




 广告
广告





















































ICCV‘21论文:模仿一个强化学习教练的端到端城市驾驶
2022-01-18 23:28:58· 来源:计算机视觉深度学习和自动驾驶 作者:黄浴

arXiv于2021.8.26上传的ICCV‘21论文 “End-to-End Urban Driving by Imitating a Reinforcement Learning Coach“,作者主要来自瑞士苏黎世ETH的Luc Van Gool组
arXiv于2021.8.26上传的ICCV‘21论文 “End-to-End Urban Driving by Imitating a Reinforcement Learning Coach“,作者主要来自瑞士苏黎世ETH的Luc Van Gool组。

自动驾驶的端到端方法,通常依赖于专家演示。对带策略(on-policy)密集监督的端到端算法来说,人尽管是优秀的司机,但并不是很好的教练。相反,靠特别提供信息的自动化专家可以有效地生成大规模带策略(on-policy)和不带策略(off-policy)演示。
然而,现有的城市驾驶自动化专家使用大量手工制定的规则,即使在有真值信息的驾驶模拟器上也表现不佳。为了解决这些问题,作者训练了一个强化学习(RL)专家,将鸟瞰图(BEV)图像映射到连续的低层动作。
该专家在为开源仿真器 CARLA 设置新的性能上限的同时,还是一位更佳的教练,为模仿学习(IL)智体提供学习的信息化监督信号。在这个强化学习(RL)教练的监督下,一个单目摄像头端到端的基准智体实现了专家级性能。
该端到端智体实现了 78% 的成功率,在更具挑战性的 CARLA LeaderBoard,获得了最佳的性能。另外,代码上线:https://github.com/zhejz/carla-roach。
虽然模仿学习 (IL) 方法直接模仿专家的行为,但强化学习 (RL) 方法通常用专家演示的监督学习对模型的一部分进行预训练,这样提高样本效率。一般来说,专家演示可以分为两类:
-
(i)不带策略(off-policy),专家直接控制系统,状态/观测分布随专家。自动驾驶的无策略数据包括一些公共驾驶数据集,如nuScenes,Lyft level 5,Bdd100k;
-
(ii) 带策略(on-policy),系统由所需的智体控制,专家对数据进行“标记”;在这种情况下,状态/观测分布随智体,但可以接触专家演示数据;有策略数据是缓解协变量迁移(covariate shift)现象的基础,因为它允许智体从自己的错误中学习,而不带策略数据的专家没有出现这种错误。
然而,从人那里收集足够的带策略演示并非易事。虽然可以在不带策略数据收集过程中直接记录人类专家采取的轨迹和行动,但在给定传感器测量值的情况下标记这些专家给出的目标,对人来说还是一项具有挑战性的任务。在实践中,只有稀疏事件,比如人为干预等被记录,由于其包含的信息有限,难以训练,更加适合强化学习(RL)而不是模仿学习(IL)。
该工作专注于自动化专家,与人类专家相比,无论是带策略还是不带策略,自动化专家可以生成大规模密集标注数据集。为了达到专家级的性能,自动化专家可能依赖详尽的计算、昂贵的传感器甚至真值信息,因此直接部署是不可取的。
尽管一些模仿学习(IL) 方法不需要带策略(on-policy)标注,例如 生成对抗模仿学习(Generative adversarial imitation learning,GAIL)和逆强化学习(IRL),但与环境的带策略(on-policy)交互,效率不高。相反,自动化专家可以减少昂贵的带策略(on-policy)交互,这使模仿学习(IL)能够成功地将自动化专家应用于自动驾驶的不同方面。
自动驾驶仿真器CARLA 的“专家”,通常称为 Autopilot(或漫游智体)。Autopilot 可以访问真实模拟状态,但由于用了手工制定的规则,其驾驶技能无法与人类专家相提并论。模仿学习(IL)可以看成是知识迁移,但是只是从专家行动中学习是不够有效的。
Autopilot 由两个轨迹跟踪的 PID 控制器和紧急制动的危害(hazard)检测器组成。危害包括
-
前方检测到行人/车辆;
-
前方检测到红灯/停车信号;
-
自车负速度,用于处理斜坡。
如果自车前方的触发区域出现任何危害,Autopilot 会紧急刹车:油门=0,转向 = 0,刹车 = 1;如果没有检测到危险,自车通过两个 PID 控制器沿着所需路径行驶,一个用于速度控制,另一个用于转向控制;PID 控制器将自车的位置、旋转和速度作为输入,指定的路线是密集(1 米间隔)的航路点;速度 的PID 产生油门,转向的 PID 产生转向;手动调整PID 控制器和危害检测器的参数, 使得Autopilot 作为一个强大的基准方法(目标速度为 6 m/s)。
从头开始训练10M步之后,Roach超越基于规则的Autopilot,为CARLA设定了新的性能上限。从Roach专家进行学习时,可以训练模仿学习(IL)智体,并研究更有效的训练技术。鉴于神经网络的策略采用,Roach可以当同样基于神经网络的模仿学习(IL)智体更好的教练。
Roach为模仿学习(IL)智体提供了许多可供学习的信息化目标,这远远超出了其他专家提供的确定性动作。文章中展示了动作分布、价值估计和潜在特征为监督的有效性。
如图就是作者提出的Roach (RL coach):这是一个在CARLA仿真器上Roach 标注的带策略(on-policy)监督进行学习的方案。Roach 的输出在 CARLA 上可驱动车辆去记录来自 Roach 的不带策略数据。除了利用 3D 检测算法和其他传感器来合成 BEV之外,Roach 还可以解决现实世界中带策略监督稀缺的问题。
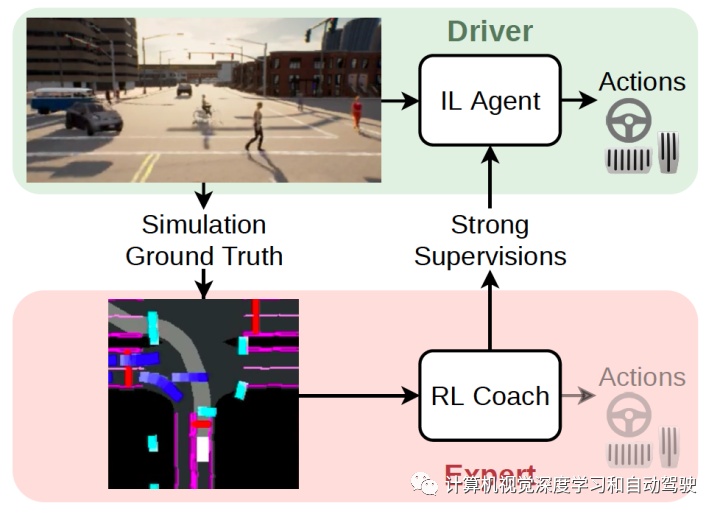
作者认为这个方法是可行的,因为一方面BEV作为一种强大的抽象表示减少了仿真到真实的差距,另一方面策略标注不必实时或甚至在线(onboard)产生。给定完整的序列,3D 检测变得更容易。
Roach具有三个特点:
-
首先,与之前的强化学习( RL )智体相比,Roach 不依赖于其他专家的数据;
-
其次,与CARLA仿真器基于规则的Autopilot 不同,Roach 是端到端可训练的,因此可通过少量的工程工作推广到新的场景;
-
第三,采样效率高,基于输入/输出表证和探索(exploration)损失,在单个GPU机器从头开始训练 Roach不到一周的时间,在 CARLA的六个LeaderBoard地图获得顶级专家性能。
Roach由一个策略网络和一个价值网络组成。策略网络将 BEV 图像和测量向量 映射到一个动作分布。最后,价值网络用和策略网络相同的输入估计一个标量值输出。
如图是Roach的每个BEV表证通道:(有些相似谷歌waymo之前的工作)

可行驶区域和预期路线分别在图( a )和 (b )中呈现。在图 (c )中,实线为白色,虚线为灰色。图( d )是 K 个灰度图像的时间序列,其中自行车和车辆被渲染为白色边框。图( e )与图 (d )相同,但针对行人。类似地,交通灯处的停止线和停止标志的触发区域在图(f )中呈现。红灯和停车标志按最亮的级别着色,黄灯按中间级别着色,绿灯按较暗级别着色。如果停车标志处于活动状态,则呈现停车标志,即自车进入其附近并在自车完全停止后消失。
通过BEV 表证记住自车是否停止,用无循环结构的网络架构,减少 Roach 的模型大小。前面的图示给出了所有通道的彩色组合。给Roach 提供一个测量向量,其中包含 BEV未表证的自车状态,包括转向、油门、制动、闸门、横向和横向速度。
为了避免做参数调整和系统识别,Roach 直接预测动作分布。其动作空间主要是转向和加速,加速度正值对应油门,负值对应刹车。这里用Beta分布描述动作。
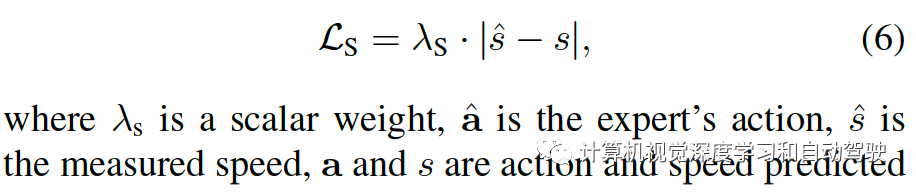
与无模型强化学习(model-free RL)常常采用的高斯分布相比,Beta 分布的支持是有界的,避免了强制输入约束的裁剪(clipping)或压扁(squashing)操作。
这个会带来表现更好的学习(better behaved learning)问题,因为不需要 tanh 层并且熵和 KL 散度可以明确计算。此外,Beta 分布的模态也适用于经常进行极端操作的驾驶动作,例如紧急制动或急转弯。
训练采用带裁剪的proximal policy optimization (PPO)方法训练策略网络和价值网络(见论文“Proximal policy optimization algorithms“. arXiv:1707.06347, 2017)。
价值网络训练回归期望回报,而策略网络更新通过以下公式:
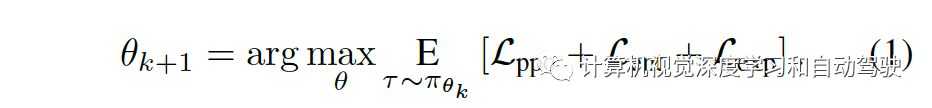
第一个目标 Lppo 是裁剪策略的梯度损失,采用广义优势估计(generalized advantage estimation)估计其优势(见论文“High-dimensional continuous control using generalized advantage estimation“. ICLR, 2016)。第二个目标 Lent 是通常用于鼓励探索(exploration)的最大熵损失直观地讲,Lent 将动作分布推向一个均匀先验形式,因为最大化熵等效于最小化KL散度的均匀分布目标,如果二者共享同一支持的话。
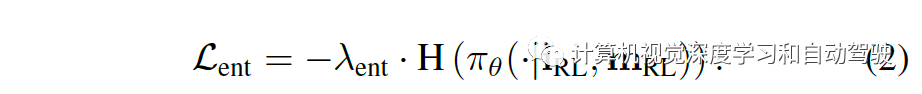
这使得作者提出一种广义形式,它鼓励在合理的、符合基本交通规则的方向上进行探索,称之为探索损失,定义为
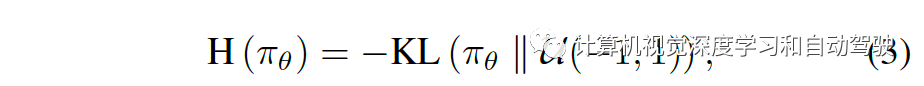
其中终止条件集 (terminal condition set)Z 包括碰撞、运行交通红绿灯/标志、路线偏离和阻塞等插曲(episode)结束事件。
最大熵损失Lent在所有时间步都对动作施加统一的先验分布,而不管哪个事件 z 被触发;而探索损失Lexp在一个情节的最后 Nz (实践中取100)步骤中把动作转移到一个预定的探索先验分布 pz,该探索先验编码了一个“建议(advice)”,防止触发事件 z 再次发生。
如果 z 与碰撞或交通红绿灯/标志有关,加速度先验 pz = B(1,2.5) 以鼓励 Roach 在不影响转向的情况下减速。相反,如果汽车被阻挡,加速度先验 pz=B(2.5,1)。对路线偏离,转向的统一先验pz= B(1,1)。尽管这种情况下等效于最大化熵,但探索损失在路线偏离前的最后 10 秒进一步鼓励探索转向角。
为了让模仿学习( IL )智体从 Roach 生成的信息化监督中受益,作者为每个监督制定一个损失,这样Roach 的训练方案可用于提高现有模仿学习(IL)智体的性能。
本文以DA-RB为例( 论文“Exploring data aggregation in policy learning for vision-based urban autonomous driving“,CVPR, 2020)它是CILRS(论文“Exploring the limitations of behavior cloning for autonomous driving“. ICCV, 2019)和DAGGER(论文“A reduction of imitation learning and structured prediction to no-regret online learning“. AISTATS, 2011)的结合。
整个网络架构如图:包括(a)Roach和(b)CILRS
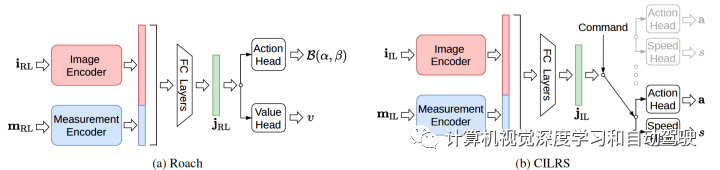
在(a)Roach架构中,用六个卷积层对 BEV 进行编码,两个全连接 (FC) 层对测量向量进行编码;两个编码器的输出连接在一起,由另外两个 FC 层处理产生潜在特征 jRL,然后输入到价值头和策略头中,每个头都有两个 FC 隐藏层;轨迹以 10 FPS 频率从六个 CARLA 服务器收集,每个服务器对应六个LeaderBoard地图的一个;在每一插曲的开始,随机选择一对起始位置和目标(target)位置,并使用 A* 搜索算法计算所需的路线;一旦达到目标,就选择一个新的随机目标;除非满足 Z 的终止条件之一,否则该插曲不会结束。这里额外惩罚大的转向变化以防止振荡操作。为了避免高速违规,添加与自车速度成正比的额外惩罚。
在(b)CILRS架构中,包括一个相机图像编码的感知模块和一个测量向量编码的测量模块;两个模块的输出由 FC 层连接和处理,生成瓶颈(bottleneck)潜在特征;导航指令作为离散的高级命令给出,并且为每种命令构造一个分支;所有分支共享相同的架构,而每个分支包含一个预测连续动作的动作头和一个预测自车当前速度的速度头;潜在特征由命令选择的分支处理。
CILRS 的模仿目标包括 L1 动作损失
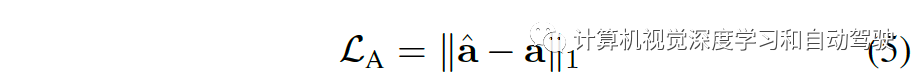
和速度预测的正则化
专家动作可能来自CARLA的Autopilot,它直接输出确定性动作,或者来自 Roach,其将分布模态作为确定性输出。除了确定性动作,Roach 还预测动作分布、价值和潜在特征。
动作分布损失:两个分别被Roach和CILRS智体预测的动作分布之间KL-散度
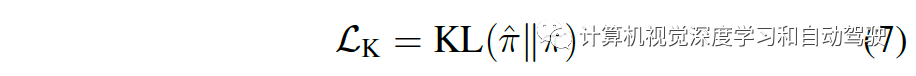
特征损失:Roach的潜在特征
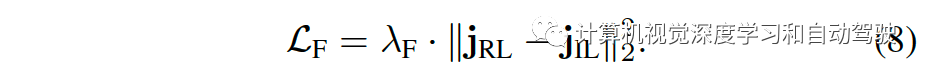
价值损失:用价值头和回归价值作为副任务来增强CILRS,其中价值损失是 Roach 估计和 CILRS 预测之间的均方误差
采用CARLA的NoCrash和LeaderBoard做实验评估算法。NoCrash 基准测试考虑从Town1(一个仅由单车道路和丁字路口组成的欧洲城镇)到Town2(具有不同纹理的Town1 较小版本)的泛化。相比之下,LeaderBoard在六张地图中考虑了一个更困难的泛化任务,涵盖不同的交通情况,包括高速公路、美式路口、环形交叉路口、停车标志、车道变换和合并。
按照NoCrash 基准,测试了四种训练天气类型到两种新天气类型的泛化。为了节省计算资源,四种训练天气类型只评估了两种。NoCrash 基准具有三个级别的交通密度(空旷、常规和密集),定义了每张地图的行人和车辆数量。该文专注于 NoCrash-密集,并在常规和密集交通之间引入一个新的级别 NoCrash-繁忙(busy),以避免在密集交通环境经常出现的拥堵。
对CARLA LeaderBoard,每张地图的交通密度都经过调整,与繁忙的交通设置有可比性。
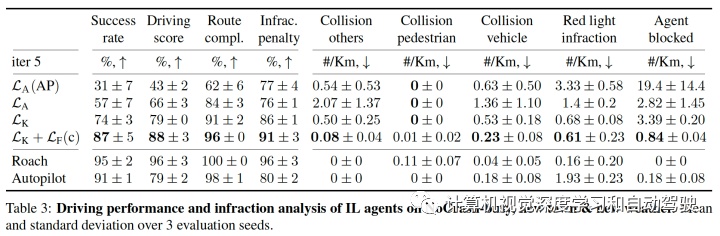
一些实验结果如下:
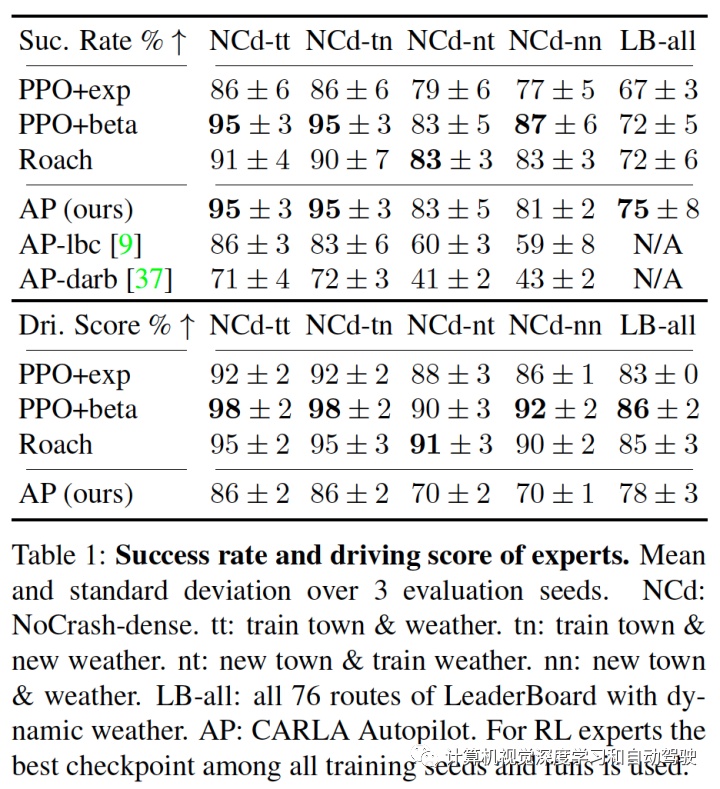
注:LBC来自论文“Learning by cheating“. CoRL, 2020. DARB来自论文“Exploring data aggregation in policy learning for vision-based urban autonomous driving“. CVPR, 2020。
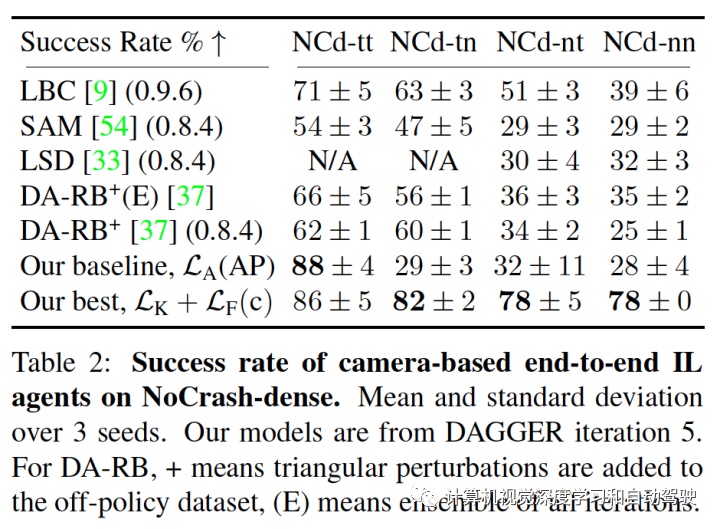
注:SAM来自论文“Sam: Squeeze-and-mimic networks for conditional visual driving policy learning”,CoRL'20。LSD来自论文“Learning situational driving”,CVPR‘20。
未来的工作包括改进仿真基准测试和实际部署的性能。为使LeaderBoard饱和,模型容量应增加。为用 Roach 标记真实世界的带策略驾驶数据,除了照片真实感之外,还必须解决几个模拟到真实的差距,BEV 部分缓解了这一差距。对于城市驾驶模拟器,道路使用者(包括行人和车辆)的真实行为至关重要。



 广告
广告 



最新资讯
-
联合国法规R73对货车侧面防护装置的工程化
2026-03-09 12:14
-
联合国法规R72对HS1卤素灯摩托车前照灯的工
2026-03-09 12:13
-
《汽车环境风洞 雪模拟试验及评价方法》国
2026-03-09 10:56
-
《汽车空气动力学与声学风洞 流场校准规范
2026-03-09 10:56
-
电池耐久试验方法的工程逻辑:SRC循环与多
2026-03-09 10:55
