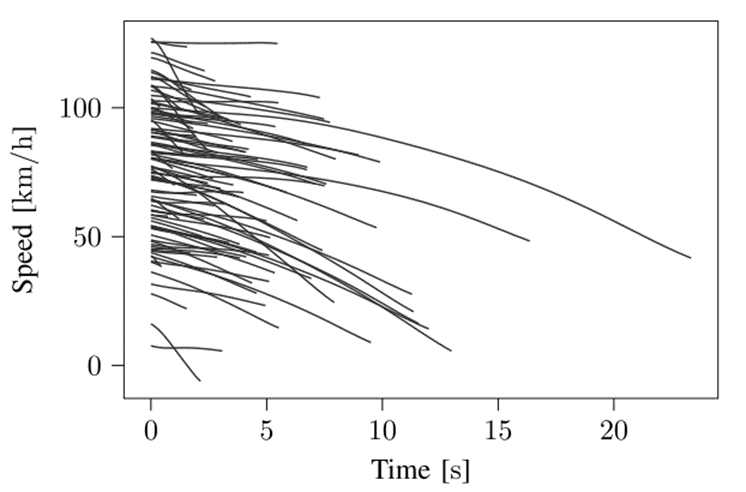
图6 100个生成场景的前车速度
另外一种确认值的方法是根据公式(22)定义的SR指标。图7展示了时应用SR指标的结果,以及经验Wasserstein指标,修正指标,。图7每一个点表示应用该指标200次时的中值,每次使用不同分区的训练数据和测试数据。图7的中值标准差采用自举检验,等于或小于0.005[50]。针对SR指标,修正使用进行加权,在第5-E章节证明其是合理的。
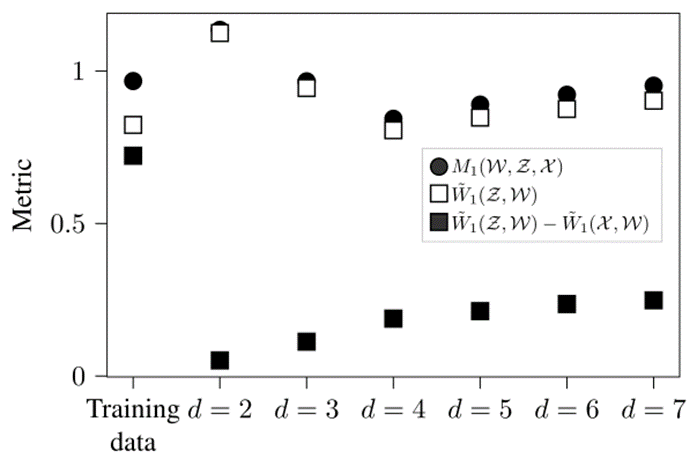
图7 生成的LVD场景参数集的指标中值
图7中最左边的电表示训练数据集X直接用于对场景采样,是从中替换个场景的选择,即(24)其中表示边界为1和的连续均匀分布。直接将训练数据用于“生成场景”会导致低数值经验Wasserstein指标,缺点是生成的场景之间没有太大的变化,因此修正值也是最高,导致。当时,与直接使用训练集对比,经验Wasserstein指标大致相似。由于从KDE中对场景参数进行采样,生成的场景比训练集包含更多的变化,导致修正值较低。因为进一步增加值会导致更高的指标评估,因此似乎是正确的选择。图8与采用与图7类似的方式显示了切入场景参数的生成结果。图8中所有点的标准偏差均小于0.008。在时获得了最低修正,但是较大值的经验Wasserstein距离表明丢失了很多信息。最好的结果在时获得,SR指标和指标最低。
D.方法对比
本研究提出的方法利用SVD来获取场景参数和多变量KDE来估计这次参数的PDF。为了说明这些选择的优点,本研究方法与其它方法进行了比较。首先,区别于使用SVD来获取参数,这次采用了固定参数化;其次,区别于使用KDE来估计参数PDF,这次是假设的高斯分布;最后,假设参数是独立的[10][18][21][29]。
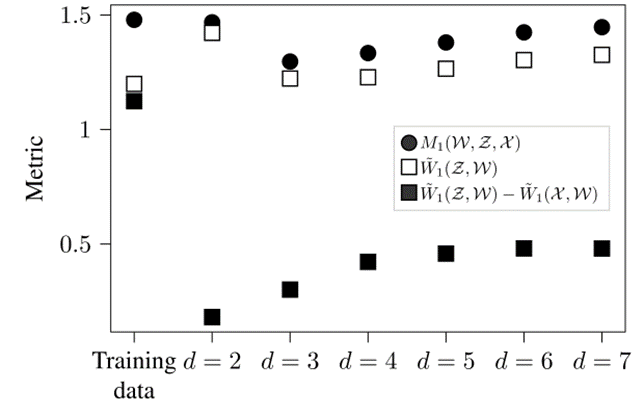
图8 生成的Cut-IN场景参数集的指标中值
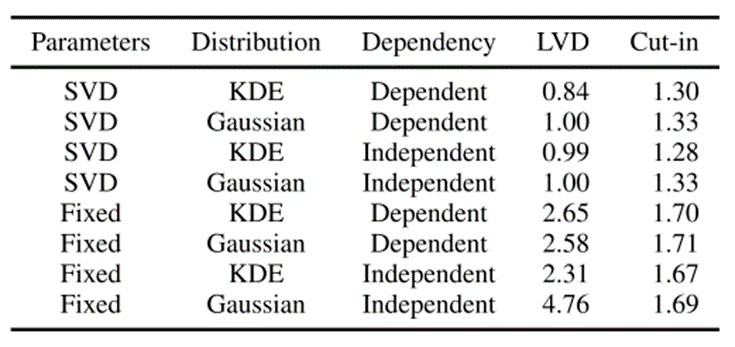
当对 LVD 场景使用固定参数化时,使用了4 个参数描述场景[10]:前方目标车辆的减速度、前方目标车辆的最终速度、场景的持续时间以及前方目标车和本车之间的初始时间间隔。假设前方目标车辆的速度遵循正弦函数,使得场景开始和结束时的加速度为零。在切入场景的情况下,使用了5个参数描述场景:车辆切入的平均速度、其相对于本车车道中心的初始横向位置、场景的持续时间、本车初始速度,以及目标车辆相对于本车切入的初始纵向位置。假设车辆切入的速度是恒定的,并且假设其横向位置遵循正弦函数,使得车辆在本车车道的中心结束。为了估计这些参数PDF,比较考虑了4种可能性:多变量 KDE、多单变量 KDE、多变量高斯分布和多单变量高斯分布。表4显示了生成场景参数的不同方法的结果。对于LVD场景,本研究提出的方法(表 4中的第一行)导致最低的。对于切入场景,是否使用SVD来获取参数对结果影响不大,这是因为较小的数据集会导致更高的带宽,使得使用高斯核的KDE结果看起来更像高斯分布。在假设参数独立的情况下使用SVD和KDE会产生更好的结果:1.30->1.28(标准差为 0.005)。这表明使用SVD获得的3个参数是独立的假设是可以接受的。
表4 不同方法生成场景的指标
E. SR指标评价
为了确定本研究提出的指标(公式22)是否与Wasserstein指标(公式14)的相关性优于经验Wasserstein指标(15),需要知道Wasserstein指标(14)。但这事实上是不可能的,因为数据的真实基础分布是未知的。为了估计Wasserstein指标(公式14),经验 Wasserstein指标(公式15)可以与大量测试场景和生成的场景参数一起使用,即分别具有较大的Nz和Nw值。由于本研究无法获得大量测试场景,因此我们假设的某个分布来自于生成训练数据和测试数据的。方法如下(数字表示LVD场景,括号内数字中显示了Cut-IN场景数量):
1)基于1150(289)个原始场景,以下场景参数通过第3章节的设定()生成:
-
一个新的训练集
-
一个新的测试集
-
一个大的测试集
2)基于,生成()个场景参数并收集在一个集合
3)本研究提出的SR指标是通过以及在的条件下计算得到的
4)Wasserstein指标(公式14)是使用经验Wasserstein指标基于来估计的。
本研究将这种方法重复了 200 次,每次都使用不同分区的训练数据X和测试数据Z的。图9和图10分别显示了这种方法在LVD场景和切入场景中的结果。结果表明当训练数据直接用于生成的场景参数时,经验 Wasserstein 指标是最小的。因此,经验Wasserstein指标表明,生成新场景参数的最佳方法是简单地从训练数据中采样参数。使用 估计的实际 Wasserstein指标表明,使用本研究提出的方法优于直接从训练数据中采样参数。
为了证明的选择是合理的,图11显示了所提出的指标的中值与不同值的之间的相关性。 ,即 ,针对LVD场景的相关性为0.974,针对切入场景的相关性为0.824。相关性随着的增加而增加,直到 LVD 场景的和切入场景的处获得最大相关性值(0.992 和 0.987)。增加会进一步降低相关性,这表明选择是合适的。
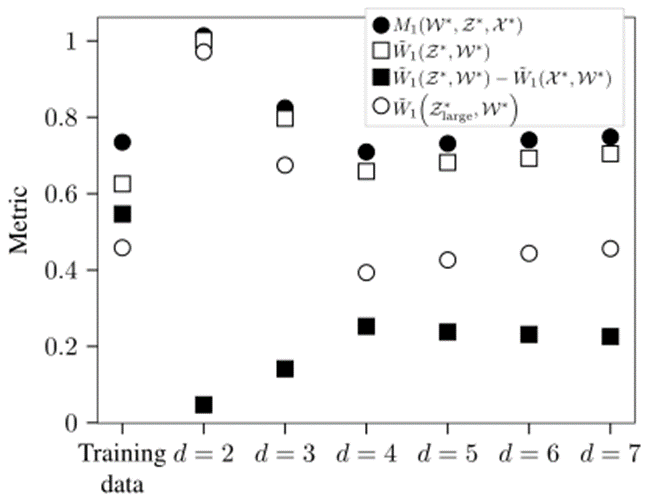
图9 Nw=10000个LVD场景参数集的指标中值
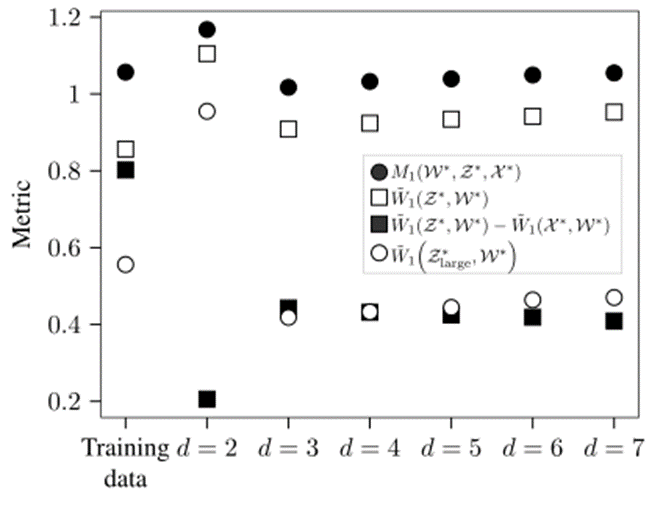
图10 Nw=10000个Cut-IN场景参数集的指标中值
在给出的初始选择(用表示)的前提下,可用以迭代方式确定和:
-
设置
-
确定 ,即使用 最小化的最佳参数数量
-
生成 和 ,其中
-
将 增加 1
-
通过最大化两者之间的相关性来确定,如图11所示
-
重复步骤2 7)如果结束,否则返回步骤3。
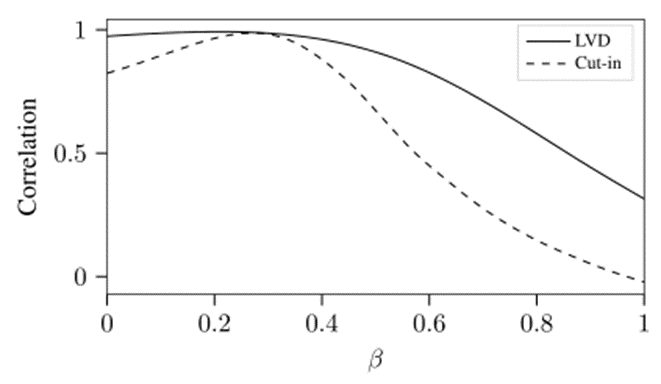
图11 和的相关性
作为初始选择,是合适的,更具体地在时,在一次迭代之后寻找的最佳选择。
Ⅵ.讨论
本研究提出生成场景参数的方法的优点之一是对场景参数化较少假设:
-
不需要对时间序列数据的预定函数形式进行假设。例如,在LVD场景中,通常假设速度遵循多项式函数[10]、正弦函数或线性函数[21]。在预定函数形式的情况下,将参数拟合到函数形式。本研究中SVD自动确定参数化的最佳选择,而不依赖于预定的函数形式。
-
不需要对参数分布进行假设。例如,可以假设特定的分布,例如其它方法需要采用参数已拟合的高斯分布[29]或均匀分布,并且对参数的独立性做出假设[24]。本研究中KDE自动调整其形状以适应数据,并考虑不同参数之间的依赖性。
如果有理由相信一个或多个假设是有效的,那么利用这些假设生成场景参数的方法可能比本研究提出的方法效果相同或更好[51].但是在大多数情况下,很难对有关函数假设(例如,车速)和场景参数的PDF 提供明确的证明。在任何情况下,本研究提出的SR指标适用于基于任何假设的有关场景参数化和参数分布研究。
生成的场景参数代表现实生活中可能发生的场景,涵盖了与现实世界交通相同的多样性。最有可能的是,这些场景中的大多数对于自动驾驶汽车来说较为简单。为了进行有效的评估,重点应该放在可能导致碰撞概率很高的危急情况的场景上。这就是为什么所谓的重要性抽样 [52,第5.6章] 经常用于评估自动驾驶汽车的性能,例如,参见文献[5]、[10]、[53]、[54]。通过重要性抽样,使用不同的PDF 对场景参数进行采样,从而更好的构建可能导致危急情况的场景。为了获得无偏的结果,使用场景参数x的测试结果按原始概率密度 与用于重要性采样的PDF概率密度[10]的比率加权[52]-[54]。在未来的工作中,我们生成场景的方法将与重要性采样[10]、[53]、[54]相结合,以评估 自动驾驶汽车性能。
在某些情况下,可能希望从条件PDF中进行采样,例如,在对LVD场景的参数进行采样,使得初始时间间隔等于指定值。从KDE中采样以便预先确定一个或多个参数是直接的 [55]。本研究的例子中,从采样使得时间间隔等于指定值会导致对样本的线性约束,因为(公式10)的缩减参数向量来自原始参数的线性映射(公式2)的,即从 (公式11) 的中采样 ,使得 受线性约束
(25)
其中和分别是矩阵和向量。参考文献提供了一种算法,用于从使用 KDE 估计的 PDF 中进行采样,使得生成的样本受到 (公式25) 的约束[40]。其主要思想是根据 与约束(公式25)的匹配程度对 KDE 中的每个参数向量 进行加权。本研究考虑采用预先确定完整轨迹的车辆数据,这对于所呈现的场景非常有效,但在驾驶员行为取决于本车车辆行为的场景中,完整的轨迹不是预先确定的[56]。为了处理这种情况,一种选择是使用具有预定义参数的驾驶员行为模型(例如,[57]、[58]),而不是描述完整的轨迹。驾驶员行为模型的参数是的一部分。本研究所提出的用于生成场景参数值的方法仍然适用于这些场景。本课题组正在研究侧重于如何使用驾驶员行为模型评价自动驾驶汽车可能响应本车车辆行为的场景。
由于使用KDE,生成的场景参数代表数据的变化。然而,如果数据不包含可能导致危急情况的场景,例如即使使用了重要性采样 [10]、[53]、[54],也不太可能生成紧急制动操作或鲁莽的边缘场景。因此,在将生成的场景用于自动驾驶汽车(安全)评估时,重要的是要有足够的数据以使数据包含此类场景。尽管尚未就所需的数据量达成共识,但已经提出了一些指标 [39]、[59],用于确定在使用数据评估自动驾驶汽车时是否收集了足够的数据。
本研究采用Wasserstein指标来提出SR指标来评估生成的场景参数。本文章说明了提出的指标如何用于确定适当数量的参数 () 以及用于对场景参数的 PDF 建模的分布类型。此外,带宽或带宽矩阵也可以通过SR指标进行优化。
将来需要更多的研究来确定对修正权重β选择造成怎样影响,以及如何选择最佳的修正权重。本研究已经证明了一种方法来验证β的初始选择是否合适,但还不确定为什么的权重是合适的选择。实际选择可能取决于、、以及场景参数的基本分布的。未来对更大数据集的研究将能够更好地确定最佳以及如何影响机制。
未来的工作包括本研究所提出的指标的使用,并结合替代方法来生成用于评估自动驾驶汽车的场景。例如,Spooner 等人使用GAN来创建行人过街场景[28][60]。GAN方法的困难之一是要知道GAN何时真正重构了底层分布。目前已经提出评估GAN性能的指标中,其中一个就是 Wasserstein指标,其能将生成的数据与测试数据进行比较[61]。本研究提出的指标基于数据集可以考虑用于评估GAN,因此为了判断本研究提出的指标在以上应用中的潜力,需要更多的研究。
Ⅶ. 结论
开发评估方法对于部署自动驾驶汽车至关重要。基于场景的评估,其中测试用例源自真实世界的道路交通场景,被认为是评估自动驾驶汽车的可行方法。本研究提出了一种生成参数化场景的方法,用于评估自动驾驶汽车的场景。为了不依赖一小组参数,本研究使用了奇异值分解 (SVD) 来减少参数。场景的参数值是通过从简化的参数集的估计概率密度函数 (PDF) 中抽取样本来生成的。为了处理PDF的未知分布,本研究提出使用核密度估计 (KDE) 来估计 PDF。本研究还提出了一种新的指标,即所谓的场景代表性 (SR) 指标,它基于 Wasserstein 指标,用于评估生成的场景参数是否代表真实场景,同时涵盖在真实世界交通中发现的相同种类。
一个案例研究说明了所提出的用于生成场景参数值的方法,该方法使用LVD场景和Cut-IN场景。案例研究还表明,所提出的指标正确量化了生成的场景参数值,其代表了真实世界场景,同时涵盖了真实交通中发现的相同种类的场景。
未来的工作涉及将所提出的方法应用于更复杂的场景,例如包含多个不同参与者的场景,以生成基于场景的测试用例用于自动驾驶汽车的安全评估。此外,将重要性采样应用于自动驾驶汽车的评估与生成场景的方法相结合将是有意义的。未来研究也包括调查使用建议的指标与生成评估自动驾驶汽车场景的替代方法相结合。
参考文献
[1] K. Bengler, K. Dietmayer, B. Farber, M. Maurer, C. Stiller, and H. Winner, “Three decades of driver assistance systems: Review and future perspectives,” IEEE Intell. Transp. Syst. Mag., vol. 6, no. 4, pp. 6–22, Oct. 2014.
[2] J. E. Stellet, M. R. Zofka, J. Schumacher, T. Schamm, F. Niewels, and J. M. Zöllner, “Testing of advanced driver assistance towards automated driving: A survey and taxonomy on existing approaches and open questions,” in Proc. 18th Int. Conf. Intell. Transp. Syst., Sep. 2015, pp. 1455–1462.
[3] P. Koopman and M. Wagner, “Challenges in autonomous vehicle testing and validation,” SAE Int. J. Transp. Saf., vol. 4, no. 1, pp. 15–24, Apr. 2016.
[4] N. Kalra and S. M. Paddock, “Driving to safety: How many miles of driving would it take to demonstrate autonomous vehicle reliability?” Transp. Res. A, Policy Pract., vol. 94, pp. 182–193, Dec. 2016.
[5] D. Zhao, X. Huang, H. Peng, H. Lam, and D. J. LeBlanc, “Accelerated evaluation of automated vehicles in car-following maneuvers,” IEEE Trans. Intell. Transp. Syst., vol. 19, no. 3, pp. 733–744, Mar. 2018.
[6] S. Riedmaier, T. Ponn, D. Ludwig, B. Schick, and F. Diermeyer, “Survey on scenario-based safety assessment of automated vehicles,” IEEE Access, vol. 8, pp. 87456–87477, 2020.
[7] H. Elrofai, J.-P. Paardekooper, E. de Gelder, S. Kalisvaart, and O. Op den Camp, “Scenario-based safety validation of connected and automated driving,” Netherlands Org. Appl. Sci. Res., TNO, The Hague, The Netherlands, Tech. Rep., 2018. [Online]. Available: http://publications.tno.nl/publication/34626550/AyT8Zc/TNO-2018streetwise.PDF
[8] A. Pütz, A. Zlocki, J. Bock, and L. Eckstein, “System validation of highly automated vehicles with a database of relevant traffic scenarios,” in Proc. 12th ITS Eur. Congr., 2017, pp. 1–8. [Online].Available:https://www.pegasusprojekt.de/files/tmpl/PDF/12th%20ITS%20European%20Co% ngress_Folien.PDF
[9] R. Krajewski, J. Bock, L. Kloeker, and L. Eckstein, “The high D dataset: A drone dataset of naturalistic vehicle trajectories on German highways for validation of highly automated driving systems,” in Proc. 21st Int. Conf. Intell. Transp. Syst. (ITSC), Nov. 2018, pp. 2118–2125.
[10] E. de Gelder and J.-P. Paardekooper, “Assessment of automated driving systems using real-life scenarios,” in Proc. Intell. Veh. Symp. (IV), 2017, pp. 589–594.
[11] J. Antona-Makoshi, N. Uchida, K. Yamazaki, K. Ozawa, E. Kitahara, and S. Taniguchi, “Development of a safety assurance process for autonomous vehicles in Japan,” in Proc. 26th Int. Tech. Conf. Enhanced Saf. Veh. (ESV), 2019, pp. 1–18. [Online]. Available: https://wwwesv.nhtsa.dot.gov/Proceedings/26/26ESV-000286.PDF
[12] G. H. Golub and C. F. Van Loan, Matrix Computations, vol. 3.Baltimore, MD, USA: John Hopkins Univ. Press, 2013.
[13] M. Rosenblatt, “Remarks on some nonparametric estimates of a density function,” Ann. Math. Statist., vol. 27, no. 3, pp. 832–837, 1956.
[14] E. Parzen, “On estimation of a probability density function and mode,” Ann. Math. Statist., vol. 33, no. 3, pp. 1065–1076, Sep. 1962.
[15] L. Rüschendorf, “The Wasserstein distance and approximation theorems,” Probab. Theory Rel. Fields, vol. 70, no. 1, pp. 117–129, 1985.
[16] L. Li, W.-L. Huang, Y. Liu, N.-N. Zheng, and F.-Y. Wang, “Intelligence testing for autonomous vehicles: A new approach,” IEEE Trans. Intell. Veh., vol. 1, no. 2, pp. 158–166, Jun. 2016.
[17] U. Lages, M. Spencer, and R. Katz, “Automatic scenario generation based on laserscanner reference data and advanced offline processing,” in Proc. Intell. Vehicles Symp. (IV), Jun. 2013, pp. 146–148.
[18] M. R. Zofka, F. Kuhnt, R. Kohlhaas, C. Rist, T. Schamm, and J. M. Zöllner, “Data-driven simulation and parametrization of traffic scenarios for the development of advanced driver assistance systems,” in Proc. 18th Int. Conf. Inf. Fusion, Jul. 2015, pp. 1422–1428. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/7266724
[19] L. Stepien et al., “Applying heuristics to generate test cases for automated driving safety evaluation,” Appl. Sci., vol. 11, no. 21, p. 10166, Oct. 2021.
[20] S. Feng, Y. Feng, C. Yu, Y. Zhang, and H. X. Liu, “Testing scenario library generation for connected and automated vehicles, Part I: Methodology,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 3, pp. 1573–1582, Mar. 2021.
[21] S. Thal et al., “Incorporating safety relevance and realistic parameter combinations in test-case generation for automated driving safety assessment,” in Proc. Intell. Transp. Syst. Conf. (ITSC), 2020, pp. 666–671.
[22] S. Feng, Y. Feng, X. Yan,S. Shen, S. Xu, and H. X. Liu, “Safety assessment of highly automated driving systems in test tracks: A new framework,” Accident Anal. Prevention, vol. 144, Mar. 2020, Art. no. 105664.
[23] L. Li, N. Zheng, and F.-Y. Wang, “A theoretical foundation of intelligence testing and its application for intelligent vehicles,” IEEE Trans. Intell. Transp. Syst., vol. 22, pp. 6297–6306, 2020.
[24] S. Feng, X. Yan, H. Sun, Y. Feng, and H. X. Liu, “Intelligent driving intelligence test for autonomous vehicles with naturalistic and adversarial environment,” Nature Commun., vol. 12, no. 1, pp. 1–14, Dec. 2021.
[25] M. Koren, S. Alsaif, R. Lee, and M. J. Kochenderfer, “Adaptive stress testing for autonomous vehicles,” in Proc. Intell. Veh. Symp. (IV), 2018, pp. 1898–1904.
[26] A. Corso and M. J. Kochenderfer, “Interpretable safety validation for autonomous vehicles,” in Proc. 23rd Int. Conf. Intell. Transp. Syst. (ITSC), 2020, pp. 1–6.
[27] F. Schuldt, A. Reschka, and M. Maurer, “A method for an efficient, systematic test case generation for advanced driver assistance systems in virtual environments,” in Automotive Systems Engineering II. Cham, Switzerland: Springer, 2018, pp. 147–175.
[28] J. Spooner, V. Palade, M. Cheah, S. Kanarachos, and A. Daneshkhah, “Generation of pedestrian crossing scenarios using ped-cross generative adversarial network,” Appl. Sci., vol. 11, no. 2, p. 471, Jan. 2021.
[29] O. Gietelink, “Design and validation of advanced driver assistance systems,” Ph.D. dissertation, Transp. Res. Centre Delft, Delft Univ. Technol., Delft, The Netherlands, 2007. [Online]. Available: http://resolver.tudelft.nl/uuid:b2f0e7f6-6255-4932-8b5e-d3ef67cd81ec
[30] S. H. Cha, “Comprehensive survey on distance/similarity measures between probability density functions,” Int. J. Math. Models Methods Appl. Sci., vol. 1, no. 4, pp. 300–307, Nov. 2007.
[31] S. Kullback and R. A. Leibler, “On information and sufficiency,” Ann. Math. Statist., vol. 22, no. 1, pp. 79–86, 1951.
[32] D. Zhao et al., “Accelerated evaluation of automated vehicles safety in lane-change scenarios based on importance sampling techniques,” IEEE Trans. Intell. Transp. Syst., vol. 18, no. 3, pp. 595–607, Mar. 2017.
[33] D. W. Scott, Multivariate Density Estimation: Theory, Practice, and Visualization. Hoboken, NJ, USA: Wiley, 1992.
[34] E. de Gelder et al., “Towards an ontology for scenario definition for the assessment of automated vehicles: An object-oriented framework,” IEEE Trans. Intell. Veh., early access, Jan. 25, 2022, doi: 10.1109/TIV.2022.3144803.
[35] C. de Boor, A Practical Guide to Splines, vol. 27. New York, NY, USA: Springer, 1978.
[36] H. Abdi and L. J. Williams, “Principal component analysis,” Wiley Interdiscipl. Rev., Comput. Statist., vol. 2, no. 4, pp. 433–459, 2010.
[37] B. A. Turlach, “Bandwidth selection in kernel density estimation: A review,” Inst. Statistik Ökonometrie, Humboldt-Univ. Berlin, Berlin, Germany, Tech. Rep., 1993.
[38] T. Duong, “KS: Kernel density estimation and kernel discriminant analysis for multivariate data in R,” J. Stat. Softw., vol. 21, no. 7, pp. 1–16, 2007.
[39] E. de Gelder, J.-P. Paardekooper, O. Op den Camp, and B. De Schutter, “Safety assessment of automated vehicles: How to determine whether we have collected enough field data?” Traffic Injury Prevention, vol. 20, no. S1, pp. 162–170, 2019.
[40] E. de Gelder, E. Cator, J.-P. Paardekooper, O. Op den Camp, and B. De Schutter, “Constrained sampling from a kernel density estimator to generate scenarios for the assessment of automated vehicles,” in Proc. Intell. Veh. Symp. Workshops, 2021, pp. 203–208.
[41] R. P. W. Duin, “On the choice of smoothing parameters for Parzen estimators of probability density functions,” IEEE Trans. Comput., vol. C-25, no. 11, pp. 1175–1179, Nov. 1976.
[42] A. Z. Zambom and R. Dias, “A review of kernel density estimation with applications to econometrics,” Int. Econ. Rev., vol. 5, no. 1, pp. 20–42, 2013. [Online]. Available: http://www.era.org.tr/makaleler/13120083.PDF
[43] A. Gramacki, Nonparametric Kernel Density Estimation Its Comput. Aspects, J. Kacprzyk, Ed. Cham, Switzerland: Springer, 2018.
[44] Y. Rubner, C. Tomasi, and L. J. Guibas, “The earth mover’s distance as a metric for image retrieval,” Int. J. Comput. Vis., vol. 40, no. 2, pp. 99–121, Nov. 2000.
[45] M. Sommerfeld and A. Munk, “Inference for empirical Wasserstein distances on finite spaces,” J. Roy. Stat. Soc., Ser. B Stat. Methodol., vol. 80, no. 1, pp. 219–238, Jan. 2018.
[46] J.-P. Paardekooper et al., “Automatic identification of critical scenarios in a public dataset of 6000 km of public-road driving,” in 26th Int. Tech. Conf. Enhanced Saf. Veh. (ESV), 2019, pp. 1–8. [Online]. Available: https://www-esv.nhtsa.dot.gov/Proceedings/26/26ESV-000255.PDF
[47] J. Elfring, R. Appeldoorn, S. van den Dries, and M. Kwakkernaat, “Effective world modeling: Multisensor data fusion methodology for automated driving,” Sensors, vol. 16, no. 10, pp. 1–27, 2016.
[48] E. de Gelder, J. Manders, C. Grappiolo, J.-P. Paardekooper, O. Op den Camp, and B. De Schutter, “Real-world scenario mining for the assessment of automated vehicles,” in Proc. Int. Transp. Syst. Conf. (ITSC), 2020, pp. 1073–1080.
[49] B. Doerr and A. M. Sutton, “When resampling to cope with noise, use median, not mean,” in Proc. Genetic Evol. Comput. Conf., Jul. 2019, pp. 242–248.
[50] B. Efron, “Bootstrap methods: Another look at the jackknife,” in Breakthroughs Statistics. New York, NY, USA: Springer, 1992, pp. 569–593.
[51] S. Siegel, “Nonparametric statistics,” Amer. Stat., vol. 11, no. 3, pp. 13–19, Jun. 1957.
[52] R. Y. Rubinstein and D. P. Kroese, Simulation Monte Carlo Method. Hoboken, NJ, USA: Wiley, 2016.
[53] S. Jesenski, N. Tiemann, J. E. Stellet, and J. M. Zöllner, “Scalable generation of statistical evidence for the safety of automated vehicles by the use of importance sampling,” in Proc. 23rd Int. Conf. Intell. Transp. Syst. (ITSC), 2020, pp. 1–8.
[54] Y. Xu, Y. Zou, and J. Sun, “Accelerated testing for automated vehicles safety evaluation in cut-in scenarios based on importance sampling, genetic algorithm and simulation applications,” J. Intell. Connected Veh., vol. 1, no. 1, pp. 28–38, Oct. 2018.
[55] M. P. Holmes, A. G. Gray, and C. Lee Isbell, “Fast nonparametric conditional density estimation,” 2012, arXiv:1206.5278.
[56] M. Althoff, M. Koschi, and S. Manzinger, “CommonRoad: Composable benchmarks for motion planning on roads,” in Proc. IEEE Intell. Veh. Symp. (IV), Jun. 2017, pp. 719–726.
[57] M. Treiber, A. Hennecke, and D. Helbing, “Congested traffic states in empirical observations and microscopic simulations,” Phys. Rev. E, Stat. Phys. Plasmas Fluids Relat. Interdiscip. Top., vol. 62, no. 2, pp. 1805–1824, Aug. 2000.
[58] A. Kesting, M. Treiber, and D. Helbing, “General lane-changing model MOBIL for car-following models,” Transp. Res. Rec., vol. 1999, pp. 86–94, Jan. 2007.
[59] W. Wang, C. Liu, and D. Zhao, “How much data are enough? A statistical approach with case study on longitudinal driving behavior,” IEEE Trans. Intell. Veh., vol. 2, no. 2, pp. 85–98, Jun. 2017.
[60] I. J. Goodfellow et al., “Generative adversarial nets,” in Proc. 27th Int. Conf. Neural Inf. Process. Syst. (NIPS), vol. 2, 2014, pp. 2672–2680.
[61] A. Borji, “Pros and cons of GAN evaluation measures,” Comput. Vis. Image Understand., vol. 179, pp. 41–65, Feb. 2019.



 广告
广告 



最新资讯
-
整车性能测试体系:汽车试验工程的基本框架
2026-03-10 12:54
-
联合国法规R76对轻便摩托车前照灯远近光性
2026-03-10 12:15
-
联合国法规R75对摩托车与轻便摩托车气压轮
2026-03-10 12:14
-
联合国法规R74对L1类车辆灯光与光信号装置
2026-03-10 12:14
-
联合国法规R73对货车侧面防护装置的工程化
2026-03-09 12:14
