




 广告
广告





















































疲劳分析中需要知道的一点统计学
2021-04-14 13:09:49· 来源:上海山外山机电工程科技有限公司

对于绝大多数工程师来说,统计学是一门不太容易掌握的学科。在教科书上,统计学一般都是纯数学理论,没有将统计公式与实际工程案例结合起来,所以不太容易弄懂。
对于绝大多数工程师来说,统计学是一门不太容易掌握的学科。在教科书上,统计学一般都是纯数学理论,没有将统计公式与实际工程案例结合起来,所以不太容易弄懂。在结构疲劳分析中,其实并没有太多的理论需要我们掌握,重要的是需要将一些观念和统计概念结合起来。
我们来看一组数据:
表1 – 数据列表
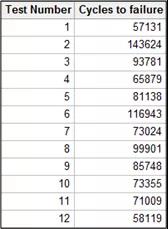
这些数据有什么含义呢?如果将这些点连接起来,它们看起来像一段随机数据(图1- a);如果我们看这段数据从头到尾的趋势变化,趋势变化并不明显(图1 - b);如果将这段数据的动态均值连起来,均值变化大约在50附近上下波动(图1- c)。初步看上去,数据没有多大的规律性。

图1 – (a)原始数据,(b)趋势分析,(c)动态均值分析
换一种方式,如果我们统计一下每个数据点在整个样本中出现的频次(如图2),横坐标为数据大小区间,纵坐标为测试数据在各区间出现的频次,这些频次接近一种近似的规律性。越接近均值的点的个数越多,越远离均值的点的个数越少。
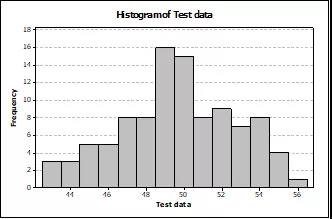
图2 – 数据出现频次图
这些点出现的频次所呈现出的特性就是一种概率分布。将图2中的柱状图进行平滑,找出其频次数的平滑拟合线,如图3。继续,将纵坐标的频次数改为累积频次数,例如,假定柱状图中以数值44为起点,数值44出现了3次,数值45出现了5次,累积频次图的纵坐标则变为小于数值44的数出现了3次,小于数值45的数出现了(3+5)次,以此类推,则成为累积频次图(CumulativeDistribution Function, CDF,其纵坐标变成各级次数除以总次数的比值)。如果将累积频次图的纵坐标改为对数坐标,所有的频次数则变成了一个直线分布。至此,我们找到了这个数据样本的一般性规律:数据服从正态分布。
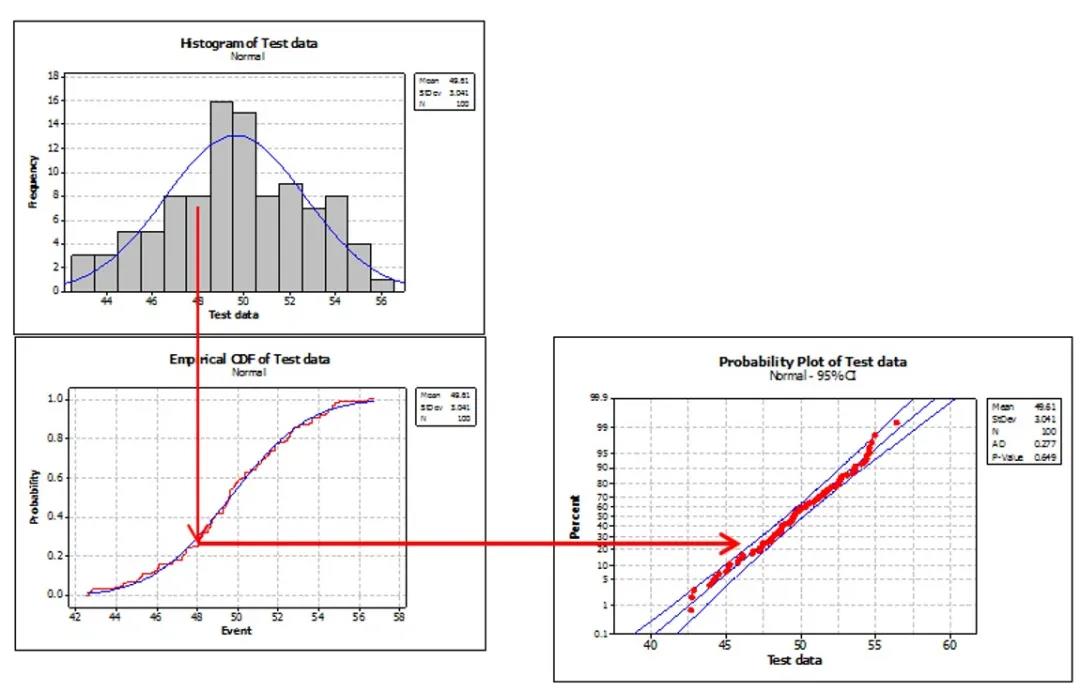
图3– 累积频次图(CDF)
对数纵坐标下的累积频次图,绝大多数的点都分布在中间的一条直线上,中间直线的左右两边各有一条线,这两条线几乎将所有的点都囊括在其中。这两条线所形成的区域,称为置信区间。本案例中,这个置信度为95%,即100个样本中有95个处于这个置信区间中。
正态分布是诸多概率分布中的一种。其他常用的分布还有对数正态分布、二项式分布、威布尔分布、极值分布等。对于工程应用来说,没有必要过多的考虑这些分布的数学公式,有很多统计软件,如MINITAB[1],可以帮助我们解决诸如此类的概率统计问题。我们可以通过软件选择合适的分布表达数据,找到最适合这些数据的分布即可。
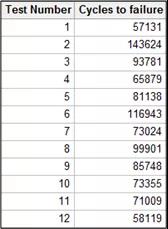
举个例子。假如我们做了12个零部件试验,得到了在某一固定幅值下的12组失效次数,如表2。
表2 – 试验失效次数
我们用不同的概率分布来表达这组数据,如图4。通过肉眼,直观判断对数正态分布最适合这组数据。实际上,通过数学指标AD值(Anderson-Darling)也能得到同样的判断。AD值越小,对应的P值(P-Value)越大,概率分布与数据的适应性越好。如果P值过小,通常为小于0.1,则该组数据不服从于所选择的分布。
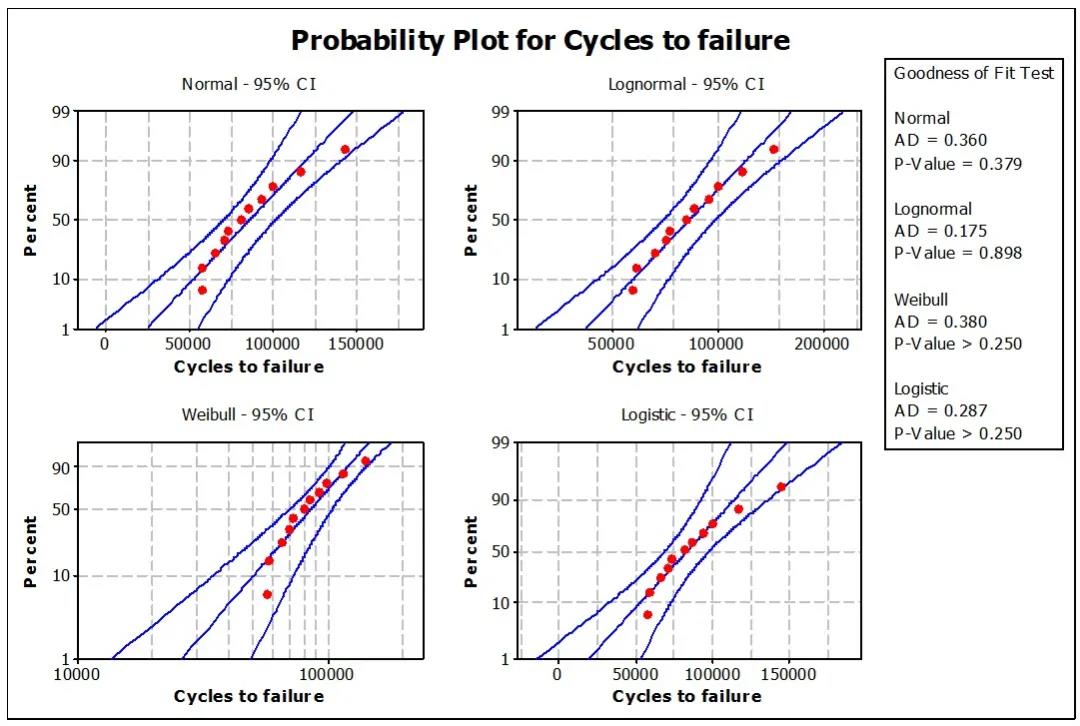
图4 – 通过不同的概率分布表达数据
一旦选定了合适的分布,我们即可直接读取这组数据的统计值。如表2数据的均值(mean)或中值(median)[2]约为83,000,或者说我们有95%的信心这组数据的中值处于70,000和98,000之间(图5)。在现有测试样本数的条件下,这是我们对这组数据的统计特征能做到的做好的估计。
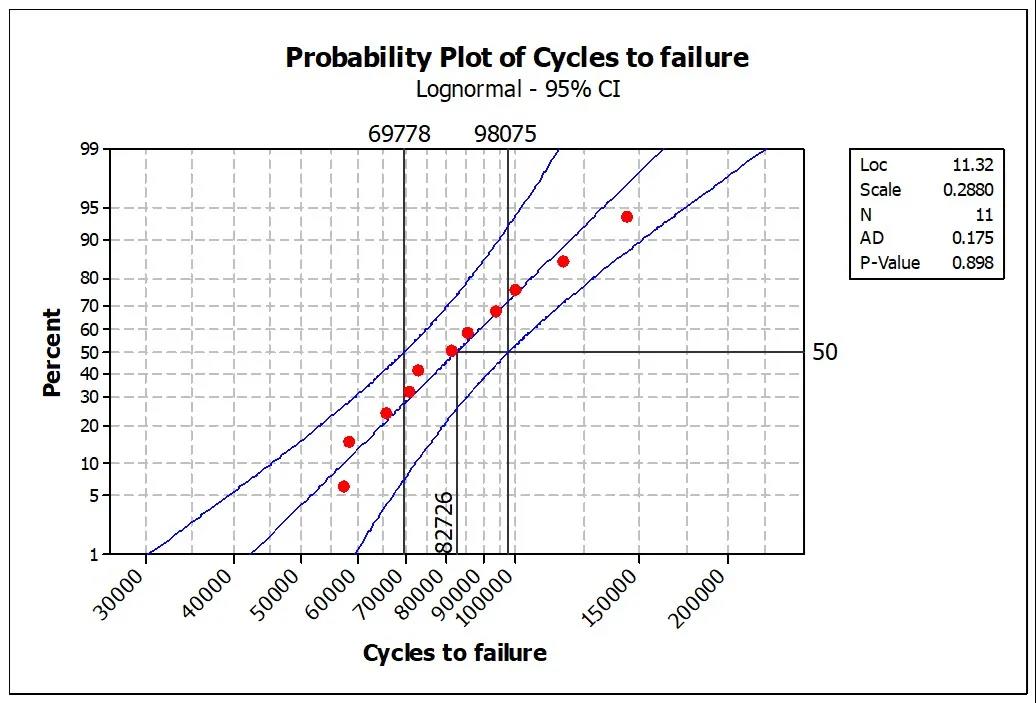
图5 – 对数正态分布

图6 – 比较6个样本数和12个样本数的中值
如果将服从同一概率分布的6个样本值和12个样本值放在一起比较(如图6),会发现两组数据的中值接近,但12个样本值的概率分布置信区间更小,这意味着样本数越多,其概率分布越趋于集中,由此预测大样本概率的精度会越高。
现在我们可以看到概率的好处了。它帮助我们解释测试结果并告诉我们结果的离散度会有多大。在后续的文章中,我们会运用概率来分析道路测试数据和试验室测试结果。
需要强调的是,任何工程测试数据都是一个估计。估计值的精度取决于测试方法的定义,试验样本的多少,以及表达试验结果的变量的选择。而置信区间表达了试验结果可能的离散度,在总结试验结论时需要考虑进去。
我们通过两组数据来举例说明。假定我们从测试1中获得了10个测试结果,从同样的测试2中获得了100个测试结果,测试结果服从正态分布如图7所示。
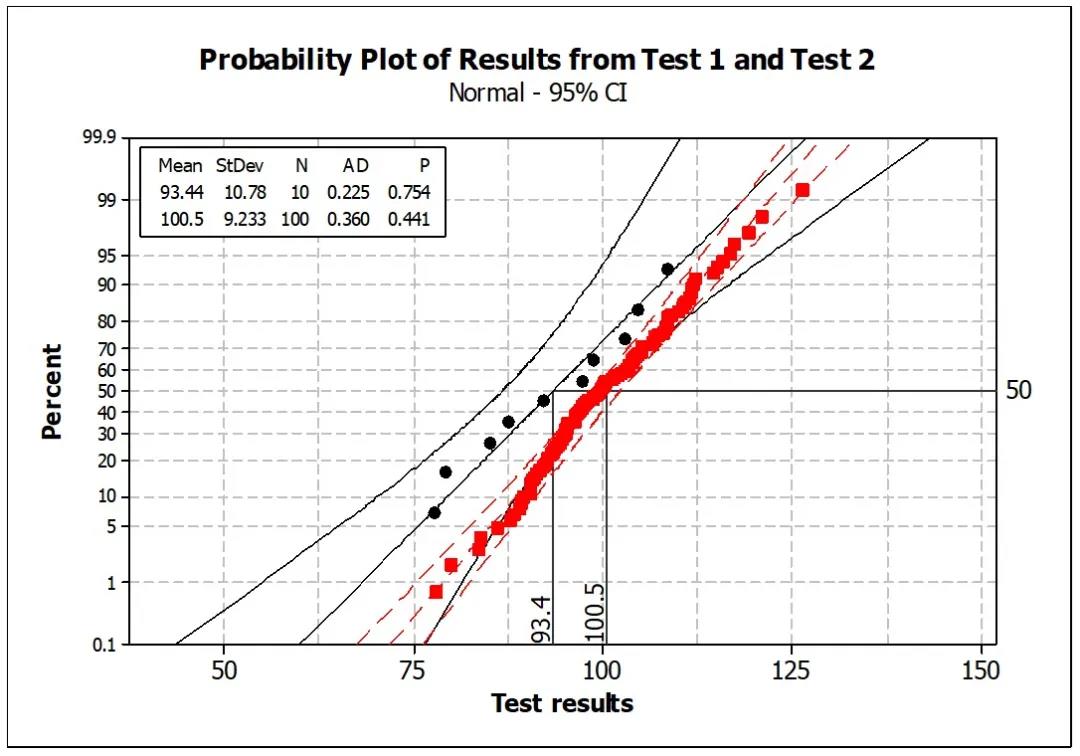
图7 – 测试结果
从图中可以看到,测试1的均值为93.4,测试2的均值为100.5,两者约7%的差异。相比测试1,测试2的结果置信区间精度高出很多。测试1的置信区间为±7% ,而测试2的置信区间< ±2%。
再举一个利用统计概念帮助我们解释试验结果的例子。一个整车生产厂将某个零部件的售后失效里程数进行了统计。数据来源于两个不同的区域。将该部件在两个区域的失效里程用概率分布表达,如图8所示。两组数据均服从正态分布,其均值大致相同,但分布的斜率完全不同。从图中可以看出,对区域A,绝大多数零部件会在9万公里左右失效,而区域B则会到16万公里左右,此外,区域A的载荷输入或者说道路条件比区域B稳定,因此其零件失效里程数相对稳定。换句话说,区域B驾驶条件更加恶劣,零件失效里程数的离散度更大。
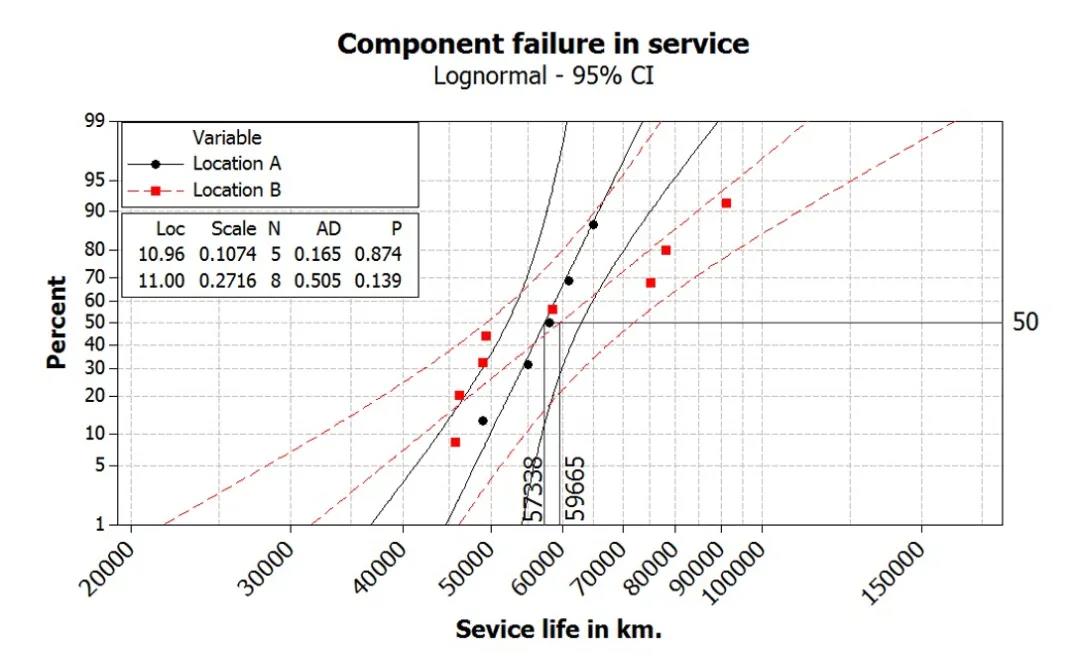
图8 – 售后失效数据
总结来说,可供分析的数据样本量越多,对数据统计量的预测精度越高。在工程实践中,由于时间和成本的关系,往往得不到足够的试验样本数,这是我们需要面对的挑战,需要取舍和综合判断。
[1] http://www.minitab.com/en-us/
[2]中值又称中位数,当样本项数n为奇数时,处于中间位置的样本值即为中位数;当n为偶数时,中位数则为处于中间位置的2个样本值的平均数。只有在正态分布下,均值和中值相等。
我们来看一组数据:
表1 – 数据列表
这些数据有什么含义呢?如果将这些点连接起来,它们看起来像一段随机数据(图1- a);如果我们看这段数据从头到尾的趋势变化,趋势变化并不明显(图1 - b);如果将这段数据的动态均值连起来,均值变化大约在50附近上下波动(图1- c)。初步看上去,数据没有多大的规律性。
图1 – (a)原始数据,(b)趋势分析,(c)动态均值分析
换一种方式,如果我们统计一下每个数据点在整个样本中出现的频次(如图2),横坐标为数据大小区间,纵坐标为测试数据在各区间出现的频次,这些频次接近一种近似的规律性。越接近均值的点的个数越多,越远离均值的点的个数越少。
图2 – 数据出现频次图
这些点出现的频次所呈现出的特性就是一种概率分布。将图2中的柱状图进行平滑,找出其频次数的平滑拟合线,如图3。继续,将纵坐标的频次数改为累积频次数,例如,假定柱状图中以数值44为起点,数值44出现了3次,数值45出现了5次,累积频次图的纵坐标则变为小于数值44的数出现了3次,小于数值45的数出现了(3+5)次,以此类推,则成为累积频次图(CumulativeDistribution Function, CDF,其纵坐标变成各级次数除以总次数的比值)。如果将累积频次图的纵坐标改为对数坐标,所有的频次数则变成了一个直线分布。至此,我们找到了这个数据样本的一般性规律:数据服从正态分布。
图3– 累积频次图(CDF)
对数纵坐标下的累积频次图,绝大多数的点都分布在中间的一条直线上,中间直线的左右两边各有一条线,这两条线几乎将所有的点都囊括在其中。这两条线所形成的区域,称为置信区间。本案例中,这个置信度为95%,即100个样本中有95个处于这个置信区间中。
正态分布是诸多概率分布中的一种。其他常用的分布还有对数正态分布、二项式分布、威布尔分布、极值分布等。对于工程应用来说,没有必要过多的考虑这些分布的数学公式,有很多统计软件,如MINITAB[1],可以帮助我们解决诸如此类的概率统计问题。我们可以通过软件选择合适的分布表达数据,找到最适合这些数据的分布即可。
举个例子。假如我们做了12个零部件试验,得到了在某一固定幅值下的12组失效次数,如表2。
表2 – 试验失效次数
我们用不同的概率分布来表达这组数据,如图4。通过肉眼,直观判断对数正态分布最适合这组数据。实际上,通过数学指标AD值(Anderson-Darling)也能得到同样的判断。AD值越小,对应的P值(P-Value)越大,概率分布与数据的适应性越好。如果P值过小,通常为小于0.1,则该组数据不服从于所选择的分布。
图4 – 通过不同的概率分布表达数据
一旦选定了合适的分布,我们即可直接读取这组数据的统计值。如表2数据的均值(mean)或中值(median)[2]约为83,000,或者说我们有95%的信心这组数据的中值处于70,000和98,000之间(图5)。在现有测试样本数的条件下,这是我们对这组数据的统计特征能做到的做好的估计。
图5 – 对数正态分布
图6 – 比较6个样本数和12个样本数的中值
如果将服从同一概率分布的6个样本值和12个样本值放在一起比较(如图6),会发现两组数据的中值接近,但12个样本值的概率分布置信区间更小,这意味着样本数越多,其概率分布越趋于集中,由此预测大样本概率的精度会越高。
现在我们可以看到概率的好处了。它帮助我们解释测试结果并告诉我们结果的离散度会有多大。在后续的文章中,我们会运用概率来分析道路测试数据和试验室测试结果。
需要强调的是,任何工程测试数据都是一个估计。估计值的精度取决于测试方法的定义,试验样本的多少,以及表达试验结果的变量的选择。而置信区间表达了试验结果可能的离散度,在总结试验结论时需要考虑进去。
我们通过两组数据来举例说明。假定我们从测试1中获得了10个测试结果,从同样的测试2中获得了100个测试结果,测试结果服从正态分布如图7所示。
图7 – 测试结果
从图中可以看到,测试1的均值为93.4,测试2的均值为100.5,两者约7%的差异。相比测试1,测试2的结果置信区间精度高出很多。测试1的置信区间为±7% ,而测试2的置信区间< ±2%。
再举一个利用统计概念帮助我们解释试验结果的例子。一个整车生产厂将某个零部件的售后失效里程数进行了统计。数据来源于两个不同的区域。将该部件在两个区域的失效里程用概率分布表达,如图8所示。两组数据均服从正态分布,其均值大致相同,但分布的斜率完全不同。从图中可以看出,对区域A,绝大多数零部件会在9万公里左右失效,而区域B则会到16万公里左右,此外,区域A的载荷输入或者说道路条件比区域B稳定,因此其零件失效里程数相对稳定。换句话说,区域B驾驶条件更加恶劣,零件失效里程数的离散度更大。
图8 – 售后失效数据
总结来说,可供分析的数据样本量越多,对数据统计量的预测精度越高。在工程实践中,由于时间和成本的关系,往往得不到足够的试验样本数,这是我们需要面对的挑战,需要取舍和综合判断。
[1] http://www.minitab.com/en-us/
[2]中值又称中位数,当样本项数n为奇数时,处于中间位置的样本值即为中位数;当n为偶数时,中位数则为处于中间位置的2个样本值的平均数。只有在正态分布下,均值和中值相等。



 广告
广告 



最新资讯
-
用于赛车运动车辆动力学测量的光学传感器
2026-03-18 21:31
-
联合国法规R86对农林拖拉机灯光安装的工程
2026-03-18 12:20
-
联合国法规R78对L类车辆制动系统的工程化约
2026-03-18 12:16
-
联合国法规R77对机动车驻车灯静态可见性的
2026-03-18 12:16
-
TCT亚洲展启幕!思看科技人气爆棚,这些产
2026-03-17 19:17
