




 广告
广告





















































综述-图强化学习在混合自动化交通中的协同决策应用

论文“Graph Reinforcement Learning Application to Co-operative Decision-Making in Mixed Autonomy Traffic: framework, Survey, and Challenges“,作者来自北理工、德国德累斯顿大学、新加坡南洋理工和瑞士ETH。
智能网联车(CAV)的正常运行对于未来智能运输系统的安全和效率至关重要。同时,过渡到全自动驾驶之前需要长时间的混合自动化交通,包括CAV(AV)和人类驾驶车辆(HV)。因此,CAV的协同决策,对于生成适当的驾驶行为,和提高混合自动化交通的安全性和效率,是至关重要的。近年来,深度强化学习(DRL)被广泛应用于解决决策问题。然而,现有的基于DRL的方法主要集中于解决单个CAV的决策。
在混合自动化交通中,现有的基于DRL的方法不能准确地表示车辆的交互影响以及对动态交通环境进行建模。为了解决这些缺点,本文提出一种用于混合自动化交通中CAV的多智体决策的图强化学习(GRL)方法。首先,设计了通用的模块化GRL框架。然后,对DRL和GRL方法进行了系统综述,重点介绍了最近研究遇到的问题。此外,基于所设计的框架,进一步对不同的GRL方法进行比较研究,验证GRL方法的有效性。结果表明,与DRL方法相比,GRL方法可以很好地优化CAV在混合自动化交通中的多智体决策性能。最后,总结挑战和未来的研究方向。
源代码下载可以在https://github.com/Jacklinkk/GraphCAV。
伯克利分校的开源软件Flow是一个基于DRL的混合自动化交通框架,它充当交通模拟器(例如Sumo和Aimsun)和RL库之间的接口。Flow框架不仅提供典型的交通场景,还为RL算法的开发和验证创建几个基准;它还支持道路网络文件(例如OpenStreetMap)的导入操作,模拟真实世界条件下的交通操作。
基于GRL的方法的主要特征可以概括如下:1)将混合自动化交通建模为图架构。特别地,车辆被视为图节点,而车辆的交互被视为图边。2) 采用GNN进行特征提取;提取的特征被馈送到策略网络以生成CAV的驾驶行为。许多研究用基于GRL的方法来生成协作行为。
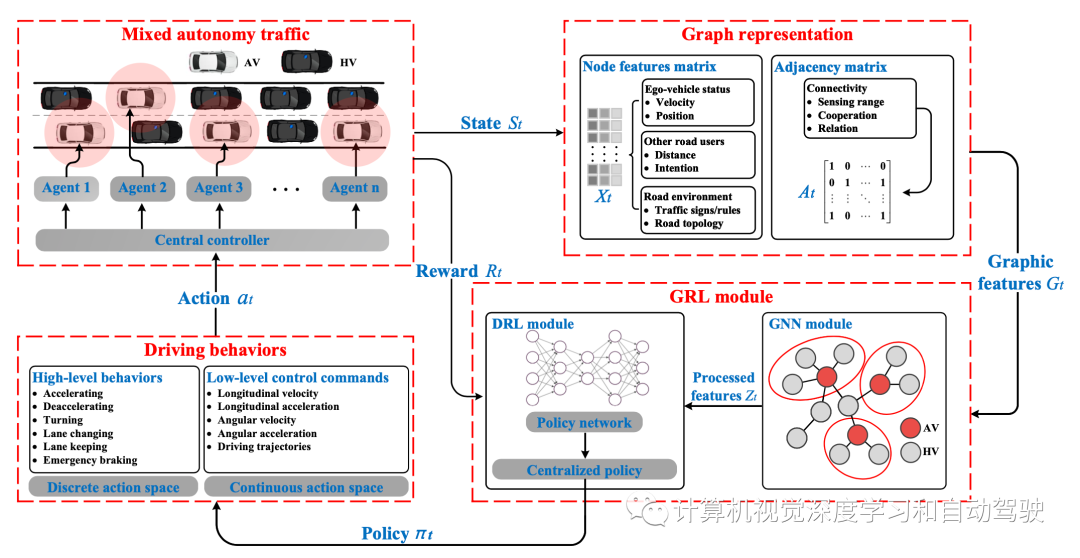
根据输出水平,驾驶行为可分为两类:高级行为和低级控制命令。高级行为主要包括并线、超车和车道保持,而低级控制命令包括各种车辆控制方向的速度和加速度等。驾驶行为表现为一个动作空间,可分为离散动作空间和连续动作空间。
高级行为只能表示为离散的行为空间;而低级控制命令可以表示为离散的动作空间。DRL模块的不同策略生成方法,生成不同的行动空间,进而生成不同类别的驾驶行为。
连续动作空间由控制命令的特定值组成。例如,在高速公路场景中,连续动作空间可以定义为a = [at,t] ,其中at表示纵向加速度,t表示转向角。使用多维(或一维)向量对连续动作空间进行编码,其中每个编码位置表示控制命令。控制命令通常被限制在某个数值范围内,并且控制命令的特定值基于所采用的控制策略而定。连续动作空间可以以一定粒度离散化,但在这种情况下,必须考虑控制精度和动作空间维度之间的权衡。
GRL模块包含两个子模块:GNN模块和DRL模块。该模型使用图特征作为输入,输出策略作为动作选择的基础。

不同类型的DRL方法产生不同的驾驶策略类别。DRL方法可分为基于价值的方法和基于策略的方法。基于价值的方法仅适用于离散动作空间;这些方法旨在生成由不同动作价值组成的驾驶策略,然后根据每个可用动作的价值选择驾驶行为。基于策略的方法适用于离散和连续动作空间。可以生成这两种随机确定性驾驶策略,然后相应地选择驾驶行为。
基于DRL的方法在混合自动化交通的决策中非常流行。然而,当仅使用DRL来解决多智体决策和协同驾驶时,系统复杂性显著增加,并且难以对智体之间的关系进行建模。由于GNN可以获得拓扑关系,并有助于对多智体的相互影响进行建模,因此它在提高混合自动化交通中的决策性能方面具有巨大潜力。基于GRL的方法的详细结构如图所示:
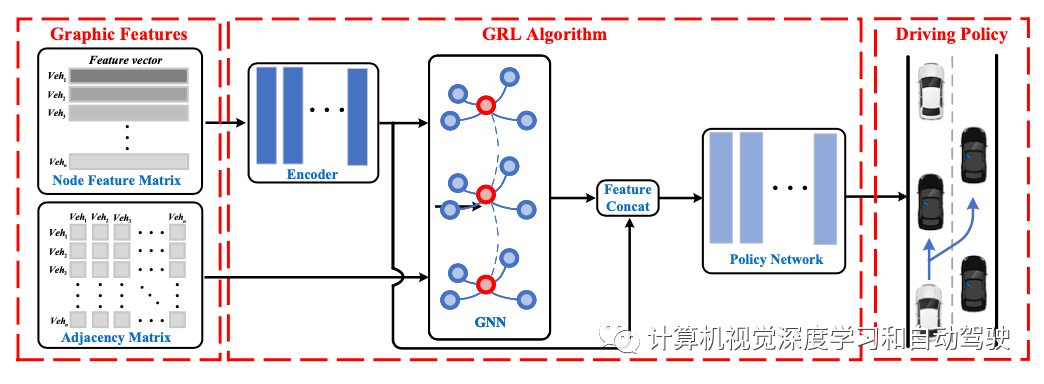
在一个“高速公路闸道”场景中,输出驾驶行为表示为 一个用于控制自动驾驶车辆横向运动的高级变道命令列表。HVs和AVs的纵向控制均通过智能驾驶员模型(IDM)实现,而HVs的横向控制则通过SUMO的LC2013变道模型实现。
高速公路闸道方案是一种开环(非封闭)方案。除了节点特征矩阵和邻接矩阵之外,场景还包括索引矩阵(标注HV或者AV)。因此,图表征由节点特征矩阵、邻接矩阵和索引矩阵组成。
其驾驶行为被表征为离散的动作空间。在每个时间步,行动空间包括不同的变道指令。
车辆驾驶的目标是高效、安全地退出相应的匝道,同时将对HVs的影响降至最低。奖励函数由四部分组成:平均速度奖励、意图奖励、变道惩罚和碰撞惩罚。
在一个“8字形”场景中,输出驾驶行为是一个用于控制自动驾驶车纵向运动的低级控制命令列表,而HVs的纵向控制由IDM实现。
该场景作为由两个单车道环形网络组成交叉口的封闭表征。当车辆同时到达十字路口时,必须减速以遵守通行规则。这样降低网络中车辆的平均速度。在这种情况下,需要协同驾驶提高车辆的平均速度,同时确保安全,以优化交叉口通行能力。
8字形场景是一个闭环场景,因此不需要索引矩阵。其邻接矩阵的推导方式与高速公路匝道场景相同,但节点特征矩阵不同。
其驾驶行为表现为连续动作空间。在每个时间步,动作空间由纵向加速度组成。
在所考虑的高速公路闸道和8字形两个场景中,奖励的定义受场景和任务绩效的影响(例如,总体交通效率、特定车道的交通效率、场景中特定类型车辆通行时间的缩短)。此外,对于混合自动驾驶交通中的多智体协同决策问题,必须考虑整体回报和个体回报之间的冲突。这包括具有不同主动性水平的人类驾驶员之间的社会交互和隐性协同作用。奖励函数的设计过程还需要考虑HVs和AVs的优先级,在设计损失函数时需要考虑这些优先级,以及涉及自动驾驶的法律法规的制定和稳健性。
未来智能网联车的研究应该集中在以下三点:(1)如何设计智能联网车队的轨迹控制算法和策略,以便车辆在红灯信号面前能够平稳减速,实现最小的停车次数、油耗和尾气排放量;(2) 如何充分利用车队信息优化信号时间方案,实现最小延误和最优交通效率的控制目标;(3) 如何与上下游交叉口兼容,将优化控制扩展到路网,并实时解决优化问题。
应考虑更复杂的车辆运动学和动力学模型,因为道路条件和车辆模型的参数对于准确评估车辆运动至关重要。
- 下一篇:车辆架构的变化对雷达系统的挑战
- 上一篇:软包装锂电池的短路失效分析



 广告
广告 



最新资讯
-
助低空经济落地,路空一体安全技术研讨会在
2026-03-26 18:27
-
联合国法规R83对车辆污染物排放型式批准的
2026-03-26 12:19
-
国家智能汽车电器质量检验检测中心落地杭州
2026-03-26 08:33
-
漂移、赛道、弹射:智能底盘如何把极限变成
2026-03-26 08:32
-
国内单体最大综合试验场启用,为“智驾+低
2026-03-25 15:12
