




 广告
广告





















































自动驾驶中雷达感知:时域关系的充分利用

arXiv上2022年4月上传的论文“Exploiting Temporal Relations on Radar Perception for Autonomous Driving“,基本是Brandeis大学的学生在MERL的实习生工作。

该文考虑雷达传感器在自动驾驶中的目标识别问题。与激光雷达传感器相比,雷达在全天候条件下对自动驾驶的感知具成本高效和具备鲁棒性。然而,雷达信号在识别周围目标时,角分辨率和精度较低。为了提高车载雷达的能力,这项工作在连续自车为中心的BEV雷达图像帧中充分利用时间信息进行雷达目标识别。作者利用目标存在和属性(大小、方向等)的一致性,提出一个时域关系层(temporal relational layer)对连续雷达图像中目标之间的关系明确地建模。在目标检测和多目标跟踪方面,该方法与其他几种基准方法相比具有优越性。
车载雷达主要使用FMCW检测目标,并在多个物理域上生成点云。其原理如图所示:
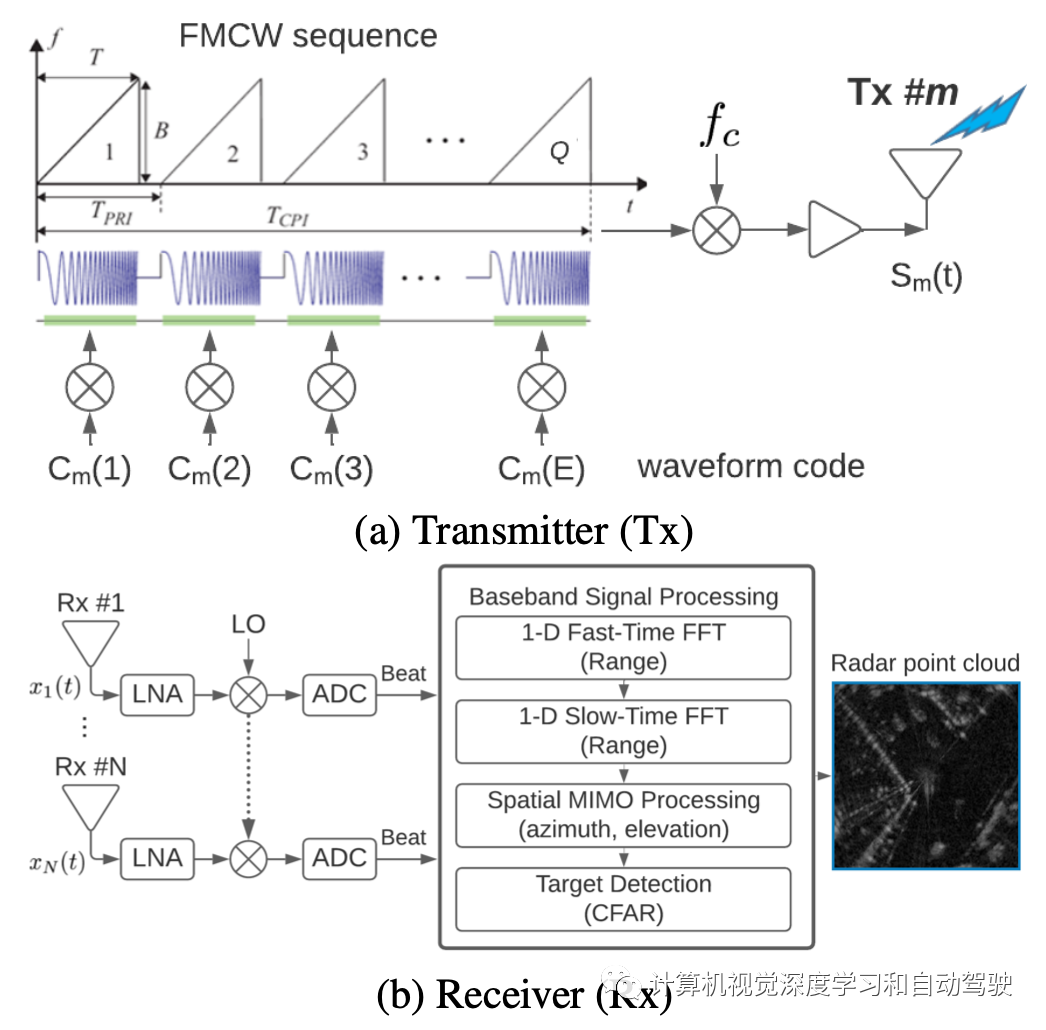
雷达通过M个发射天线之一发射一组FMCW脉冲信号即
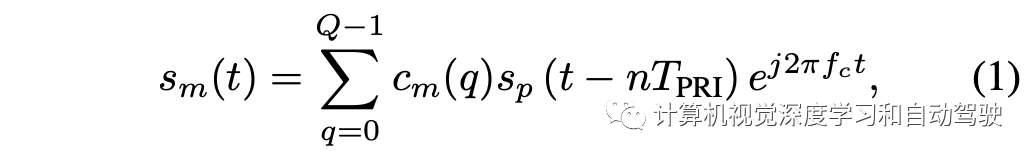
具有径向速度vt和远场空间角(即方位角、仰角或同时存在)距离在R0范围内的一个目标,在N个接收器射频链(包括低噪声放大器LNA、本地振荡器LO和模数转换器ADC)的每一个,所接收到的FMCW信号做振幅衰减和相位调制。
基带信号处理模块(包括距离、多普勒和空域的快速傅里叶变换FFT)捕获来自目标的调制信号,生成一个多维谱。频谱与自适应阈值进行比较,即恒定虚警率(CFAR)检测,可以在距离、多普勒、方位和仰角域生成雷达点云。
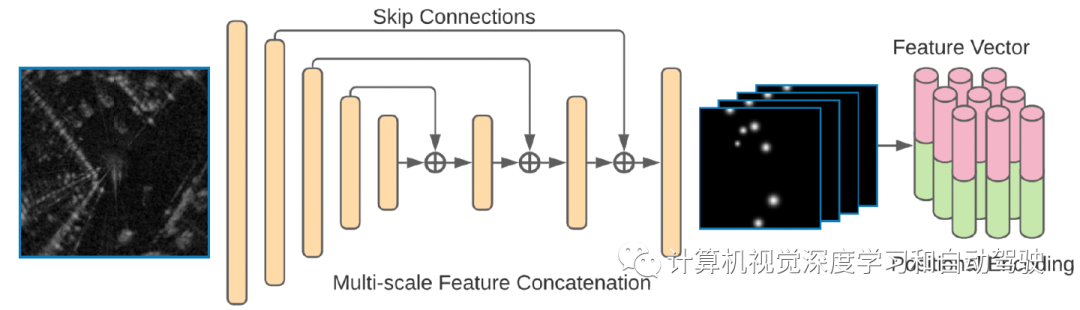
如图是所提出的具有时序性雷达目标识别框架:从左到右,该方法取两个连续的雷达帧,并从每一帧提取时域特征;然后,选择可能是潜在目标的特征,并学习它们之间的时域一致性。最后,对更新后的训练特征进行一些回归分析。
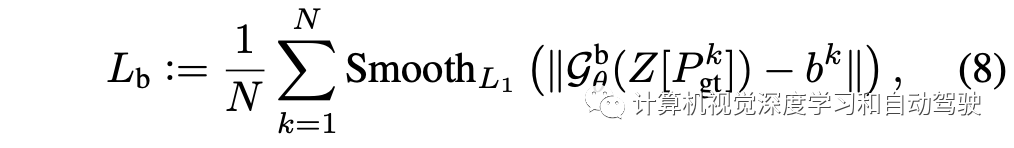
通过主干神经网络,输入两帧得到特征表示
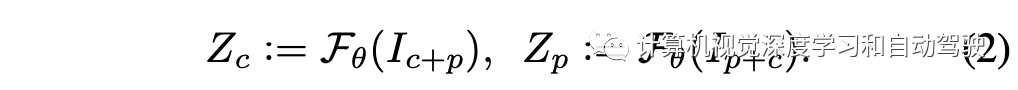
为了在特征表示中联合使用高级语义和低级细化细节,神经网络中不同尺度特征之间建立跳连接。具体地说,对于一个跳连接,在一个深层上采样池化特征,通过双线性插值将其大小与以前的浅层特征对齐。一系列操作,包括卷积、非线性激活和批量标准化(BN),随后应用于该上采样特征。接下来,沿通道维度将上采样特征与浅层特征连接。三个跳连接被插入到网络中,推动特征在四个不同层接纳语义。
如图是在主干网插入的几个跳连接,收集不同尺度特征进行预测。所选择用于时域关系建模的特征附上位置编码,揭示目标的位置。
设计一个时域关系层模拟连续帧中潜在目标之间的相关性和一致性。该时域关系层从两个帧接收多个特征向量,每个向量表示雷达图像中的潜在目标。
应用一个滤波模块,挑选出前K个潜在目标特征,其中Zc中的潜在目标坐标为:

类似地,可以得到Zp中的潜在目标坐标Pp。这样所选特征组成的矩阵为
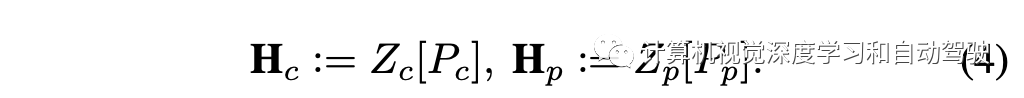
时域关系层的输入即记作
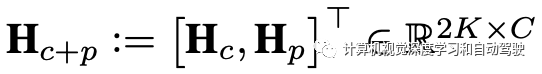
在Hc+p传递到时域关系层之前,在特征向量中补上位置编码。由于CNN具有平移不变性,卷积神经网络在输出特征表示中不包含绝对位置信息。然而,位置在目标时域关系中是至关重要的,因为在两个连续帧中处于特定空域距离的目标更有可能关联,并且共享相似目标的属性。同一目标之间的空域距离取决于帧率和车辆运动,可以通过数据驱动的方法进行学习。
时域关系层的输出特征为:采用Transformer结构
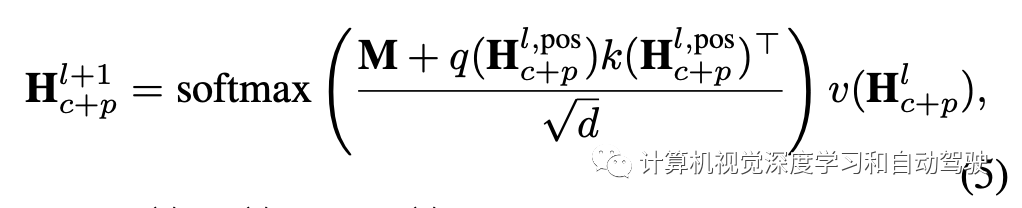
掩码矩阵定义为:
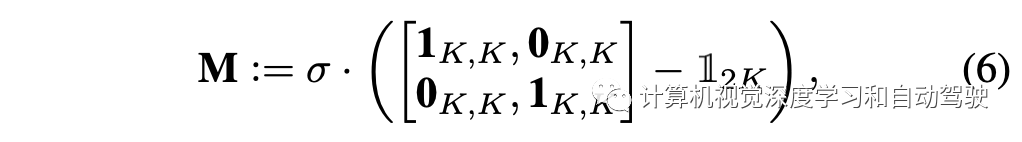
自注意机制背后的逻辑是,由于一个目标可以移出范围,所以在连续帧中不能始终保证同一目标同时出现,因此,当一个目标只在一帧中丢失时,自注意是可取的。值得注意的是,位置编码只附加给key和query,而不是value,因此输出特性不涉及位置。其他技术细节遵循Transformer的设计,这里省略了详细描述。
关系建模是由多个具有相同设计的时域关系层构成的。最后,将更新后的特征Hc和Hp从Hc+p中分离出来,并在Pc和Pp的相应空间坐标中将特征向量重新填充到Zc和Zp。
在模型训练时,从热图中选取目标的中心坐标,并通过回归从特征表示中学习其属性(即宽度、长度、方向和中心坐标偏移)。
将2D径向基函数(RBF)核置于每个真值目标的中心,生成真值热图,而RBF核的参数σ与目标的宽度和长度成比例。考虑到雷达图像中目标的稀疏性,用focal loss来平衡真值中心和背景的回归,并驱动预测的热图来近似真值热图,即
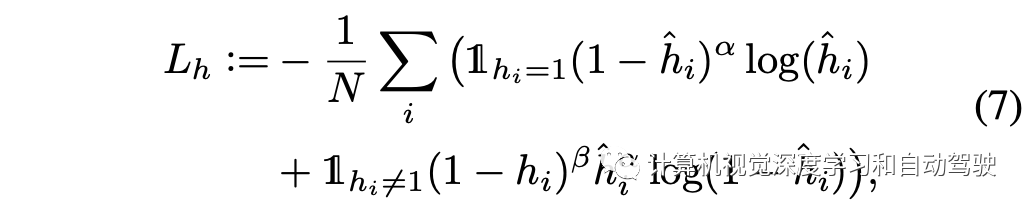
注:在模型推理中,在热图上设置一个阈值,以区分目标中心和背景。应用NMS,可避免过多边框出现。
目标宽度和长度的回归损失项为:
其中L1平滑损失为
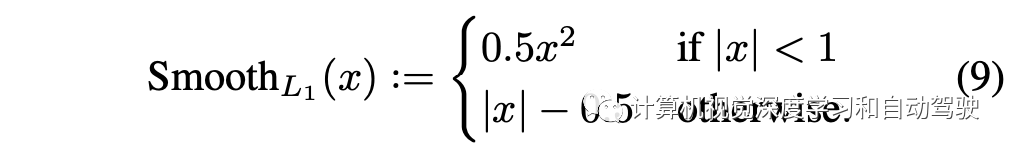
目标姿态的回归损失为
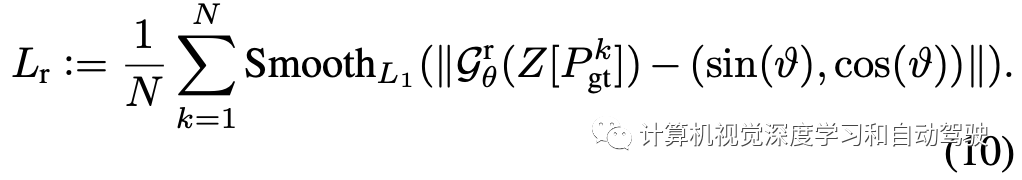
主干网络中下采样会造成目标中心坐标偏离。这里记作
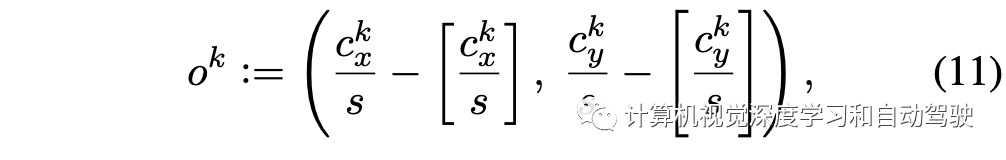
其回归损失为
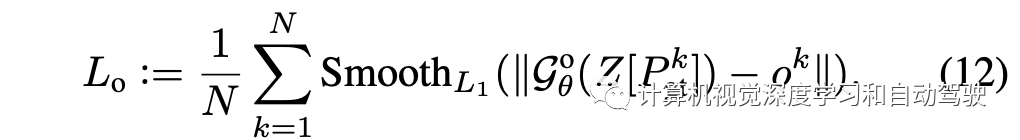
这样总损失为
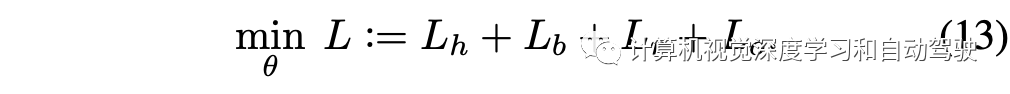
每个训练步骤,都会计算损失L,并同时对当前帧和前一帧进行反向运算。在当前帧中的目标,接收过去的信息以进行识别。另一方面,从前一个帧角度来看,目标会利用来自未来最近帧的时间信息。因此,可以将优化视为对两个连续帧的双向后向-前向训练。目前,没有将当前的框架扩展到多个帧,因为一个中间帧没有时域特征提取所需要的输入图像适当序贯次序(既不是从过去到未来,也不是从未来到过去),并且会降低训练效率。
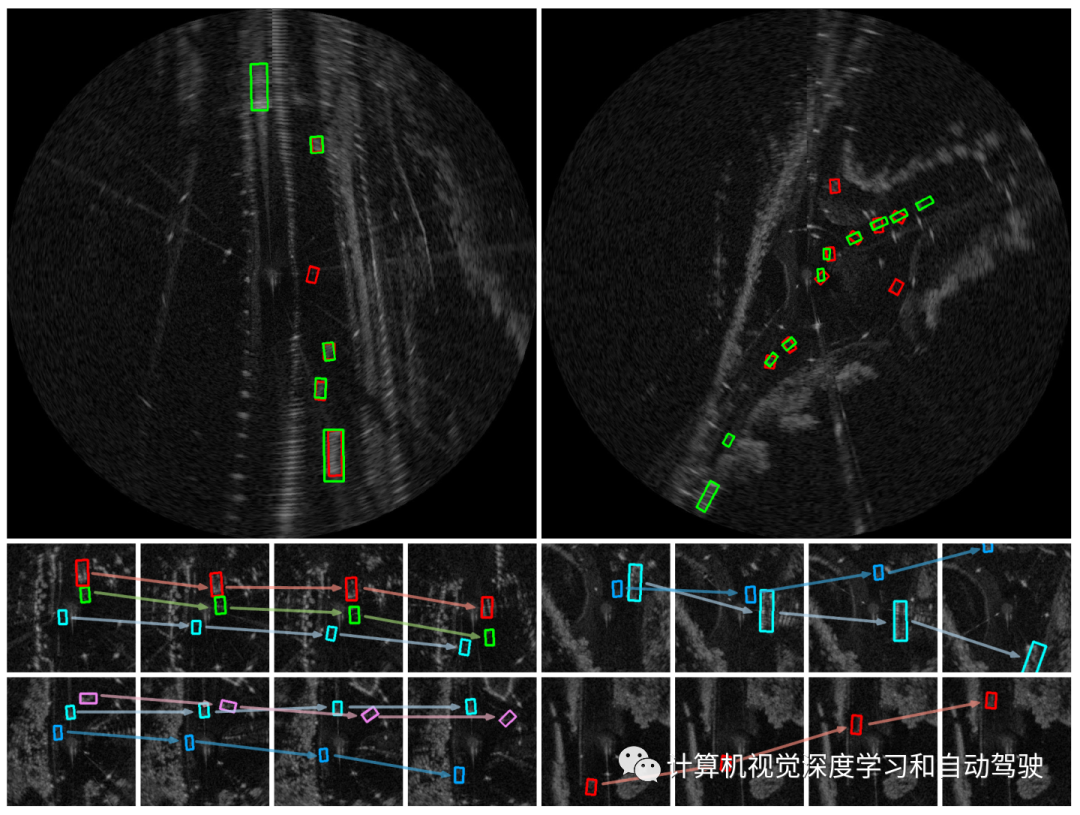
对于多目标跟踪,在中心特征向量添加一个回归头,预测当前帧和前一帧具有相同跟踪ID的目标中心之间的2-D运动偏移。简单地,用欧氏距离来实现跟踪解码中的关联。
如下是MOT的解码算法伪代码:

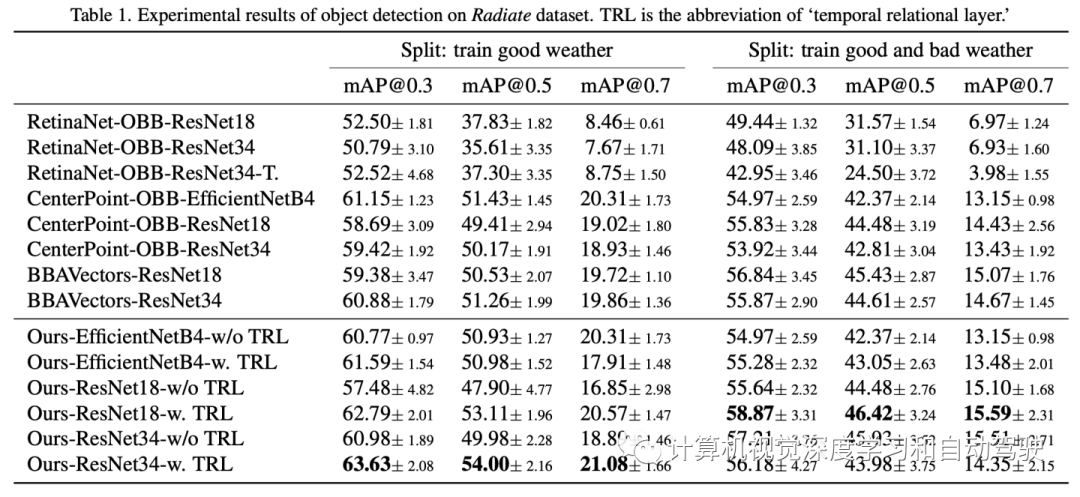
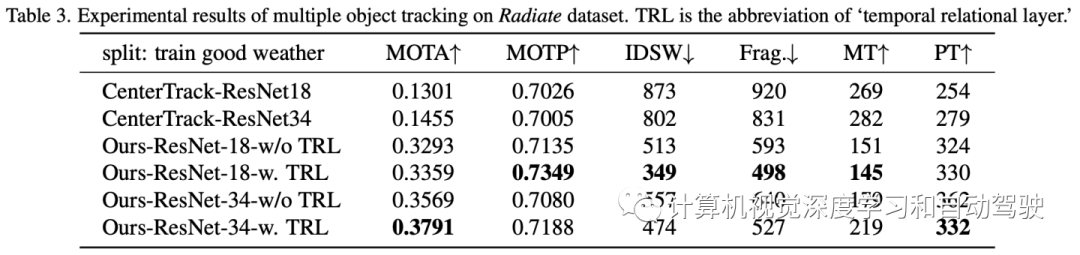
数据集Radiate,包括了在恶劣天气(包括太阳、夜晚、雨、雾和雪)下录制的视频序列。驾驶场景从高速公路到市区,各不相同。数据格式为从点云生成的雷达图像,其中像素值表示雷达信号反射的强度。Radiate采用机械扫描方式的Navtech CTS350-X雷达,提供360度4赫兹高分辨率距离-方位(range-azimuth)图像。目前,雷达无法提供多普勒或速度信息。整个数据集共有61个序列,划分为三部分:好天气下训练(31个序列,22383帧,仅在好天气,晴天或阴天),好天气和坏天气(12个序列,9749帧,好天气和坏天气)条件下训练以及测试(18个序列,11305帧,各种天气条件)。分别在前两个训练集上训练模型,并在测试集上进行评估。
实验结果如下:

- 下一篇:纯电动汽车动力电池包布置规范
- 上一篇:某纯电动车开空调车内振动噪声分析与优化



 广告
广告 



最新资讯
-
展会预告 | TCT亚洲展倒计时!思看科技五大
2026-03-10 20:50
-
整车性能测试体系:汽车试验工程的基本框架
2026-03-10 12:54
-
联合国法规R76对轻便摩托车前照灯远近光性
2026-03-10 12:15
-
联合国法规R75对摩托车与轻便摩托车气压轮
2026-03-10 12:14
-
联合国法规R74对L1类车辆灯光与光信号装置
2026-03-10 12:14
