




 广告
广告





















































融合时空特征的端到端自动驾驶车辆转向角预测

吕宜生
中国科学院自动化研究所复杂系统管理与控制国家重点实验室副研究员。IEEE智能交通学会管理委员会(BoG)成员,IEEE Transactions on Intelligent Transportation Systems、IEEE Intelligent Transportation Systems Magazine、自动化学报、智能科学与技术学报编委。主要从事人工智能、交通大数据、智能网联交通、智能交通、无人驾驶方向。获得5次会议/期刊优秀论文,获得中国自动化学会自然科学一等奖、IEEE 智能交通系统杰出应用奖、中国自动化学会科学技术进步奖特等奖、北京市科学技术进步奖二等奖。
0自动驾驶是指通过在车辆上加装感知设备和运算单元,提高车辆本身的感知、决策和控制能力,使其达到甚至超越人类的驾驶水平。目前对自动驾驶的研究可分为两种方法:模块化和端到端方法。模块化方法由独立但相互连接的模块构成,每个子模块完成特定的功能;端到端方法可完成从感知输入到车辆控制的直接映射,不同于模块化学习中需要优化人工选择的中间标准如车道线检测,端到端方法可以自我优化以最大程度地提高整体系统性能,是探索自动驾驶技术的一种重要途径。
图1. 自动驾驶软件系统
从某种意义上来说,端到端自动驾驶更接近于人类驾驶行为,比如:对于熟悉的道路和路况,人们容易训练出固定的大脑工作模式,足以应对常规的驾驶任务,即处于典型的端到端驾驶状态。端到端自动驾驶方法有基于模仿学习的方法和基于强化学习的方法。在基于模仿学习的端到端自动驾驶任务中,可借助人类专家给出的决策数据,利用深度神经网络来学习从感知到控制的映射函数。车辆控制指令一般包含转向角和速度(或者油门和刹车)。但由于车辆行驶速度与驾驶员的个人习惯密切相关,同时摄像头采集帧率也是影响速度预测的关键因素,故本文主要研究基于模仿学习的端到端自动驾驶中车辆转向角预测问题。

图2. 基于模仿学习的端到端自动驾驶转向角预测
1相关工作
近年来,比较有影响力的工作是2017年NVIDIA开发的端到端深度卷积神经网络PilotNet,该工作通过卷积神经网络(CNN)模型完成从图像到车辆转向角的映射。在NVIDIA的后续工作中,他们构建了可视化工具,可视化结果显示,PilotNet能够自发地学会识别车道标记、道路边缘等对驾驶至关重要的道路特征。

图3. NVIDIA PilotNet系统平台
驾驶行为是动态的,而只包含静态空间特征的单帧图像丢掉了动态的时间特征。因此,在动态实时环境中自主驾驶的车辆需要具有时空感知能力,综合考虑时间与空间信息对于精确的车辆运动控制至关重要。目前,端到端自动驾驶领域的时空模型研究工作主要集中在使用循环神经网络和3D卷积网络。此外,有研究将双流卷积网络(广泛应用在视频行为识别领域)应用到端到端自动驾驶,发现从基于运动的光流中学习自动驾驶车辆控制能够取得较好的效果。光流(Optical Flow)定义为视频图像中某个位置的像素点在相邻两帧图像之间的位移矢量,它可以捕获视频中相邻帧之间的时间动态,是一种强大的视觉表征,且时间流特征易于解码。
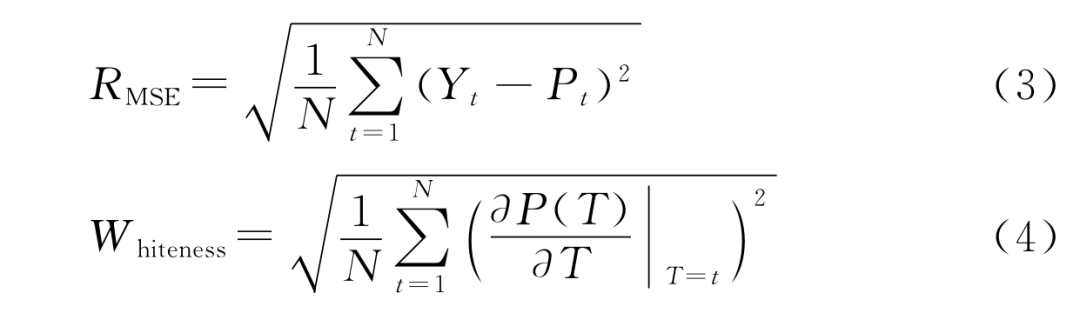
图4. 相邻两帧RGB图像提取光流图像
但光流图像的时间信息仅来自于当前帧与上一帧图像,没有解决驾驶运动过程中连续多帧驾驶场景之间的时间建模问题。为此,本文提出一种时空融合的端到端自动驾驶车辆转向角预测模型,在双流卷积网络(Two-Stream CNN)的基础上引入门控循环单元(GRU)网络,利用RGB图像、基于运动的光流图像和门控循环单元网络来融合连续多帧驾驶场景的空间特征与时间特征。
2方法介绍
本文提出的结合门控循环单元的双流卷积模型(Two-StreamC-GRU)可以拆解为基本的双流卷积网络和门控循环单元网络。基本双流卷积网络将RGB图像和光流图像作为多模态输入数据,首先利用两组卷积网络分支提取特征,一组分支从RGB图像中提取空间特征,另一组分支从光流中学习时间特征;然后利用门控循环单元网络对具有短时依赖关系的特征进行建模,以更好地提取、分析时间特征;最后,融合时间与空间特征,馈入全连接层输出转向指令。
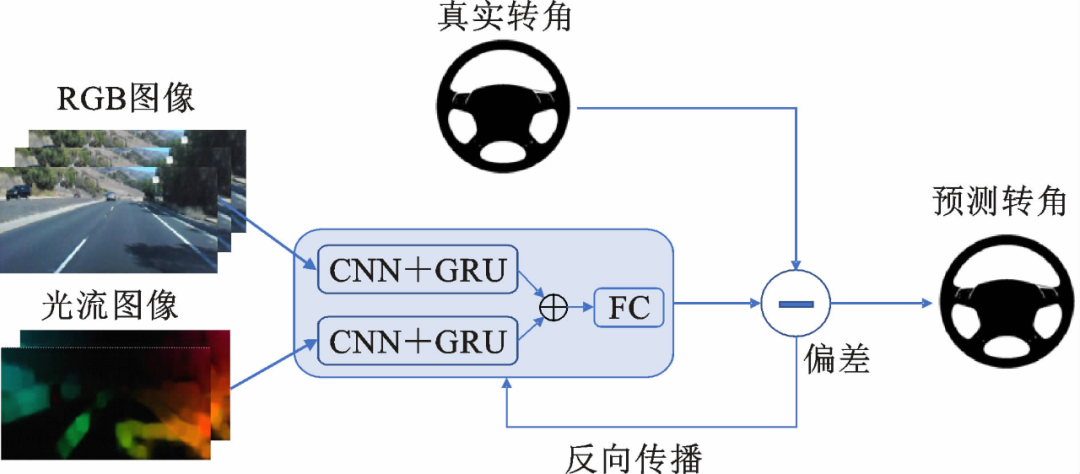
图5. Two-Stream C-GRU模型系统整体框图
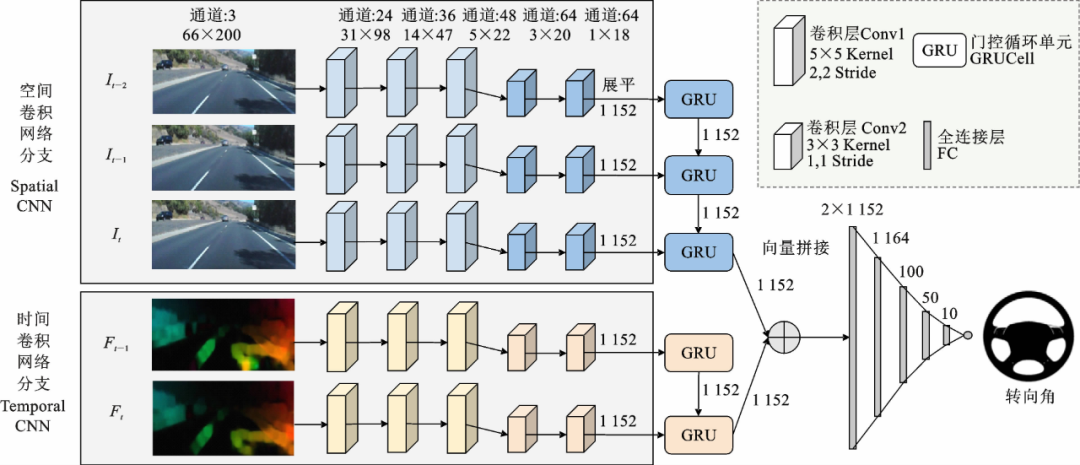
图6. Two-Stream C-GRU模型网络结构
本文卷积网络层仿照PilotNet结构进行构建,分别在空间卷积网络分支和时间卷积网络分支的最后添加GRU网络。GRU控制着以隐藏状态编码的前一帧图像特征以及后一帧图像特征的信息流向。最后将两个分支输出的当前状态进行融合,完成对三帧RGB图像以及对应两帧光流图像的时间关系建模。相比基本的双流卷积网络,本文提出的Two-Stream C-GRU网络模型获取的时间动态不仅依赖于表示前后两帧图像位移的光流,也与连续多帧图像相关,能够进一步强化连续三帧图像之间的时间特征。
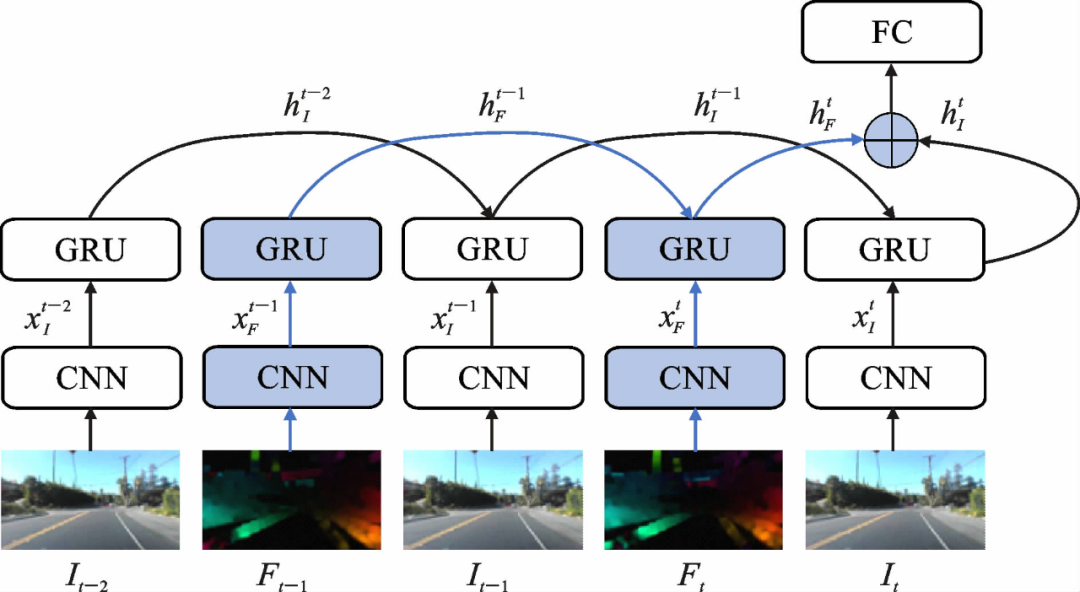
图7. 添加门控循环单元网络的模型结构
3模型可视化
为了深入了解端到端自动驾驶系统内部如何做出决策以及进一步改进系统,NVIDIA和Google联合开发了一种VisualBackProp算法,VisualBackProp能够突出显示原始图像中对确定预测转向角作用最显著的部分,将这些显著图像部分称为显著对象。不同于以往需要求解梯度的可视化卷积网络算法,该算法依据卷积神经网络随着网络层数的加深提取到的信息越关键,但特征图分辨率也随之下降这一特点,采用将最深层平均化之后的特征图,通过反卷积进行放大操作,然后与上一层平均化的特征图点乘得到中间掩膜,再重复之前的反卷积与点乘操作,不断继续下去,直到可视化的掩膜大小与输入图像的大小相等。
本文对PilotNet、基本双流卷积网络以及结合GRU的双流卷积网络的空间卷积网络分支和时间卷积网络分支分别使用VisualBackProp算法进行可视化,并对其进行热力图处理,以直观地比较分析卷积网络内部如何做出决策,如下图所示。

图8. 空间卷积网络分支可视化图

图9. 时间卷积网络分支可视化图
观察发现:
(1)无论是单流网络还是双流网络,对于地面道路、车道线均有明显关注,这表明神经网络在仅以图像和转向角作为训练信号的情况下,学会了自主检测有用的道路特征;
(2)对比单流网络和双流的两个分支网络发现,提取光流图像特征的时间卷积网络分支比提取RGB图像特征的空间卷积网络分支更能捕捉道路边界和车道线等特征点,这也侧面说明双流卷积网络确实优于单流网络,能够增强端到端学习;
(3)相较于基本双流卷积网络,本文提出的Two-Stream C-GRU模型的空间卷积网络分支与时间卷积网络分支关注部分更接近,反映出添加的GRU网络可以使得双流网络的两个分支的时空特征更好地融合。
4实 验
本实验采用由美国南加州大学研究人员在洛杉矶郊区驾驶采集得到的数据集。不同于自动驾驶领域的其他真实数据集如Udacity、DeepDrive、Comma-ai等,该数据集的驾驶场景出现人类规划的驾驶行为的频率较少,更有利于端到端网络训练。此数据集包含以20Hz采集到的视频帧共十万余张,以及对应的方向盘转角。本实验从第一次采集的数据集中选取了连续的约4.5万张视频帧用于网络训练及参数调整,另外从第二次采集的数据集中选取两段分别作为测试集1和测试集2,每个测试集约2万张视频帧。

图10. 数据集部分驾驶场景
5评价指标
对于转向角预测问题,预测值与真实值的偏差是衡量模型好坏的重要标准,且需要警惕较大的偏差,因此本文选择均方根误差(Root Mean Square Error, RMSE)用于衡量预测精度。同时,使用另一个指标Whiteness来度量预测转向信号的稳定度。Whiteness的值越小,预测的转向变化越缓慢,平稳性越好。
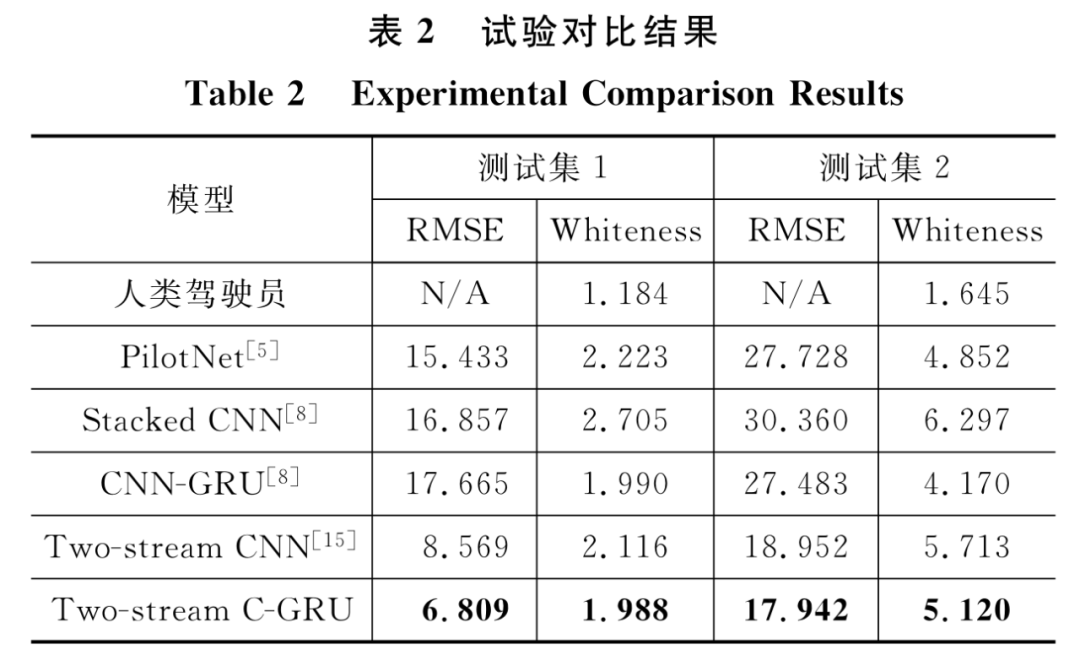
将训练好的模型分别在测试集1和测试集2上进行测试,表2给出了模型的测试结果。相比基本的双流卷积网络,Two-Stream C-GRU模型在测试集1上精度提高20%,稳定度提高6%,在测试集2上精度提高5%,稳定度提高10%。这表明当双流卷积网络结合GRU时可以使模型融合更多的时间信息,获得更强大的运动感知和时序依赖关系提取能力。相较于其他时空模型,Two-Stream C-GRU模型利用RGB图像、光流图像和GRU网络融合驾驶场景的空间特征与时间特征,提高了模型预测精确度与信号稳定度。
从测试集中随机选取一部分视频帧,将预测的方向盘转角值与真实值绘成曲线图,黄线代表真实值,蓝线代表预测值,如下图所示。
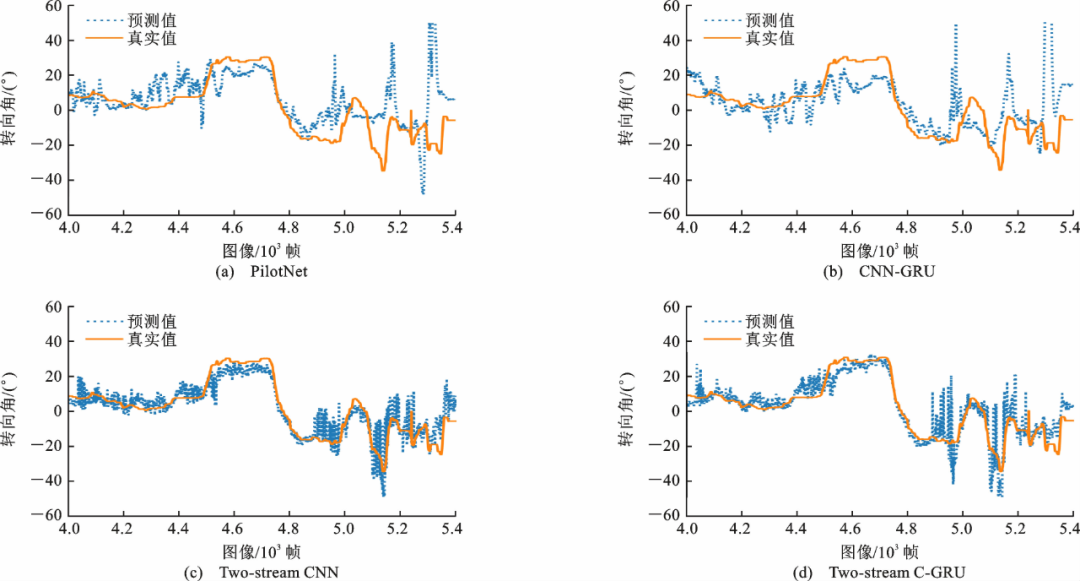
图11. 转向角度预测曲线(部分)
6消融试验
为了验证综合处理空间与时间信息能够提升动态环境中自主驾驶车辆的转向角预测精度以及选择出模型的最佳输入图像帧数,本节围绕模型的时间特征提取网络的不同组成部分(光流和GRU)设计了2组消融实验:
(1)针对光流的消融实验
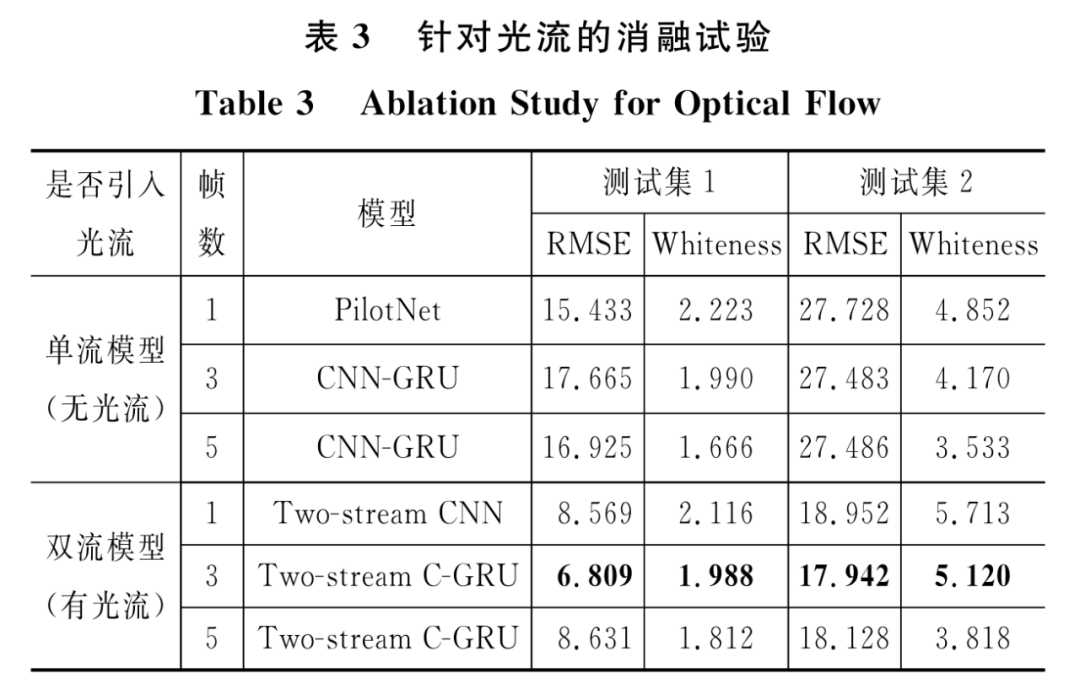
表3给出了两种不同的网络结构在有无光流条件下的实验对比结果,其中加粗部分为Two-Stream C-GRU模型。结果表明:引入光流的双流卷积网络在预测精度方面相比单流卷积网络模型得到大幅度提升,说明包含时间动态的光流是一种强大的视觉表征,且容易被卷积神经网络学习,证明了双流卷积网络是一种利用时空信息增强端到端自动驾驶的有效方法。
(2)针对循环神经网络的消融实验
表4给出了单流与双流模型的循环神经网络分别为LSTM和GRU的实验对比结果,其中加粗部分为Two-Stream C-GRU模型。结果表明:虽然LSTM与GRU网络均可以有效地建模动态的时间行为,但除了单流模型且处理三帧图像的情况,其余情况下GRU的预测精确度均优于LSTM。
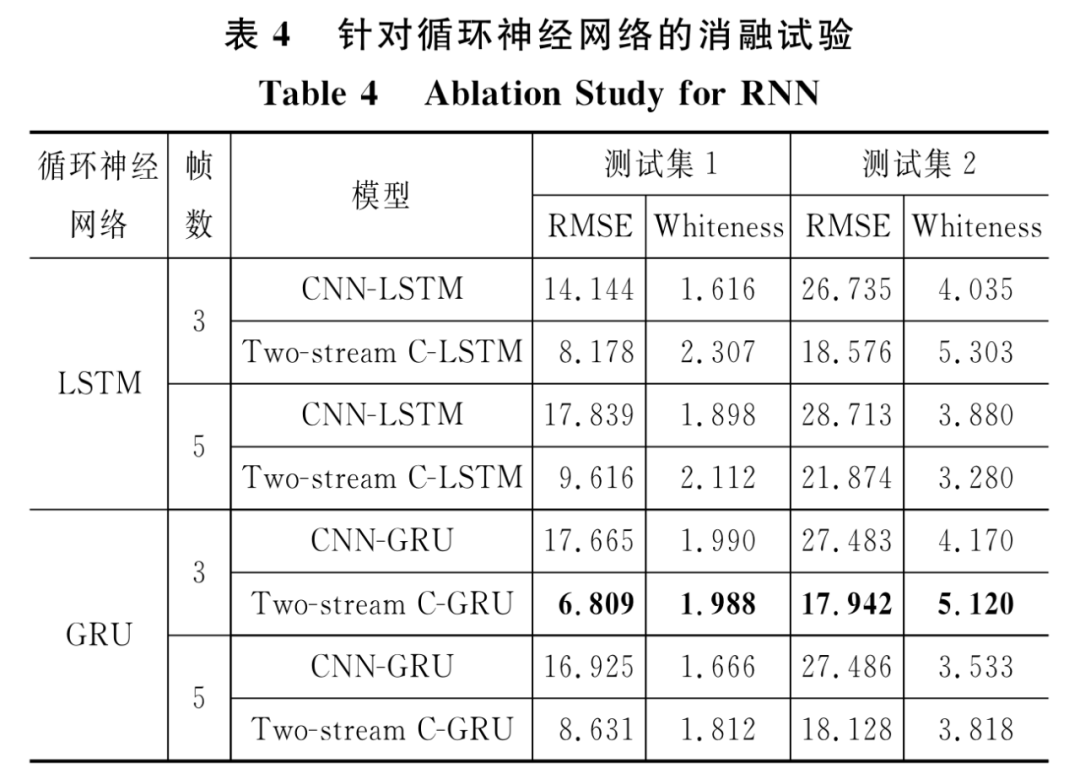
基于以上消融实验,发现综合空间与时间序列信息,可实现对端到端自动驾驶车辆的准确控制。但值得注意的是,对于本文所提出的模型,输入图像的帧数并不是越多越好。随着模型的输入图像帧数的增加,转向信号的平稳性得到进一步提升,但预测准确度有所下降。本文实验表明对于实时动态的自动驾驶场景,三帧图像即可满足对时间信息的需求。
7结 语
本文提出了一种融合时空特征的端到端自动驾驶车辆转向角预测模型Two-Stream C-GRU。主要结论如下:
(1)融合原始图像空间信息与光流图像时间信息的双流模型可以显著提高自动驾驶车辆转向角预测的准确性,然而仅使用单帧光流图像并不足以分析动态驾驶场景的时间相关性。因此本文设计了一个与GRU网络相关联的端到端双流网络结构,利用RGB图像、基于运动的光流图像和GRU来融合连续多帧驾驶场景的空间特征与时间特征。实验结果表明本文提出的Two-Stream C-GRU模型比现有其他时空模型有了显著的改进。
(2)在端到端自动驾驶车辆转向角预测方面,双流模型采用GRU的效果优于LSTM,且GRU参数量和计算量更少。对于模型的输入帧数而言,图像帧数并不是越多越好。在本文的实验中,三帧图像即可满足对时间信息的需求。
(3)采用VisualBackProp算法分别对双流卷积网络的空间流分支网络和时间流分支网络进行可视化,发现相较于基本双流卷积网络,本文提出的Two-Stream C-GRU模型的空间卷积网络分支与时间卷积网络分支关注部分更接近,反映出添加的GRU网络可以使得双流网络的两个分支的时空特征更好地融合。
(4)未来可以进一步探讨时空特征融合的方式,对模型性能进行优化。需要指出的是,本文所用于模型输入的光流图像是额外计算的,未来的工作应采用端到端网络实时有效地估计光流,此外,还可以集成专门的传感器从而直接获得实时光流。
本文主要内容出自于《中国公路学报》2022年第3期 AI赋能网联车辆·大数据驱动智能交通专刊
点击题目查看全文:
吕宜生, 刘雅慧, 陈圆圆, 朱凤华. 融合时空特征的端到端自动驾驶车辆转向角预测[J]. 中国公路学报, 2022, 35(3): 263-272.



 广告
广告 



最新资讯
-
东扬精测|CLNB 2026 苏州|世界顶尖的测试
2026-04-03 09:48
-
EA-BIM 20005多通道电池阻抗测试仪如何赋能
2026-04-03 09:46
-
自动泊车测试进入厘米级时代——从最新测试
2026-04-03 09:10
-
真正决定城市体验的,不是硬件,而是控制系
2026-04-02 14:26
-
LabVIEW传奇工程师亲临现场,NI测试测量技
2026-04-02 14:24
