




 广告
广告





















































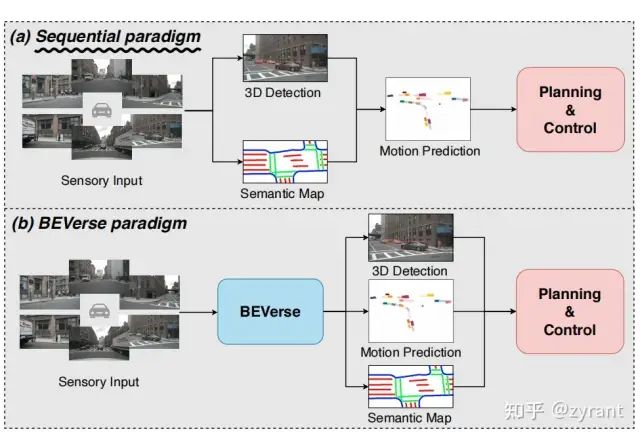
基于纯视觉策略的BEV感知

检测前置介绍
量产级自动驾驶需要对世界进行可扩展的三维推理。随着自动驾驶汽车和其他交通代理在道路上移动,大多数时候推理不需要考虑高度,这使得鸟瞰图 (BEV) 成为一种充分的表示。
为什么需要BEV
在BEV视角施行camera感知可以使来自camera的特征能够直接的和来自LiDAR的特征(BEV特征)直接融合。
BEV的结果更加适合下游任务,prediction and planning。
单纯依靠手工制作的规则将 2D 观察提升到 3D 是不可扩展的。BEV 表示有助于过渡到早期的融合管道,使融合过程完全由数据驱动。最后,在仅视觉系统(无雷达或激光雷达)中,几乎必须在 BEV 中执行感知任务,因为在传感器融合中没有其他 3D 提示可用以执行此视图转换。
四种类型的单目BEV感知
IPM: 需要基于地面平坦的假设
Lift-splat:利用单目深度估计提升2D投影到3D,再转到BEV
MLP: 使用 MLP 对视图转换进行建模
Transformer:使用基于注意力的Transformer对视图转换进行建模。具体地说,基于交叉注意的Transformer模块。
目前比较火的是Lift-splat和Transformer两种方案,这里也主要总结这两种方案。
Lift-splat
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
作者:Jonah Philion,Sanja Fidler
级别:ECCV 2020
论文链接:ecva.net/papers/eccv_20
代码:github.com/nv-tlabs/lif
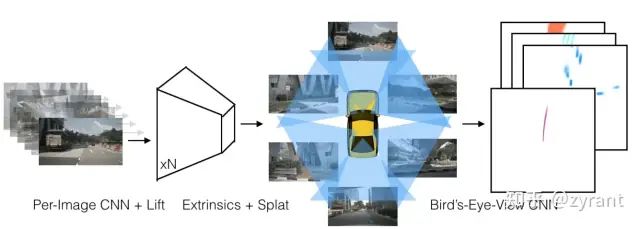
Lift, Splat, Shoot(LSS)
框图如上所示,此处主要关注环视图到BEV特征的转换。
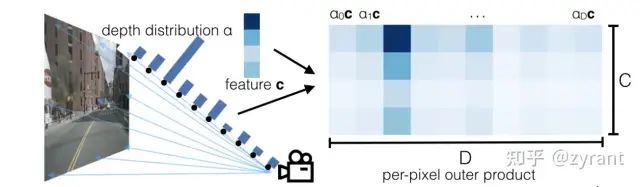
Lift
Lift为了获取深度信息,提取2D图像中的像素在以车身坐标为原点的3D世界中的特征。
上图为lift操作的关键定义,即为每个像素点生成一堆离散的深度值,在模型训练的时候,由网络自己选择合适的深度。因为图像中每个像素都对应着从相机出来的一条射线,但是不知道的是这个像素到底在这条射线上的那个位置,就像上图所示的给定了10个离散的深度分布,可以通过预测这个像素属于某个分布的概率。
具体代码如下。
Splat的操作为了算出该像素具体位于3D空间的哪个坐标位置。
目前已经得到了像素的2D像素坐标以及深度值,再加上相机的内参以及外参,即可计算得出像素对应的3D坐标。后续还有些同grid的特征sum操作。
BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
作者: Junjie Huang, Guan Huang, Zheng Zhu, Yun Ye, and Dalong Du
级别:arxiv 2022,BEV这个名字的开山之作
设备:8 NVIDIA GeForce RTX 3090 GPUs
论文链接:arxiv.org/abs/2112.1179
代码:github.com/HuangJunJie2
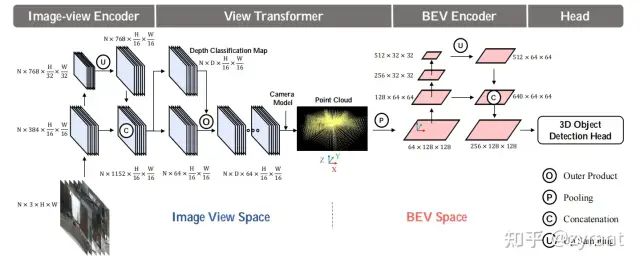
BEVDet
整体结构不复杂,甚至可以认为是LSS的在3D检测的拓展,但是其创新性的将环视图检测统一到了BEV空间,为后续的工作提供了很好的模板。
模型被划分为四个部分,Image-view encoder,view-transformer,BEV-Encoder,Head。其中的View ransformer可以被认为是LSS中的Lift和Splat操作,FPN-LSS是LSS采用的FPN,是将1/32的特征上采样2倍后直接与1/16的特征concat。
数据增强:
图像视角:在图像view下的数据增强再经过view transformer时需要一个逆向的数据增强来保证图像特征与BEV视角的目标对齐,所以经过view transformer之后,这部分数据增强失效了。
BEV视角:BEV视角下很多特征是冗余的(环视图存在交集),会导致过拟合。因此,作者在BEV里也应用了数据增强。
Scale-NMS:
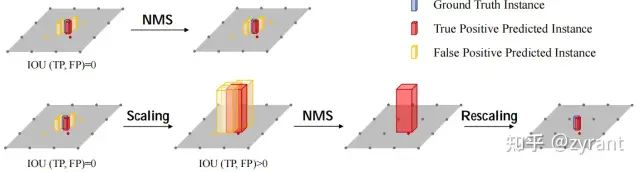
Scale-NMS
BEVDet认为图下视角下的物体都是拥有统一的空间分布,但是在BEV视角下,不同物体的分布是不同的,比如说行人在0.8m的分辨率下(centerpoint输出),其所占空间甚至小于最小分辨率,因此TPI(True Positive Predicted Instance)与GTI(Ground Truth Instance)在标准的NMS下计算IOU甚至会约等于0。
此处,作者提出可以先scale object然后在进行标准的NMS,方法很简单,但是很有效。
M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
作者:Enze Xie, Zhiding Yu, Daquan Zhou, Jonah Philion, Anima Anandkumar, Sanja Fidler, Ping Lu_ _, Jose M. Alvarez
级别:arxiv 2022
设备:3 DGX nodes,8 Tesla-V100 GPUs
论文链接:arxiv.org/abs/2204.0508
代码:nvlabs.github.io/M2BEV/
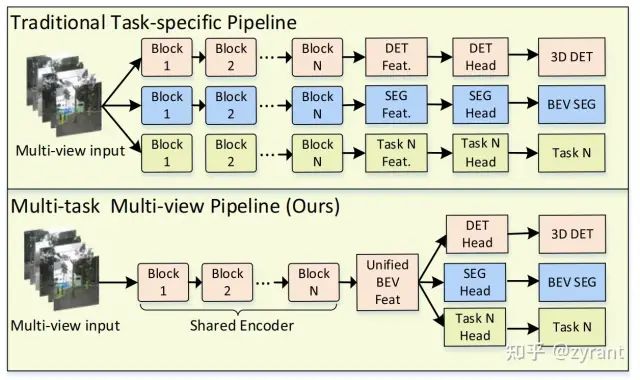
M2BEV与先前模型的区别
传统的BEV分割和3D检测任务是分割开的,分别进行的任务,最终完成自动驾驶的场景感知任务。
本文的目的是在BEV的统一框架下同时学习BEV分割和3D检测,完成简单的场景感知任务。
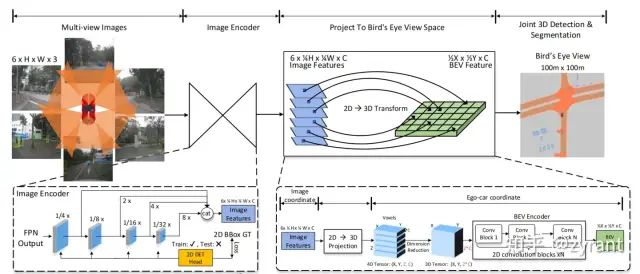
M2BEV
主要涉及几个重要的设计:
有效的2D->3D的投影:作者利用的是LSS中的方案,来将2D特征投影到3D BEV空间,为了减少参数的计算,作者和PETR中一样,认为是射线上每个voxel的权重都是一致的,从而减少了计算。
有效的BEV Enocoder:作者采用了类似pillar的方式,将4D tensor (X × Y × Z × C)直接reshape成(X × Y × (Z × C))3Dtensor,然后就可以采用2D CNN计算减少参数。
动态的Box 配准技术:采用的Free Anchor的技术。
BEV centerness:在BEV空间中,远离ego汽车的区域对应于图像中更少的像素。所以一个直观的想法是让网络更多地关注更远的区域。centerness计算公式为:
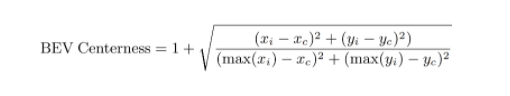
(Xc, Yc)代表中心。
作者提到的几个失败的点:
大物体检测效果不佳,车道线分割效果不佳。分割任务和检测任务不能很好的互补,现在呈现一种对抗的局面
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection
作者:Junjie Huang, Guan Huang
级别:arxiv 2022
设备:8 NVIDIA GeForce RTX 3090 GPUs
论文链接:arxiv.org/pdf/2203.1705
代码:github.com/HuangJunJie2

BEVDet4D
BEVDet的拓展,首次引入了时间信息,大大提升了velocity的精度。
具体介绍:
单帧信息有限,影响性能。
在BEVDet的基础上进行细微的改动,主要涉及spatial alignment operation使其能结合前帧和当前帧的特征。
因为引入了时间线索,velocity的求解变成了求两个帧特征之间的位置offset了。
与BEVFormer的区别:
BEVFormer使用的是2D视频目标检测的套路,它使用的是attention在4D 空间-时间内融合特征信息。
BEVFormer的velocity来自多个相邻帧的融合特征,比如4帧。
BEVDet4D首先仅采用了两个相邻帧的特征,并且其velocity更加精准,整体结构更加优雅。
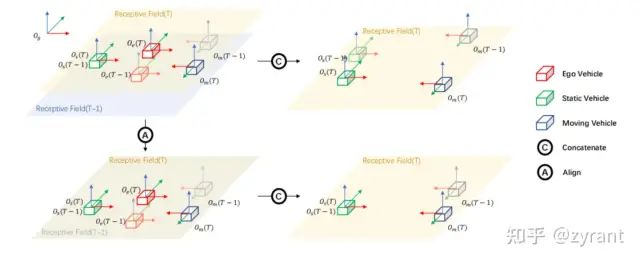
上图为空间对齐操作,为什么需要对齐,以上图右上角的绿色静止小车为例,如果不对齐,因为自车ego-car的运动,这时候目标在特征图上的偏移量就包含了自车的运动成分了,会使得offset计算变得非常复杂。
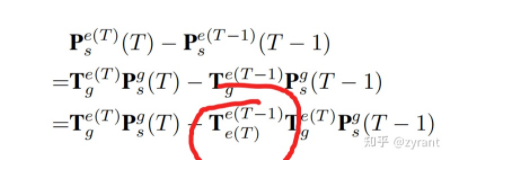
此为,未对其前的特征offset求解,需要注意的是红圈区域,会出现ego-motion的运算,作者提及涉及ego运算时很复杂麻烦,因此多加了T来抵消。
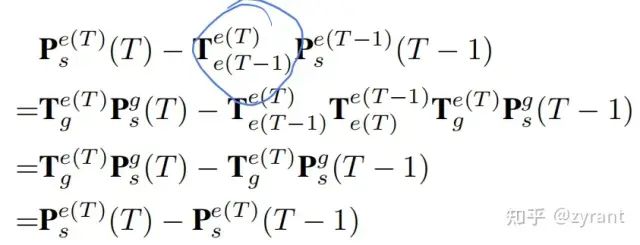
BEVerse: Unified Perception and Prediction in Birds-Eye-View for Vision-Centric Autonomous Driving
作者:Yunpeng Zhang, Zheng Zhu, Wenzhao Zheng, Junjie Huang, Guan Huang, Jie Zhou, Jiwen Lu
级别:arxiv 2022
设备:32 NVDIA GeForce RTX 3090 GPUs
论文链接:arxiv.org/abs/2205.0974
代码:github.com/zhangyp15/BE
BEVerse
将图像转到BEV空间进行特征表达,就将3D感知和预测拉到了同一个特征空间,会出现将这两个任务拉到一块并行处理也不意外,BEVerse的目的就是这个。
原始的顺序范式先处理完3D感知任务,在进行预测的,这样的做法有两个缺点:1. 下一个过程会受到上一个过程精度的影响;2. 重复的特征抽取会带来额外的计算损耗。BEVerse通过一个网络实现对特征的抽取(并行的多时间戳多视图特征抽取网络->不同时间戳的特征对齐->时空BEV编码器),然后输入到并行检测头,分割头,motion预测头。
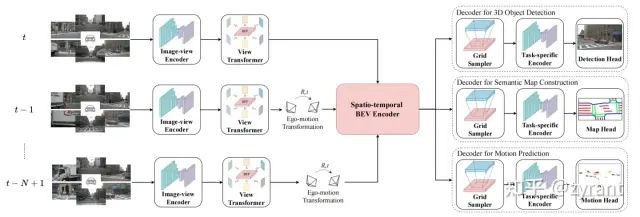
BEVerse
Image-view encoder和view Transformer:直接参考的BEVDet。
时空BEV编码器:首先需要不同时间戳的对齐特征,参考的FIERY的BEV编码,堆叠了一系列的3D卷积,golbal pooling等。
不同的解码器:
Grid sample:因为不同任务需要的BEV分辨率是不同的,因此在应用解码器之前还有一个Grid sample的操作,主要涉及双线性插值操作。
Task-encoder:参考的BEVDet。
解码重点介绍下motion prediction,其他两个用的现成的centerpoint和直接卷积输出即可:
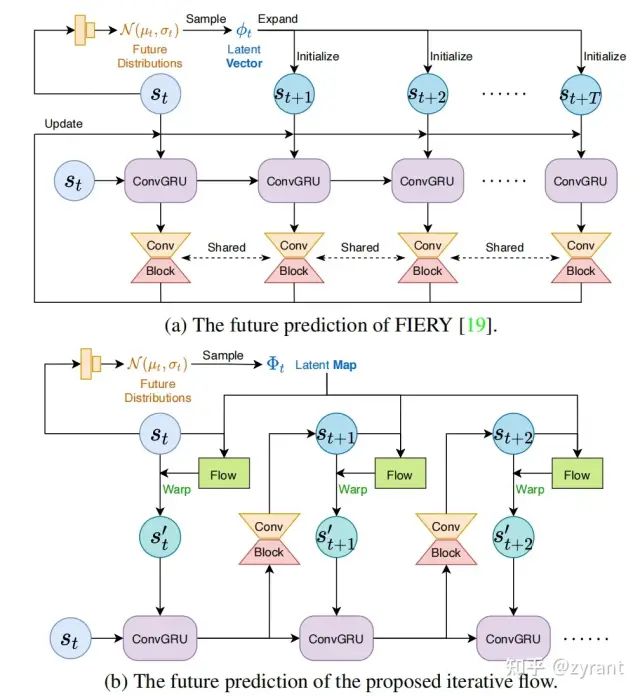
BEVerse改进之处
如上图(a)所示,FIERY首先预测未来高斯分布参数,并采样atent vector,φt,采样的φt,再扩展为latent map(Xmotion × Ymotion × L)形状,并用于初始化未来状态。然后,重复应用ConvGRU(convolutional gated recurrent unit)网络块和瓶颈块,生成未来状态{st+1,st+2,···,st+T}。
BEVerse简化了FIERY的motion predict的过程,认为其有两个不合理之处,1. latent vector是被所有BEV pixel所共享的,不能反应具体不同物体位置的uncertainties。2. 初始的特征状态只和atent vector有关,增加了预测的难度。
BEVerse改进了这两点,1.直接预测latent map而不是latent vector expand之后生成,可以体现不同objects的uncertainties。2. 初始状态是和f当前状态和latent map之间的flow有关,简化了学习的难度。
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird' s-Eye View Representation
作者:Zhijian Liu_, _Haotian Tang,Alexander Amini,Xinyu Yang,Huizi Mao,Daniela Rus, Song Han
级别:arxiv 2022
论文链接:arxiv.org/abs/2205.1354
代码:github.com/mit-han-lab/
多模态的3D目标检测,融合方式可以大致分为以下几种:
融合方式
图a,LiDAR to Camera,这种形式的投影会造成地理结构的损失,比如a图中的红色区域和蓝色区域其实在距离非常的远,投影到图像上变得很近了,这是不合理的,
图b,Camera to LiDAR,语义损失,因为image的特征或者说密度远远高于点云,投影之后大概经由5%的特征能够匹配上点云特征。
BEVFusion提出的方法,BEVFusion除了要完成检测之外还要实现BEV的语义分割,因此proposal-level的融合方式肯定是不行的,其次,是Point-level fusion的方法,也是一样的问题,都是_object-centric _and _geometric-centric_的,归功于现有的BEV 3D感知方法的成功,比如BEVDet,LSS等,BEVFusion在BEV特征空间内进行特征的交互和融合。
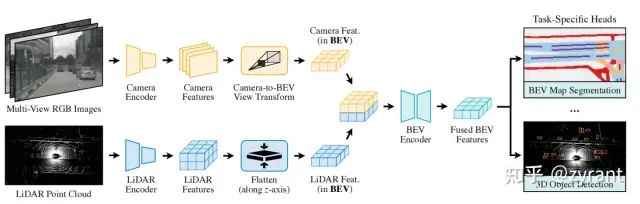
BEVFusion
基于BEVDet,BEVFusion的修改之处是,BEV pooling,将运算速度提升了40倍以上,文中称为Efficient Camera-to-BEV Transformation。
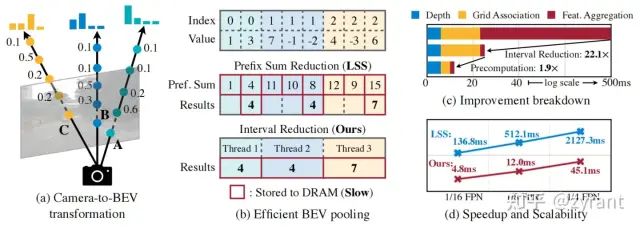
Camera-to-BEV Transformation
将环视图投影到BEV空间,一般采用的是LSS的方法,将深度概率与特征相乘作为gird内的部分特征,然后需要应用BEV pooling根据grid的索引将同一个grid内的特征相加作为bev特征。计算的大量消耗就在这里,因为要计算所有bev grid的points,而points的数量往往是百万级别的(例,63288*61)。
作者采用了两个措施来增加这个过程的效率,分别是Precomputation和Interval Reduction。
Precomputation(预计算):因为相机的内外参数是固定的,因此可以预先计算好每个point对应的3D坐标以及bev grid索引,并事先根据grid indices sort好所有的points,以备后面过程的调用。效果:17ms ->4ms
Interval Reduction(间隔减小):接下来就需要完成聚合同一个BEV grid中的特征。如上图b,现有的方法是采用prefix sum(前缀和,即直接累加,然后通过index边界求sum相减获得最终结果)的方法来计算的,这种方式很不高校,因为其实我们并不需要累加得结果,只需要各个gird索引分支特征聚合结果,因此BEVFusion提出了可以为每个gird分配一个GPU核心,然后并行的计算grid中的结果。效果:500ms -> 2ms
BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection
作者:Yinhao Li, Zheng Ge, Guanyi Yu, Jinrong Yang, Zengran Wang, Yukang Shi, Jianjian Sun, Zeming Li
级别:arxiv 2022
论文链接:arxiv.org/pdf/2206.1009
代码:github.com/Megvii-baseD
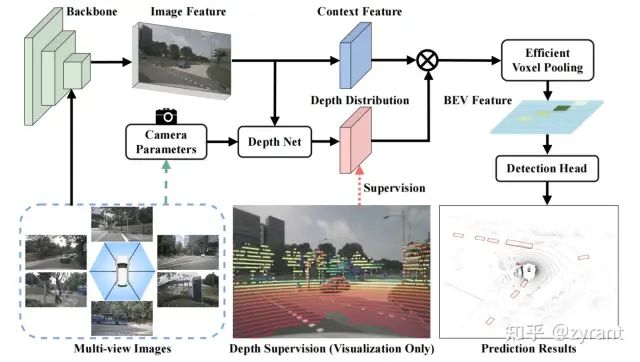
BEVDepth
一句话总结,直接从LiDAR中抽取了depth信息作为辅助监督....,基于BEVDet,主要涉及几个改动:
depth监督直接从LiDAR得到,显式精确的监督,不再是通过3D bbox GT隐式监督
depth校准模块和camera aware depth predict
Efficient Voxel Pooling
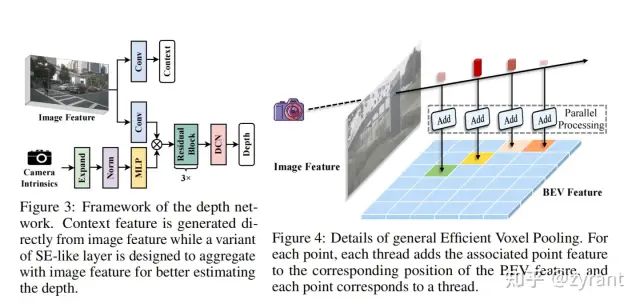
depth network和Efficient Voxel Pooling
1,2两点都是为了优化深度预测,如上图3所示,depth校准模块指的式后面的Res和DCN的部分,目的是拓展模型的感受野使其关注更多的深度信息以及获得动态的感受野范围。camera aware depth predict就是camera intrinsics这一分支,使其作为深度的估计的先验,并通过类似SE的方式对输入图像特征进行自适应的调整。
第3点的操作类似于BEVFusion的bev pooling,主要思想是为每个grid分配一个CUDA线程,该线程用于将特征添加到相应的BEV gird中。
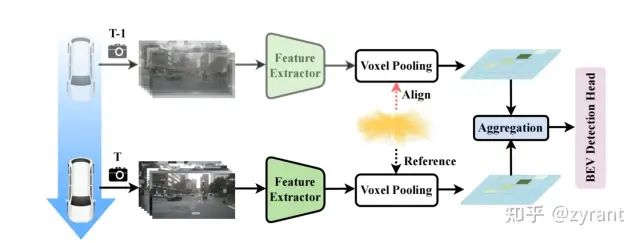
BEVDepth多帧版本
Transformer
DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
作者:Yue Wang,Vitor Guizilini,Tianyuan Zhang,Yilun Wang,Hang Zhao,Justin Solomon
级别:CORL 2021
设备:8 RTX 3090 GPUs
论文链接:arxiv.org/abs/2110.0692
代码:github.com/WangYueFt/de
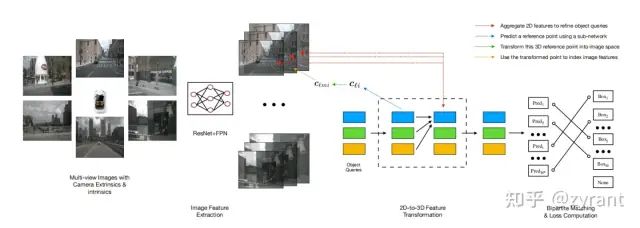
DETR3D
需要的参数:环视图,相机的内外参数
利用环视图作3D目标检测,不像LSS需要将环视图压到BEV空间,直接利用了transformer。
通过几何反投影将二维特征提取与三维物体预测联系起来。
为了收集特定场景的信息,将从这些解码的object queries中一组参考点重新投影到每个摄像机上,并获取由ResNet骨干提取的相应图像特征。
参考点对应得图像特征中收集到的特征通过多头自注意力相互作用。在一系列的自注意层之后,DETR3D从每一层读取边界框参数,并使用受DETR启发的集合到set损失来评估性能。
上图网络结构的解析:
① Resnet+FPN-->独立的提取各个环视图的特征
② data-->object queries-->3D location(投影到图像平面收集图像特征)
③detr检测头
PS:存在多个视图之间存在重叠的问题,即该物体存在于多个视图的问题,解决办法:定义了一个二值特征,由是否参考点投影之后超出了图像平面所决定。
PETR: Position Embedding Transformation for Multi-View 3D Object Detection
作者:Yingfei Liu, Tiancai Wang, Xiangyu Zhang, Jian Sun
级别:ECCV 2022
设备:8 Tesla V100 GPUs
论文链接:arxiv.org/abs/2203.0562
代码:github.com/megvii-resea
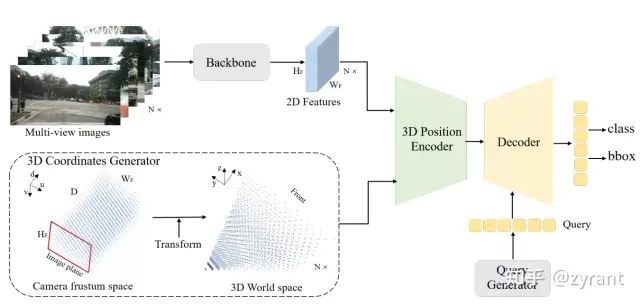
PETR
DETR3D的后续工作,主要的出发点是:Query和feature应该在同一个特征维度,这样框架既简单又优雅。
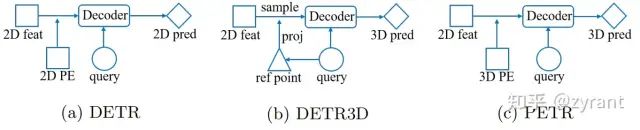
DETR,DETR3D,PETR三者的区别
如上图所示是DETR,DETR3D,PETR三者的区别:
DETR:因为是2D目标检测,他的query和特征都是处于2d维度的。
DETR3D:采用了一种折中的方案,query是3D维度的,但是特征是2D感知的,采用的方法就是上面DETR3D部分说的,这种方法存在显而易见的缺点:1. 特征在reference points对应的图像特征区域编码,获取的特征范围十分local。2. 这个反投影,在投影回来的过程影响应用。
PETR:生成了3D position embedding,然后用3D位置编码和2D特征结合得到3D感知的特征,再和3D维度下的query进行特征交互。
PETR最重要的点就在于3D感知特征的获取。
在获取3D感知的特征之前,需要先了解下怎么生成3D position embedding,毕竟图像上是没有3D坐标的。
PETR中采用的方法与前面提到LSS方法相似,但是又没那么复杂。他并没有对于栅格化后施以不同的权重。
首先如图所示,相机的视锥被离散成(W,H,D),D代表D个离散的深度值(采用和前面的LSS方法一样的60)。
有了深度D之后就能将上述视锥中的坐标利用transformation matrix转到3D空间中。
归一化3D坐标,(nuscenes的范围一般是前后51.2m,深度[-3m,5m])。
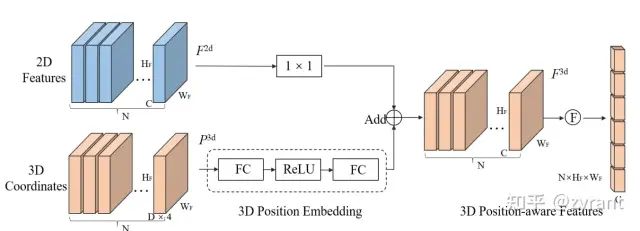
3D position encoder
上图即为3D position encoder的编码过程。
BEVFormer: Learning Bird' s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
作者:Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, Jifeng Dai
级别:ECCV 2022
设备:8 Tesla V100 GPUs
论文链接:arxiv.org/abs/2203.1727
代码:github.com/zhiqi-li/BEV
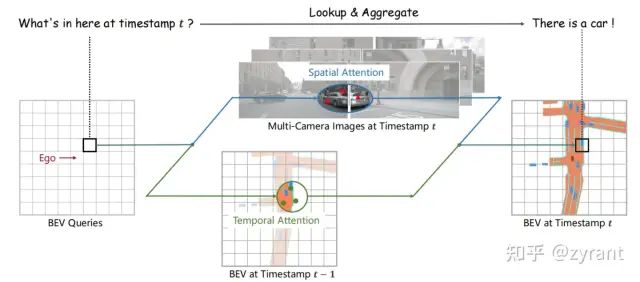
BEVFormer流程简图
先贴一个简单的整体流程图,可以看到主要分为三个部分,BEV Queris,Spatial Attention和Temporal Attention。
本文提出了一种带空间和时间的Transformer基础的在统一的BEV表达下实现的自动驾驶感知任务,主要涉及3D检测和BEV分割任务。BEVFormer通过预定义的在grid sampled的BEV queris来探索时间和空间特征。
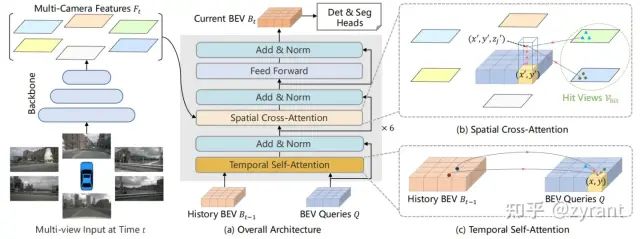
BEVFormer
具体做法:
1.生成grid shape的BEV query。
不像DETR3D直接是3D的query,这里需要转成3D坐标 ,采用了类似pillar的做法,采样了N个高度,这样这个位置会得到N个3D reference points(文中nuscenes的可视范围认为是-5m到3m,每2米采样一个点,共四个。
此外,BEV map的分辨率是200*200,因此共有200*200*4个)
2. spatial cross-attention,聚合环视图特征。
在ROIs应用cross-attention extract空间特征,希望设计一种不依赖深度信息(毕竟2d-3d,深度估计什么的是一个ill-posed的任务)并且能够自适应的生成BEV特征而不是严格依赖于3D先验的方法。
做法:采用了deformable attention,deformable attention该BEV query所投影的2D坐标所涉及到的views。
3. temporal self-attention,从历史的BEV features中抽取特征,有利于速度和强遮挡物体的检测。
首先需要对齐不同帧的特征,以确保同一个grid内对应的real world的坐标是一致的。其次,因为现实场景中物体的运动方向是各式各样的,产生的oofsets也是大不相同的。如何构建同一对象在不同帧之间的精确关联很重要。做法是:采用的deformable attention,在第一个时间戳是没有再前一时间戳的信息了,因此第一帧做的是真正的self-attention。
PS:
为什么用deformable transformer:
使用deformable attention可以减少运算的开销,是的注意力机制从dense变成了sparse,从而是的显存的开销和图像特征大小无关了,只于reference points有关。
一些训练和推理时的不同之处:训练时,作者运用了四个时间戳的特征,因为nuscenes每0.5标记一个场景,因此前三个时间戳作者是随机采样了三个场景。测试时,直接按时间顺序进入网络。



 广告
广告 



最新资讯
-
整车性能测试体系:汽车试验工程的基本框架
2026-03-10 12:54
-
联合国法规R76对轻便摩托车前照灯远近光性
2026-03-10 12:15
-
联合国法规R75对摩托车与轻便摩托车气压轮
2026-03-10 12:14
-
联合国法规R74对L1类车辆灯光与光信号装置
2026-03-10 12:14
-
联合国法规R73对货车侧面防护装置的工程化
2026-03-09 12:14
