




 广告
广告





















































自动驾驶的安全-紧要场景生成方法综述
2022-02-15 19:03:29· 来源:计算机视觉深度学习和自动驾驶 作者:黄浴

该文是2022年2月7日在arXiv上传的论文“A Survey on Safety-Critical Scenario Generation for Autonomous Driving – A Methodological Perspective“,作者来
该文是2022年2月7日在arXiv上传的论文“A Survey on Safety-Critical Scenario Generation for Autonomous Driving – A Methodological Perspective“,作者来自CMU。

由于感知和决策技术的进步,自动驾驶系统在过去几年中得到了长足的发展。在现实世界中自动驾驶大规模部署的一个关键障碍是安全评估。大多数现有的驾驶系统仍然是采用日常占绝大多数的自然场景或启发式生成的对抗场景进行训练和评估。然而,大量汽车需要极低的碰撞率,这表明在现实世界中收集的安全-紧要场景非常少见。因此,人工生成场景的方法对管理风险和降低成本来说至关重要。
本篇综述主要关注安全-紧要场景生成算法。首先对现有算法进行全面分类,即数据驱动生成、对抗生成和基于知识的生成。然后,文章讨论场景生成的有用工具,包括仿真平台和软件包。最后,讨论扩展到当前工作的五大挑战——准确性、效率、多样性、可迁移性、可控性,以及这些挑战带来的研究机遇。
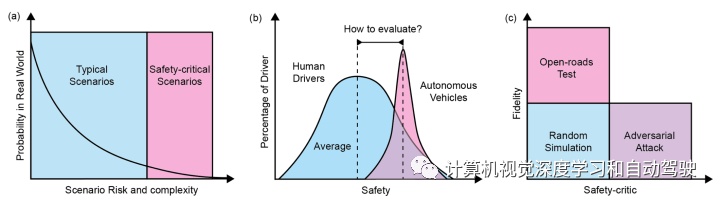
如图是自动驾驶汽车评价的概览:(a) 现实世界中发生的大多数场景都是典型场景,安全-紧要场景非常少见。(b) 自动驾驶汽车的平均安全性应该比人类驾驶员高,但差距不容易评估和测量。(c) 不同安全-紧要场景生成方法之间比较。大多数现有方法不能同时满足准确性和安全-紧要评估指标。
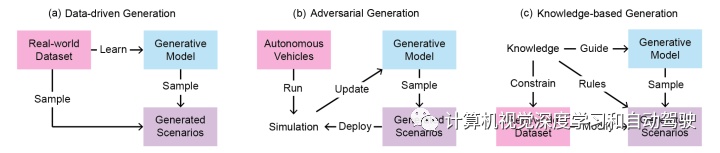
关于安全-紧要场景的生成方法类别如下图所示:
驾驶场景定义为三个集合的组合,x∈ X={S,D,B}。S表示静态环境,包括道路形状、交通标志和其他静态目标。D表示动态目标的初始条件和属性。B表示动态目标的序列行为。
通常有多种选择来表示场景,取决于要评估的系统。如果目标系统是一个感知模块,要采用高维传感数据,如图像和激光雷达点云,而直接生成高保真观测数据非常困难。另一种方法是利用光线投射算法的渲染引擎(比如differential renderer)和激光雷达模拟器生成高维数据。如果想评估一个运动规划或控制系统,可以转向低维,比如用动态目标的轨迹或策略模型。轨迹表示不如使用策略模型灵活,但轨迹表示的场景更可控。
安全-紧要场景的生成可以描述为:

这个优化问题不容易解决,主要有两个方面:第一个是分布pθ(x)的表示,第二个是度量f(x)的选择。
要生成安全-紧要场景,最重要的因素是场景的风险。风险水平主要通过场景中自动驾驶车辆与目标之间的相互作用来反映,用距离来自然描述——距离小意味着碰撞风险高。这种直觉也可以转化为其他指标,如撞击时间(TTC):
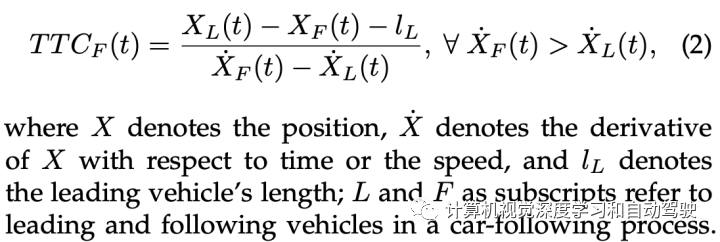
如图是三种安全-紧要场景生成方法的说明。(a) 数据驱动方法仅用收集的数据直接或通过生成模型进行采样。(b) 对抗性方法使用来自仿真部署中的自动车辆反馈。(c) 基于知识的方法主要利用来自外部知识的信息作为生成的约束或指导。
数据驱动方法主要分为两部分:第一部分直接从数据集x∼ D中采样,复制现实世界的数据,这通常会遇到罕见问题;第二部分是使用密度估计模型(例如深度生成模型)pθ(x)来学习场景分布,生成未见过的场景;通常这些模型的学习目标是最大化对数似然
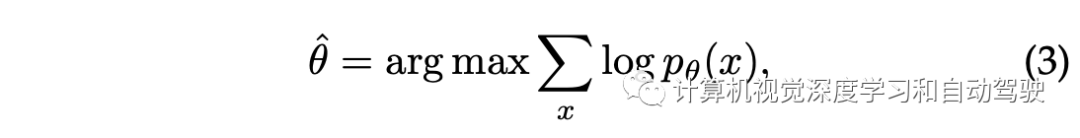
采样过程由来自随机噪声的x∼ pθ(x)进行。
一种直观的生成方法是直接从收集的数据集中采样,该数据集从道路测试数据中复制场景。根据采样前和采样中使用的不同技术,分为以下三组:数据重放、聚类和随机扰动。
而密度估计法,考虑随分布的驾驶场景,用收集到的数据学习密度模型来近似这种分布。根据使用的密度模型,这类算法又分为三类:贝叶斯网络、深度学习模型和深度生成模型。
对抗生成法由两个组件组成,一个是生成器,另一个是牺牲者模型,即自动驾驶车(AV)。然后,这个目标生成过程可以表述为

对抗生成法主要集中在特定的小场景集,所以通过增加分布H(x)的约束或熵来考虑多样性。由于考虑自动驾驶车的影响,这种类型也被称为车在环(VIL)测试。由于自动驾驶系统由多个模块组成,根据牺牲者模型类划分这些对抗生成方法。当模型用于单帧输入时,例如目标检测和分割,只需要生成静态场景。当牺牲者模型需要一个连续测试用例时,就生成包含所有目标运动的动态场景。
当工作的目标是评估规划和控制模块时,场景需要是动态的和连续的。对于这类算法,根据场景的灵活性将当前的工作进一步分为两类:
-
第一种是控制场景的初始条件(例如,初始速度和触发位置)或在开始时提供整个轨迹。其优点是搜索空间维数低,所需计算资源少。
-
第二种是使用策略模型序贯控制动态目标,其中目标的行为受自动驾驶车(AV)的影响。这种类型通常被描述为强化学习(RL)问题,其中AV属于环境,生成器是可以控制的智体。
基于知识的方法是,考虑将外部领域知识纳入生成过程。首先探索基于规则的方法,人工设计场景的结构和参数。基于学习的方法,使用明确的知识来指导生成。假设可以从专家那里获得特定的领域知识K,那么可以用

其中,从条件分布pθ(x | K)中采样场景。此外,可以用K作为约束来影响现有场景:
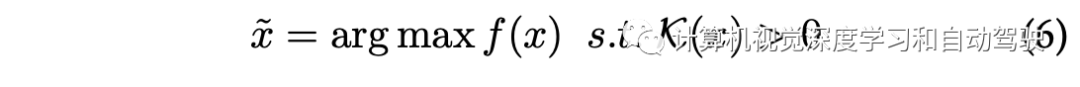
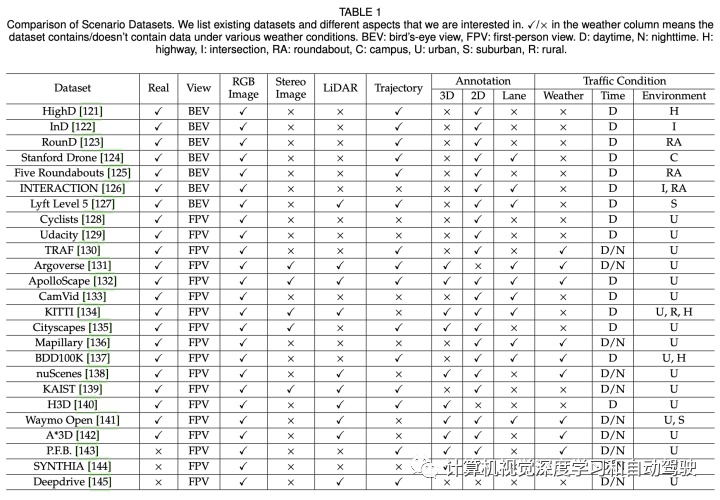
如表是场景数据集的比较:
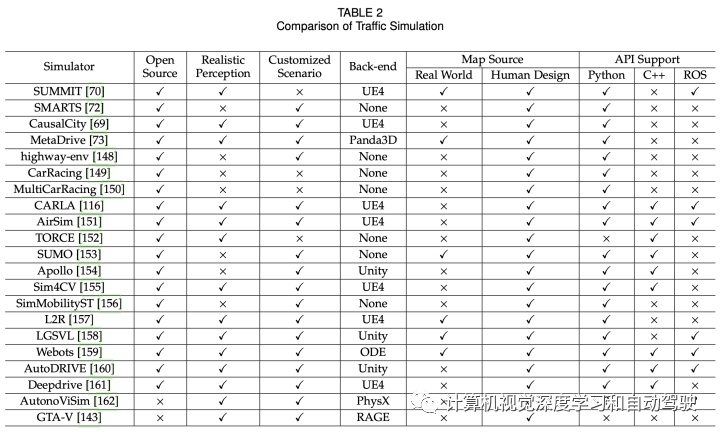
下表是交通仿真平台的比较:
另外,场景设计平台有如下几种:
-
CARLA Scenario Runner:为CARLA提供交通场景定义和执行引擎。场景可以通过Python界面定义,该界面允许用户轻松描述复杂且同步的机动,涉及车辆、行人和其他交通参与者等多个实体。它还支持OpenSCENARIO标准文件格式用于场景描述,使其能够简单高效地合并开源社区的各种现有交通场景。
-
DI Drive Casezoo:由一组场景组成,用于在模拟器中训练和评估驾驶策略。与CARLA Scenario Runner类似,DI Drive Casezoo有一个路线场景和多个单一场景,可沿路线触发。路线场景在XML文件定义,并带有相应的场景。沿路线的触发位置在JSON文件中定义。Python文件中定义了一个场景,描述了交通参与者的行为。在官方代码库中,有18种路线场景和8种类型的单一场景,可根据路线定义触发。
-
SUMO NETEDIT:是一个图形场景编辑器,可用于从头创建交通网络,并修改现有网络的所有方面,包括基本网络元素(路口、边缘和车道)、高级网络元素(如交通灯)和附加基础设施(如公交车站)。该工具是专门为SUMO设计的,SUMO主要生成大规模交通状况,而不进行高保真渲染。
-
SMARTS Scenario Studio:是SMARTS平台中的一个场景设计工具,支持灵活且富有表现力的场景规范。场景定义用Domain Specific Language(DSL)编写,该语言描述交通环境,如交通工具、路线和智体任务。Scenario Studio还支持SUMO NETEDIT的配置文件。通过NETEDIT编辑的地图可以很容易地包含在Scenario Studio中并在其中复用,丰富了SMARTS平台中的训练和测试环境。
-
CommonRoad:是一个模拟器和一个开源工具箱,用于训练和评估基于强化学习(RL)的自动车辆运动规划器。场景配置用XML文件编写。用户可以使用CommonRoad提供的Python API来阅读、修改、可视化和存储自己的交通场景。此外,CommonRoad还支持更多场景规范,如Lanelet2和OpenSCENARIO。
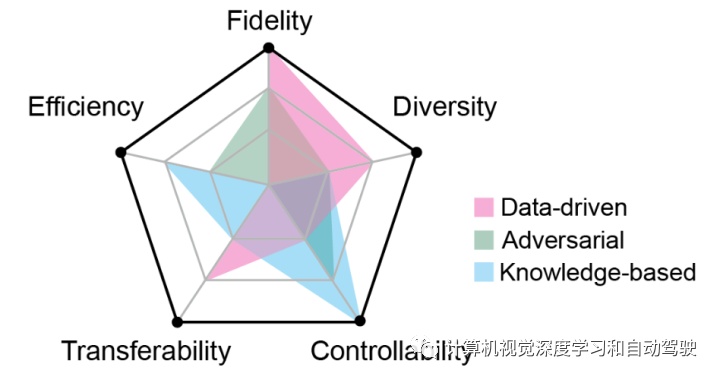
这个领域存在5个挑战,如图根据三种生成方法比较这些挑战项的表现:
-
准确性。最终目标是开发能够在现实世界中运行的安全设备。因此,让AV通过困难但不现实的场景是没有用的。需要确保生成的场景有机会在实际交通情况下发生。
-
效率。安全-紧要场景在现实世界中极为少见。生成需要考虑效率和增加感兴趣场景的密度。
-
多样性。安全-紧要场景多种多样。生成算法应该能够发现并生成尽可能多的不同安全-紧要场景。
-
可迁移性。由于AV与其周围物体之间的相互作用,场景是动态的。我们为不同AV生成的场景应该是可变的,而不是针对一个特定AV。
-
可控性。在大多数情况下,希望复制或重复特定的场景,而不是随机场景。生成模型应该能够按照指令或条件生成相应的场景。
- 下一篇:纯电车型减速器和混动车型变速器
- 上一篇:自动驾驶系统中视觉感知模块的安全测试



 广告
广告 



最新资讯
-
联合国法规R73对货车侧面防护装置的工程化
2026-03-09 12:14
-
联合国法规R72对HS1卤素灯摩托车前照灯的工
2026-03-09 12:13
-
《汽车环境风洞 雪模拟试验及评价方法》国
2026-03-09 10:56
-
《汽车空气动力学与声学风洞 流场校准规范
2026-03-09 10:56
-
电池耐久试验方法的工程逻辑:SRC循环与多
2026-03-09 10:55
