




 广告
广告





















































一种针对不确定多模态障碍物的鲁棒场景MPC方法
2020-10-09 14:13:27· 来源:同济智能汽车研究所

编者按:自动驾驶车辆的运行与控制架构中,决策规划层与运动控制层的联系十分紧密:规划层根据来自于传感器或网联通讯的车辆与道路信息,结合车辆自身的运动状态
编者按:自动驾驶车辆的运行与控制架构中,决策规划层与运动控制层的联系十分紧密:规划层根据来自于传感器或网联通讯的车辆与道路信息,结合车辆自身的运动状态与行驶目标,得到若干条参考行驶轨迹;而控制层的任务是根据规划层输出的参考轨迹,结合车辆自身状态,通过控制车辆的纵向速度、车轮转角等参数,实现对于目标轨迹的实时、准确跟踪。车辆的纵向控制主要实现速度的跟踪,侧向控制则实现路径的跟踪。近年来,模型预测控制MPC广泛应用于自动驾驶车辆的运动控制方面,MPC能够对输入与输出的约束条件进行系统性处理,非常适用处理多输入多输出控制系统。随着车载传感器技术与车联网技术的不断发展,车辆行驶过程中所产生与接受的数据在种类与规模上都得到了拓展。如何充分而合理的利用这些车辆与交通数据,将是下一阶段智能车辆规划与控制的研究重点。
本文译自:
A Robust Scenario MPC Approach for Uncertain Multi-Modal Obstacles
文章来源:
IEEE Control Systems Letters, Vol.5, No.3, pp.947-952
作者:
Batkovic Ivo, Rosolia Ugo, Zanon Mario, Falcone Paolo
原文链接:
https://ieeexplore.ieee.org/document/9133136
摘要:相较于普通车辆,自动驾驶车辆对运动规划与控制算法的安全性提出了更高的要求。通过考虑其他车辆、行人等交通参与者的未来运动情况,可以得到目标车辆无碰撞行驶轨迹的规划结果。本文提出了一种基于包含鲁棒约束的模型预测控制方法,其中源自于道路交通参与者的约束不确定性是多模态的。该方法将管模型预测控制(tube-based MPC)与场景模型预测控制(scenario-based MPC)相结合,对期望代价函数值进行近似,并保证满足输入约束与鲁棒性。特别的,本文设计了一个基于扰动模式函数的反馈机制,从而允许控制器采取低保守性的操作。数值仿真的结果表明,本文所提出的方法相较于标准鲁棒MPC具有更好的性能。
关键词:自动驾驶汽车,不确定性系统,非线性系统预测控制
1 前言
自动驾驶技术在提高车辆驾驶的安全性方面展现出了巨大的潜力[1]。尽管自动驾驶技术已逐步在高速公路行驶、低速泊车等场景下得到了应用[2],但由于行人、非机动车以及其他机动车的存在,自动驾驶技术在城市道路场景下的实现仍面临着巨大的挑战。应对这些挑战的关键在于建立人类交通参与者的随即行为预测模型,并设计确保无碰撞安全性的行驶轨迹控制算法。
为此我们可以看到,理解并预测其他交通参与者的行为是十分重要的。目前已有研究提出了若干方法来对上述随机行为进行建模与预测,例如有研究利用高斯过程动力学模型与轨迹匹配方法,实现了对行人轨迹的预测[3]。也有研究考虑通过切换动态模型的方式来进行轨迹的短期预测[4],或利用混合模型来描述人类的不同步态[5]。近来,以马尔可夫过程模型[6]为代表的数据驱动方法相继被提出,而环境信息也以语义地图的形式被引入到预测模型之中[7]。有研究利用反馈控制器,将基于图的地图用于轨迹预测[8]。也有研究将道路的拓扑结构与基于集合的可达性分析相结合,实现轨迹预测[9]。为了充分利用周围个体与环境的预测结果,规划与控制算法需要在安全性方面具有足够的鲁棒性。有研究在车-车通信的假设下,通过基于优化的规划控制算法,实现了保证安全性前提下的避障控制[10]。也有研究设计了部分可观测马尔可夫决策过程,用于为其他交通参与者的行为进行预测,并将其用于控制器约束值的确定[11]。有研究基于间隙接受理论解决了行人之间的交互关系处理问题[12],也有研究明确的将行人轨迹预测结果作为动态障碍物信息引入规划与控制框架[13],具有一定的前瞻性。安全性始终是自动驾驶技术的首要目标,因此需要满足包括道路边界约束、执行器约束、未来避障约束等约束条件。
在本文中,我们设计了一个反馈机制,该机制适用于在约束条件受多模态不确定性影响时,能够在有约束的条件下执行低保守性的操作。这种多模态不确定性影响下的场景广泛存在于如图1所示的交通场景内,图中的行人可能穿过马路,也可能继续沿道路行走。特别的,我们基于扰动模式设计了有关函数,并据此提出了一个因果反馈策略,并通过结合管模型预测控制与场景模型预测控制的思想,证明了系统满足鲁棒约束。此外,我们进行相应的数值仿真,结果表明相较于标准管模型预测控制,我们所提出控制策略具有更好的性能。

图1 外部障碍物的两种运动预测模型
在第二节定义了本文的最优控制问题,在第三节描述了障碍物预测模型。在第四节提出了一种安全而非保守的控制策略,在第五节展示了两个数值仿真的结果与分析,并在第六节给出了本文的结论。
2 问题定义
我们考虑如下的离散时间系统:
其中,xk、uk依次为k时刻的状态量与控制量。我们的目标是设计一个控制器,在给定初始状态时,使得车辆位置偏离参考状态轨迹的距离最小,同时避免与外部障碍物发生碰撞。理想条件下,我们希望通过设计一个控制器,来解决无限时域最优控制问题(OCP),其中障碍物的未来位置假定先验已知,即:

其中约束(2b)(2c)表示初始状态与系统动力学,而约束(2d)包括状态量与控制量的限制等。约束(2e)表示车辆在未来所有位置与k≥0的时间内均能保证与障碍物ok不发生碰撞。我们假定阶段代价l(.,.)是连续正定的,且l(0,0)=0。
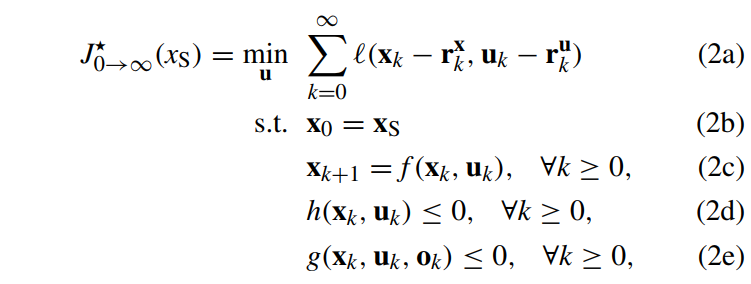
我们的目标则是,在初始集合S中,对所有的xS保证控制器的安全。正式定义如下:
定义1:如果一个控制器的控制量U={u0,…u∞}、状态量X={x0,x1,…x∞},在初始状态属于集合S、障碍物位置属于集合O时,满足约束(2d)(2e),则称控制器在集合S内是安全的。
事实上,在求解式(2)时具有相当的挑战性:问题一是未来状态的确切先验值是无法得到的;问题二是,从数值求解角度考虑,无限时域最优控制问题的求解具有挑战性,但对于线性系统、凸成本与约束等特殊情况,能够得到方程的准确解[18];问题三则是,我们需要优化的反馈策略依赖于障碍物状态ok与系统状态量xk。
我们首先通过定义时刻k的预测模型来解决第一个问题;接着对于问题二,通过设计一个模型预测控制策略来对无限时域最优控制问题进行近似;最后,为了解决问题三,我们通过只求解反馈策略的一个子集来对反馈策略的结构进行修改。
3 环境预测模型
由于障碍物未来状态量ok的全部先验信息未知,我们使用符号on|k来表示已知k时刻状态时的n时刻状态预测值。假定我们得到了障碍物的多模态预测模型,则在k时刻,第i个模态的障碍物状态量为:
其中,win|k表示状态量的不确定性。我们记βi为第i个模态的关联概率,此处的模态用来描述障碍物的不同运动意图,例如图1中的横穿马路与继续直走。
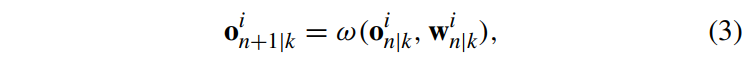
为了引入安全约束条件,我们需要预测on|k可以取得的可能值。做如下假设:
假设1:不确定性集合Oin|k是式(3)所给出的鲁棒可达集的外部逼近,即:

需要注意的是,对于每个模态i,集合Oin|k能够将相同模态的不同实现进行分组,以行人横穿马路为例,行人可能以快速、一侧稍慢等多种方式完成横穿马路的行为模态。同时,当两个模态的集合不相交时,我们能够推断出何种模态无法实现,从而允许我们在第四节中定义因果反馈策略。我们给出命题1如下:
命题1:给定一个障碍物状态序列[opk|k,…, opn|k],总能在n满足式(4)时,推断出p=i或是p=j。
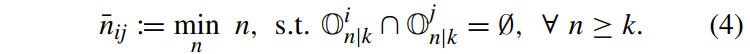
4 控制器设计
在本节中,我们首先说明了管模型预测控制是一种求解式(2)的可行策略。然而,当预测状态量on|k存在多模态时,鲁棒管式策略存在过于保守的问题。因此,在本节的第二部分,我们利用命题1提出了一个因果反馈策略,该策略将不同场景视为预测模型模态的函数。如第五节中所示,相较于标准的管模型预测控制策略,我们所提出的策略在同等的计算成本下,具有更好的平均性能。
4.1 管模型预测控制近似
首先,求解式(2)的一种直接但保守的方法是使用标准管模型预测控制方程对式(2)进行近似,即进行控制序列优化,而非进行策略优化。
其中N为预测时域,q、p分别为阶段代价与终端代价,约束(5f)为终端集。我们可以将式(5)写为k时刻的集合U*k={u*k|k,…, u*k+N-1|k },其中:
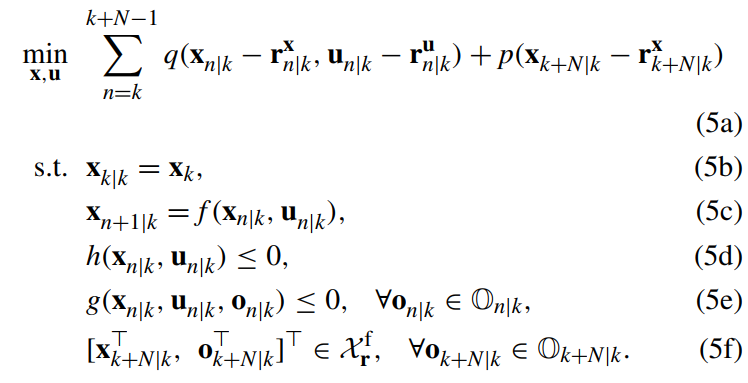

因此,式(5)在k+1时刻的状态可表示为:使得问题退化为滚动时域策略。式(5)是为了满足鲁棒约束的写出的,但对于存在多模态的障碍物状态量,这种策略是过于保守的。因此,为了降低优化策略的保守性,我们将在下一部分介绍我们所提出的控制策略。

4.2 场景预测策略
如前所述式(5)的求解方案对于障碍物未知的所有可能实现而言都是鲁棒的,我们采用命题1的结果来设计因果时变反馈策略,它是障碍物行为模态类型i的函数,设计反馈策略时遵循类似[17]中的原则。此外,该策略允许我们对预期代价进行近似,其中预期代价取决于障碍物的随机位置,从而考虑到闭环性能的改善。
在预测时刻n,如果可以根据障碍物所处的位置判断出障碍物的运动模态类型,则我们就能允许控制器选择不同的控制动作。我们用uin|k表示已知k时刻状态量的n时刻状态量时,模态i对应的控制量,当不能根据障碍物历史位置判断模态类型时,我们将不同模态的预测输入限制为同一值。由此得到的有限时域最优控制问题可表示为:

我们可以将式(7)的最优解写为U*k={ul*k|k,…, ul*k+N|k },并定义反馈策略为:
在k+1时刻,我们在滚动时域求解初始状态为,需要注意的是,上述公式并未对L种场景下的L个单独轨迹进行分别优化,而是将这L种场景在一个问题中组合起来,控制输入则通过约束(7f)将场景与轨迹联系在一起。由前可知,βi表示模态i的关联概率,各模态关联概率的和为1,因此式(7a)变为期望代价的近似问题。因此,式(7)使得期望代价最小化,并且平均性能优于式(5)。对于每种可能的运动模态而言,其代表了该种降低代价的做法仍能够保证安全,例如当一个行人很有可能横穿马路时,车辆需要确保在非必要的时候总是能不经历减速而停止。根据命题1可知,只有当障碍物不再处于某个模态时,与该模态关联的避障约束才能从问题中去除,也就是说,一旦行人开始横穿马路,他将不能继续在原有路线上继续直行。
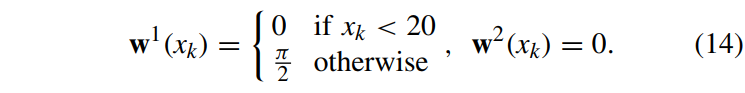

此外,式(7)形式的问题无法简便求解,而是通过收紧约束来重新表述为一个鲁棒模型预测控制问题[16]。而这本质上需要关于g在全局最大化的知识,事实上在一般情况下很难计算。但在某些情况下,这种计算可以变得非常高效。在一些研究中提出了精确的行人模型[8][13]。
式(7)建立了通向预期结果的第一步,即提出了策略(8)这样的式(2)的优化策略近似结果,并且在平均结果上具有更低的保守性。然而根据定义来看,式(2)始终满足安全要求,因此我们使用MPC中的标准方法[18][26][27],即假设存在一个鲁棒不变集。因此,利用以下假设可证明式(8)满足安全性要求。
假设2:对于任意模态i,总存在模态j,使得Oin|k⊆Oin|k-1对任意的n≥k均成立。
假设3:存在鲁棒不变集合Xsafe,使得存在u,满足:.

上述假设隐含于:
事实上,我们可以通过建立预测模型来避免导致控制器不可执行的不现实运动行为,例如一辆停止的车辆被认为是安全的,它不是发生碰撞的原因。类似的例子有在人-机环境中运动的静止机器人关节是安全的、被切断的电路是安全的。给出如下命题:
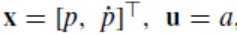
命题2:假设上述的假设2与假设3成立,则对于式(7),当有初始状态x0是可行的,则将式(7)的解在滚动时域内应用于闭环系统(1)是递归可行的。

可以证明,当假设式(7)在k=0时可行时,归纳得出k≥0时同样可行。
虽然我们只关注系统的安全性,即式(7)的递归可行性,但也可说明某种形式的稳定性[28]。接下来我们将通过数值仿真结果来说明我们所提出的策略在平均性能上由于标准鲁棒MPC。
5 仿真与结果分析
在本节中,我们将通过两个数值仿真例子来展示我们所提出策略的性能。我们定义系统的状态量与控制量为:状态量为位置与速度的标量,控制量为加速度。约束为:

我们已知参考值与参考约束为:
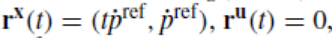

所有的仿真实例结构均为标准跟踪MPC,其阶段与终端代价函数分别定义为:,我们选择采样时间为ts=0.1秒,预测时域为N=90。我们按照[28]中的方法定义安全集,并使用CasADi[29]与IPOPT[30]来求解MPC。行人模型选用[8]中采用的,其特点是简单但准确。
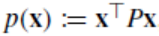

5.1 不确定静态障碍物
为了展示我们所提出策略的闭环系统表现,我们考虑如下场景:障碍物在k时刻的初始位置为pobs=20m,假设障碍物将于6秒后消失,因此我们仅考虑2种模态。约束函数可被定义为:
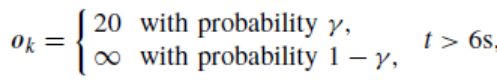
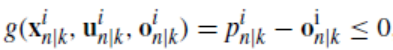
则预测集为:
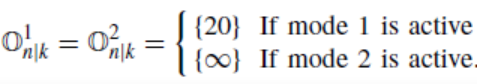
如图2所示为初始状态为x0=[-20,5]T的闭环轨迹。其中,γ=0表示对模态1而言,在时间达到6秒之前出现约束的概率为0,这使得闭环轨迹较为激进,只有在模态能够被区分开来时车辆才会减速;而γ=1时,闭环轨迹变得偏向保守,平滑的接近障碍物所在的位置,对应标准鲁棒MPC的策略;对于γ=0.5,控制器会尝试平衡其他两种行为的激进性与保守性,相较于γ=1时,控制器会保持更快的速度,而相较于γ=0时控制器将会更早的减速。
图2中的虚线表示当模态2激活时,系统的闭环行为。可以看到,γ=0时仅在必要的时候采取制动措施,因此模态2激活时车辆速度不变。然而γ>0时控制器变得更加保守,以相对低的速度接近约束。从图3中可以看到同样的现象,图3比较了我们所提出方法以及标准管模型预测控制策略的预期代价。

图2 在p=20m处有障碍物的情况下,所提出的场景MPC策略的闭环轨迹(虚线为t=6s之后解除约束时的闭环行为)

图3 鲁棒管模型预测控制策略与本文所提出控制策略的预期代价比较
5.2.不确定动态障碍物
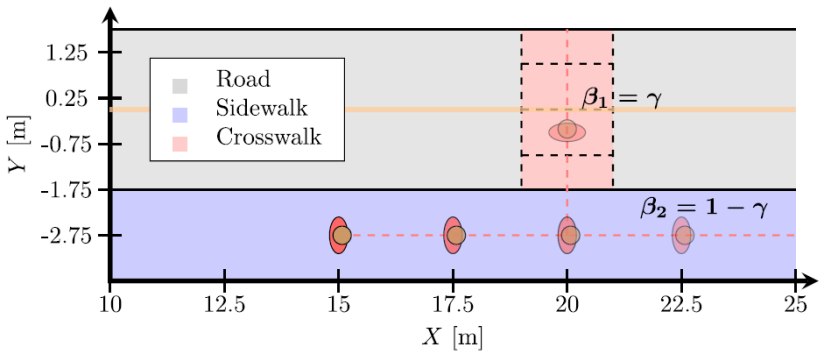
为了进一步比较控制策略的闭环性能,我们采用了更为复杂的动态场景,如图4所示,行人状态为:
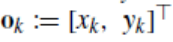
我们假定行人在达到x=20m的位置时,可能会横穿马路或沿y=-2.75的虚线继续直行。
图4 简化的行人行走场景
出于测量的方便,我们使用下式对两种模态进行预测:

当xk<20时,我们定义集合O1n|k与集合O2n|k,进而包含了障碍物的所有状态。可以看到,这个模型实际上是式(13)的非线性逼近。当xk<20时,激活的模态变为已知量,且O1n|k=O2n|k仅包含一个模态值。则约束函数g为:
其中r=1为行人的安全裕度,Δ=1.5m为需要是否将行人纳入避障范围的道路偏移量。与上部分类似,我们引入γ值,有β1=γ,β2=1-γ。

使用阶段代价函数,我们对[0,1]范围内的γ值进行仿真,并计算出其对应的闭环轨迹期望代价。我们将所提出的场景MPC与管模型预测控制相比较,并选择已知全约束g先验的MPC作为预期代价的下界值。
如图5所示为三种不同控制策略在初始状态为x0=[-20,5]、初始障碍物状态为O0=[15,-2.75]时的预期代价。可以看到,由于预先知道某个约束在将来是否会存在,因此有预见性的MPC控制器产生了最低的预期代价。可以看到,当γ值较小时,场景MPC的接近于最优的预见性MPC;然而当γ值接近1时,鲁棒MPC与场景MPC相差不大;当γ=1时,行人始终选择横穿马路,因此所有控制器的解以及期望代价相等。
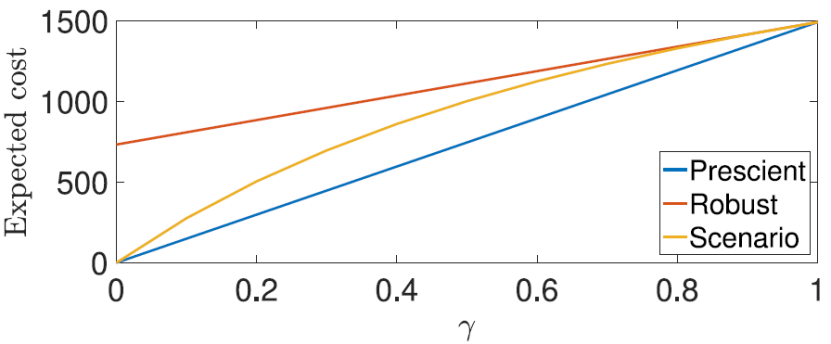
图5 不同γ值对应的不同控制策略预期代价
6 结论
本文介绍了一种保证了目标车辆避免与障碍物发生碰撞的MPC控制策略,我们设计了一种反馈策略,作为障碍物运动模态函数,使得其平均性能能够至少由于标准鲁棒MPC,并能够规划出不考虑障碍物轨迹时满足约束的控制序列。我们通过两个数值仿真实例对所提出的控制方案进行了评估,仿真结果表明我们所提出的策略在预期代价方面由于标准鲁棒MPC。未来我们将关注如何寻找更为合适的近似方式,用于适应包含那多障碍物时增加的计算复杂度。
参考文献:





联系人:唐老师
电话:021-69589116
邮箱:20666028@tongji.edu.cn - 下一篇:制造误差对纯电动乘用车三合一动力总成噪声影响
- 上一篇:沃尔沃移动方向盘技术专利曝光



 广告
广告 



最新资讯
-
联合国法规R73对货车侧面防护装置的工程化
2026-03-09 12:14
-
联合国法规R72对HS1卤素灯摩托车前照灯的工
2026-03-09 12:13
-
《汽车环境风洞 雪模拟试验及评价方法》国
2026-03-09 10:56
-
《汽车空气动力学与声学风洞 流场校准规范
2026-03-09 10:56
-
电池耐久试验方法的工程逻辑:SRC循环与多
2026-03-09 10:55
