




 广告
广告





















































视透雾天:看不见的恶劣天气中的深度多模式传感器融合
2020-09-16 12:22:36· 来源:同济智能汽车研究所

编者按:目标检测是自动驾驶车辆中基本的计算机视觉问题。由于自然偏向,现有的训练数据集偏向晴朗的天气,而恶劣天气下的数据非常罕见,现有的检测架构依赖于未
编者按:目标检测是自动驾驶车辆中基本的计算机视觉问题。由于自然偏向,现有的训练数据集偏向晴朗的天气,而恶劣天气下的数据非常罕见,现有的检测架构依赖于未失真的传感器流,而恶劣天气下传感器会产生非对称的失真,因此现有的目标检测方法不适用于恶劣天气场景。本文提出了一种自适应单次深度融合架构,并引入新型多模式数据集来解决现有数据集中的天气偏差,使本文的方法可以在晴朗天气的数据上进行训练,并将传感器不对称损坏的情况稳健地推广到恶劣天气的情况。
本文译自:
Seeing Through FogWithout Seeing Fog: Deep Multimodal Sensor Fusion in Unseen Adverse Weather
文章来源:
CVPR2020
作者:
Mario Bijelic, Tobias Gruber, Fahim Mannan, Florian Kraus, Werner Ritter, Klaus Dietmayer, Felix Heide
原文链接:
https://www.cs.princeton.edu/~fheide/AdverseWeatherFusion/
摘要:多模式传感器流的融合,例如相机,激光雷达和雷达测量,在自动驾驶汽车的目标检测中起着至关重要的作用,这些输入是自动驾驶汽车的决策基础。尽管现有方法在良好的环境条件下可以利用大量的信息,但在恶劣的天气中这些方法会失效,因为在这种情况下,传感器流可能会不对称地失真。这些罕见的“边缘情况”的场景没有呈现在可用的数据集里,而且现有的融合架构也不旨在解决这些问题。为了应对这一挑战,本文提出了一个新的多模式数据集,该数据集是在北欧10,000 多公里的行驶中获得的。尽管此数据集是恶劣天气下的第一个大型的多模式数据集,且具有10 万个激光雷达、相机、雷达和门控NIR传感器的标签,但由于极端天气很少见,因此不利于训练。为此,本文提出了一种深层融合网络,可进行稳健的融合,而无需涵盖所有非对称失真的大量标记训练数据。与提案层的融合不同,本文提出了一种由测量熵驱动的自适应融合特征的单次模型。本文在广泛的验证数据集中验证经过清晰数据训练的所提出方法。代码和数据可以在这个网站获得:https://github.com/princeton-computationalimaging/SeeingThroughFog。
1 前言
目标检测是自动驾驶机器人(包括自动驾驶车辆和自动驾驶无人机)中基本的计算机视觉问题。在具有挑战性的现实场景中,此类应用需要场景对象的2D 或3D 边界框,包括复杂的混乱场景,变化很大的照明以及恶劣的天气条件。最有前景的自动驾驶汽车系统依赖于来自多种传感器形式的大量输入[58、6、73],包括相机、激光雷达、雷达和新兴传感器(例如FIR)[29]。使用卷积神经网络进行物体检测的研究越来越多,这使得用这种多模态数据可以准确地进行2D 和3D 盒子估计,尤其是依赖于相机和激光雷达数据的[64、11、56、71、66、42、35]。
尽管这些现有方法以及在其输出上执行决策的自动驾驶系统在正常成像的条件下表现良好,但在恶劣的天气和成像条件下却无法使用。这是因为现有的训练数据集偏向晴朗的天气条件,并且检测器的架构设计仅依赖于未失真的传感流中的冗余信息。但是,它们不适用于恶劣的场景,这些场景会导致传感器流非对称变形,详见图1。极端天气情况在统计上很少见。例如,在北美,仅有0.01%典型驾驶情况下可以观察到浓雾;在大雾地区,每年能见度在50m 以下的浓雾最多发生15 次[61]。图3展示了瑞典四个星期内获得的实际驾驶数据分布,其中包括冬季行驶的10,000 km。自然偏倚的分布验证了可用数据集中很少甚至根本没有恶劣天气情况[65,19,58]。不幸的是,域自适应方法[44、28、41] 也没有对此提供解决方案,因为它们需要目标样本,而恶劣天气的失真数据通常很少被考虑。而且,现有方法限于图像数据,而不受限于多传感器数据,包括激光雷达点云数据。

图1 现有的物体检测方法,包括高效的单次检测器(SSD)[40],都是在偏向于良好天气条件的汽车数据集上进行训练的。虽然这些方法在良好的条件下效果很好[19,58],但在罕见的天气事件中却失败了(顶部)。由于在雾或雪(中心)中发生严重的反向散射,Lidaronly 探测器(例如在预计的激光雷达深度上训练的同一SSD 模型)可能会失真。这些不对称失真对依赖冗余信息的融合方法构成了挑战。本文所提出的方法(底部)将学习解决多模式数据中看不见的(可能不对称)失真的问题,而不会看到这些罕见情况的训练数据。
由于现有训练数据集中的传感器输入有限[65、19、58],目前已提出了主要用于激光雷达摄像机设置的融合方法[64、11、42、35、12]。由于训练数据的偏差,这些方法不只是专注于研究恶劣天气中的传感器失真。他们要么在独立处理各个传感器流后,通过过滤执行后期融合[12],要么融合假设[35] 或高级特征向量[64]。这些方法的网络架构是在假设数据流一致且冗余的前提下设计的,即出现在一个传感流中的目标也出现在另一个传感流中。但是,在恶劣的天气条件下,例如雾、雨、雪或极端光照条件下,包括低光照或低反射物体,多模式传感器配置可能会不对称地失效。例如,传统的RGB 相机在弱光场景区域中会产生不可靠的嘈杂测量,而扫描激光雷达传感器则使用主动照明来提供可靠的深度。在雨雪中,小颗粒同样会通过反向散射影响彩色图像和激光雷达深度估计。相反,在有雾或雪的天气下,由于反向散射,最新的脉冲激光雷达系统被限制在小于20m的范围内,请参见图4。虽然激光雷达可能是夜间驾驶的解决方案,但对于恶劣的天气并非如此。
本文的研究提出了一种多模式融合方法,可用于恶劣天气(包括雾,雪和大雨)中的目标检测,而没有适用于这些场景的大型注释训练数据集。具体来说,通过偏离现有的提案层融合方法来处理相机、激光雷达、雷达和门控NIR传感器流中的非对称测量损坏:本文提出了一种自适应单次深度融合架构,该架构在交织的特征提取器块中交换特征。这种深度的早期融合通过测量的熵来控制。提出的自适应融合能够学习在各种情况下进行概括的模型。为了验证此方法,通过引入三个月内在北欧采集的新型多模式数据集来解决现有数据集中的偏差。该数据集是恶劣天气下的第一个大型多模式驾驶数据集,具有10万个激光雷达、摄像机、雷达、门控NIR 传感器和FIR 传感器标签。尽管天气偏向仍然不利于训练,但是这些数据使本文的方法可以在晴朗天气的数据上进行训练,同时将传感器不对称损坏的情况稳健地推广到恶劣天气的情况。
具体来说,本文做出了以下贡献:
· 引入多模式恶劣天气数据集,涵盖了相机、激光雷达、雷达、门控NIR 和FIR 传感器数据。该数据集包含罕见的场景,例如在北欧行驶10,000 多公里时的大雾、大雪和大雨。
· 提出一个深度的多模式融合网络,该网络不同于提案层的融合,而是由测量熵驱动的自适应融合。
· 在本文提出的数据集上评估该模型,验证该模型可以推广到恶劣天气的不对称失真。在与天气无关的恶劣情况下(包括小雾、浓雾、大雪和晴朗的天气),该方法比先进的融合方法性能高出8%以上,并且可以实时运行。
2 相关研究
在恶劣的天气条件下进行检测 在过去的十年中,汽车数据集的开创性工作[5、14、19、16、65、9] 为汽车目标检测,深度估计[18、39、21],车道检测[26],交通信号灯检测[32],道路场景分割[5、2] 和端到端驾驶模型[4、65] 都提供了沃土[11、8、64、35、40、20]。尽管现有的数据集为该研究领域提供了动力,但由于地理位置[65] 和获得数据的季节[19],数据集偏向于良好的天气条件,因此缺乏罕见的雾、大雪和雨水引起的严重失真。许多近期的工作探索了在这种恶劣条件下仅使用摄像头的方法[51,7,1]。然而,这些数据集非常小,捕获的图像少于100个[51],并且仅限于摄像机的视觉任务。相比之下,现有的自动驾驶应用依赖于多模式传感器堆栈,包括摄像头、雷达、激光雷达和新兴传感器,例如门控NIR 成像[22、23],并且必须在数千小时的驾驶中进行评估。本研究填补了这一空白,并引入了一个大规模评估数据集,以便为这种多模式输入开发一种融合模型,该模型对恶劣天气下的失真具有鲁棒性。
恶劣天气中的数据预处理 大量研究探索了在处理之前消除传感器失真的方法。特别是,广泛地研究了从常规强度图像数据中去除雾气和雾霾的方法[67、70、33、53、36、7、37、46]。雾会导致对比度和色彩的距离损失。除雾方法不仅可以应用于显示[25],还可以作为预处理方法提高下游语义任务的性能[51]。现有的雾霾消除方法是依靠场景先验的潜在清晰图像和深度来解决不合适的恢复问题。这些先验是手动的[25],分别用于深度和传输估计,或者作为可训练的端到端模型的一部分共同学习[37、31、72]。用于照相机驾驶员辅助系统的雾和能见度估计的方法已被提出[57、59]。图像恢复方法也已应用于排水[10] 或去模糊[36]。
域适应 另一研究领域是通过域适应来解决未标记数据分布的变化[60,28,50,27,69,62]。这样的方法可以使清晰标记的场景适应苛刻的恶劣天气场景[28] 或通过特征自适应的表示[60]。不幸的是,这两种方法都难以一概而论,因为与现有的域传输方法相比,总体而言,受天气影响的数据(不仅是标记数据)的代表性不足。此外,现有方法不能处理多模式数据。
多传感器融合 通常融合自动驾驶汽车中的多传感器馈送以利用测量中的变化线索[43],以及简化路径规划[15],在出现失真的情况下实现冗余[47] 或解决联合视觉任务,例如作为3D对象检测[64]。现有的用于全自动驾驶的传感系统包括激光雷达,摄像头和雷达传感器。由于大型汽车数据集[65、19、58] 仅覆盖了有限的传感器输入,因此,现有的融合方法主要针对激光雷达相机设置[64、55、11、35、42]。诸如AVOD[35] 和MV3D [11] 之类的方法结合了相机和激光雷达的多个视图来检测物体。它们依赖于合并的感兴趣区域的融合,因此遵循主流的区域提议架构进行后期特征融合[49]。Qi 等人[48] 在另一项研究中和Xu 等[64] 提出了一种管道模型,该模型需要针对摄像机图像的有效检测输出以及从激光雷达点云中提取的3D 特征向量。Kim 等[34] 提出了一种用于相机-激光雷达融合的门控机制。在所有现有方法中,传感器流均在特征提取阶段进行单独处理,这会阻碍学习冗余,实际上,在存在非对称测量失真的情况下,其性能比单个传感器流差。
3 多模式恶劣天气数据集
为了评估恶劣天气中的目标检测,本文获得了一个大型的汽车数据集,该数据集提供了用于多模式数据的2D 和3D 检测边界框,并对罕见恶劣天气情况下的天气,光照和场景类型进行了精细分类。表2比较了本文的数据集和最近的大规模汽车数据集,例如Waymo[58],NuScenes[6],KITTI[19] 和BDD[68] 数据集。与[6] 和[68] 相比,本文的数据集不仅包含在晴朗天气条件下的实验数据,还包含在大雪,雨天和雾中的实验数据。补充材料中给出了注释程序和标签规格的详细说明。借助这种多模式传感器数据的跨天气注释和广泛的地理采样,它是现有数据集中唯一可以评估本文的多模式融合方法的。将来,设想研究人员可以开发和评估现有数据集未涵盖的天气条件下的多模式融合方法。
表1:提出的多模式恶劣天气数据集与现有的汽车检测数据集的比较。
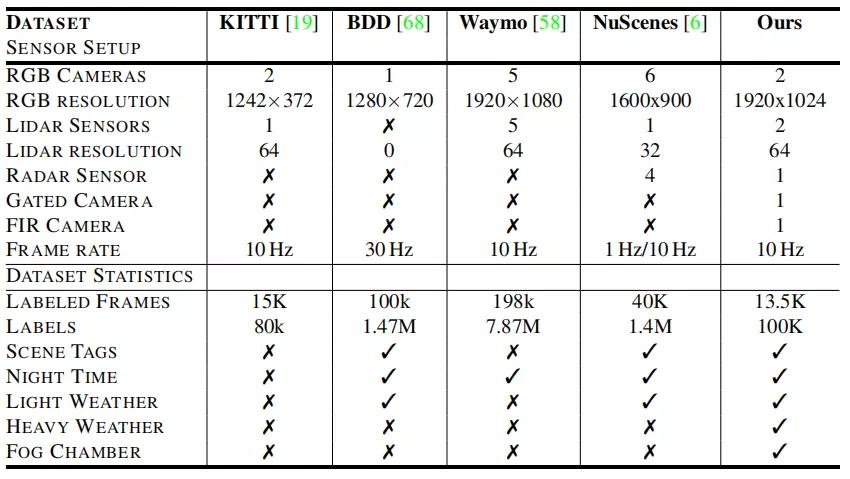
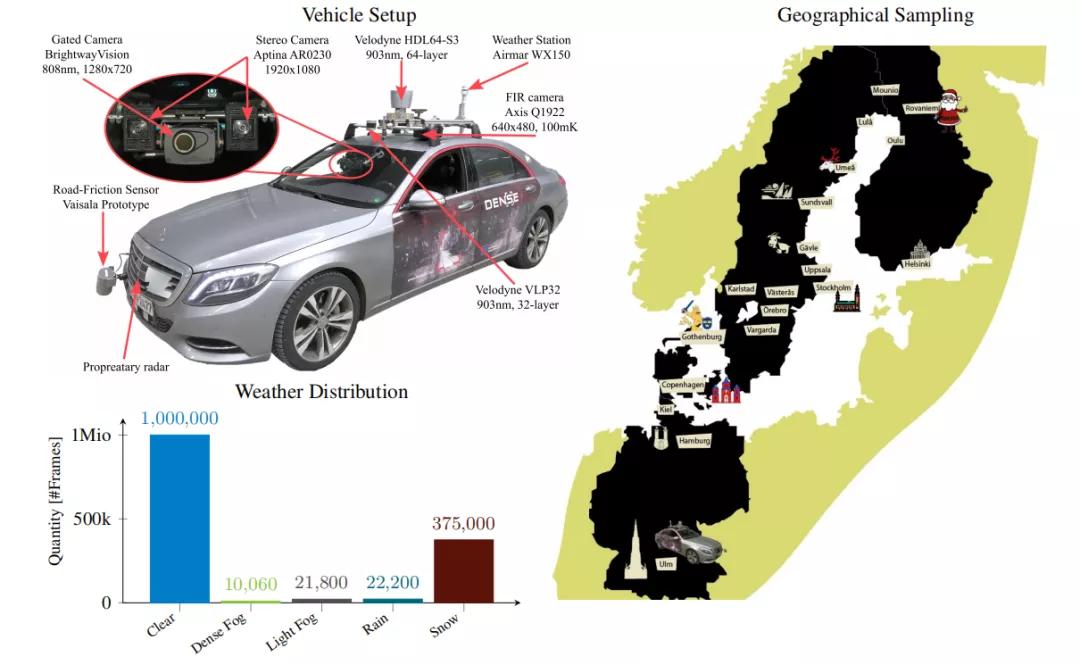
图3:绘制了上述数据集的天气分布。通过以0.1Hz 的帧速率手动注释所有同步帧来获得统计信息。当可见度分别低于1km[45] 和100m 以下时,指导注释者手动地将光与浓雾区分开。如果雾和降水同时发生,则根据环境道路状况将场景标记为下雪或下雨。对于本文的实验,将雪和雨天的情况结合。值得注意的是,统计数据证实了恶劣天气下的场景稀有性,这一点与[61] 一致,并说明了在评估真正的自动驾驶车辆时,即在没有在地理围栏区域之外的远程操作员交互的情况下,获取此类数据的难度和关键性。本文发现极端恶劣的天气条件仅在当地发生并且变化非常快。
个别的天气状况会导致各种传感器技术的不对称扰动,从而导致不对称退化,即,并非所有传感器输出均受到不断恶化的环境条件的统一影响,有些传感器的退化要比其他传感器要严重得多,请参见图4。例如,传统的被动式摄像机在白天条件下表现良好,但在夜间条件或光照不良的设置(例如低太阳光照)下其性能会下降。同时,激光雷达和雷达等有源扫描传感器受有源照明和检测边的窄带通环境的光变化影响较小。另一方面,有源激光雷达传感器的性能会由于雾,雪或雨等散射介质而大大退化,从而限制了在雾密度低于50m 至25m 时的最大可感知距离,请参见图4。毫米波雷达波不会在雾中强烈散射[24],但目前仅提供低方位角分辨率。最近的门控图像在恶劣天气下显示出稳健的感知能力[23],且具有较高的空间分辨率,但与标准成像仪相比缺少色彩信息。由于每个传感器这些特定的优缺点,多模式数据对于可靠的检测方法至关重要。
图3: 右:数据收集活动的地理覆盖范围,涵盖了两个月和德国,瑞典,丹麦和芬兰的10,000 公里。左上方:配置了顶部激光雷达,带闪光灯的门控摄像头,RGB 摄像头,专有雷达,FIR 摄像头,气象站和道路摩擦传感器的测试车辆的设置。左下:整个数据采集过程中天气状况的分布。驾驶数据相对于天气状况特别不平衡,包含恶劣天气的情况非常稀有。

图4: 在浓雾中的RGB 摄像头,扫描激光雷达,门控摄像头和雷达的多模式传感器响应。第一行显示了清晰条件下的参考记录,第二行显示了在可见度为23m 的雾中的记录。
3.1 多模式传感器设置
为了进行采集,为测试车辆配备了涵盖可见光,毫米波,NIR 和FIR 波段的传感器,请参见图3。测量光强度,深度和天气状况。
立体声相机 使用两个前置立体高动态范围的汽车RCCB 相机作为可见波长RGB 相机,由两台分辨率为1920 × 1024,基线为20.3cm 和12 位量化的onSemi AR0230 成像仪组成。摄像机以30Hz 的频率运行并同步进行立体成像。使用焦距为8mm 的Lensagon B5M8018C光学元件,可获得39.6◦ × 21.7◦ 的视场。
门控摄像机 使用以120Hz 运行,且分辨率为1280×720 和10 位位深度的BrightwayVisionBrightEye 摄像机,以在808nm 的近红外波段捕获门控图像。该摄像机提供与31.1◦ × 17.8◦ 的立体摄像机类似的视野。门控成像器依赖于时间同步相机和泛光闪光灯激光源[30]。激光脉冲发出可变的窄脉冲,在可调的延迟后,相机捕获激光回波。这可以显著减少恶劣天气条件下粒子的反向散射[3]。此外,高成像仪的速度可以捕获具有不同范围强度文件的多个重叠切片,这些切片对多个切片之间可提取的深度信息进行编码[23]。按照[23],以10Hz 的系统采样率捕获了3 个宽片用于深度估计,另外还捕获了3-4 个窄片及其被动对应关系。
雷达 对于雷达传感,使用专有的频率连续波(FMCW)雷达,频率为77GHz,角分辨率为1◦,最大距离为200m。雷达提供15Hz 的位置速度检测。
激光雷达 在汽车的车顶上,安装了两个来自Velodyne 的激光扫描仪,分别是HDL64S3D 和VLP32C。两者都在903nm 下工作,并且可以在10Hz 下提供双返回(最强和最强)。Velodyne HDL64 S3D 提供了平均分布的64 条扫描线,其角分辨率为0.4◦,而Velodyne VLP32C提供了32 条非线性分布的扫描线。HDL64 S3D 和VLP32C 扫描仪可以分别达到100m 和120m的范围。
FIR 摄像机 使用Axis Q1922 FIR 摄像机以30Hz 的温度捕获热图像。该相机的分辨率为640 × 480,像素间距为17μm,等效噪声温差(NETD)<100 mK。
环境传感器 使用提供温度,风速和湿度的Airmar WX150 气象站以及专有的道路摩擦传感器来测量环境信息。所有传感器均采用专有惯性测量单元(IMU)进行时间同步和自我运动校正。系统提供10 Hz 的采样率。
3.2 记录
真实记录 所有实验数据分别在德国,瑞典,丹麦和芬兰进行的试驾中获得, 两次试驾于2019 年二月和十二月进行,为期两个星期,在不同的天气和光照条件下覆盖了10,000km 的距离。以10Hz 的帧速率共收集了140 万帧。每第100 帧都经过手动标记,以平衡场景类型的覆盖范围。生成的注释包含5 500个晴天,1 000个浓雾,1 000个薄雾,4 000个雪/雨。大量的捕获工作表明在恶劣条件下训练数据是很少的。本文通过仅训练晴朗天气的数据,以及在恶劣情况下进行测试来解决此问题。训练区域和测试区域没有任何地理重叠。除了按帧划分外,还根据不同位置的独立记录(长度为5-60 分钟)对数据集进行划分。这些记录来自图3中所示的18个不同的主要城市以及沿途的几个较小的城市。
受控条件记录 为了在受控条件下收集图像和距离数据,还提供了在雾室中获取的测量值。雾室设置的详细信息可以在[17,13] 中找到。本文已经以10Hz 的帧速率捕获了35000帧,并在两种不同的光照条件(白天/夜晚)和三种雾密度下分别标记了1500帧的子集,其气象可见度V分别为30m,40m 和50m。补充材料中提供了详细信息,其中还使用[51] 中的正向模型对模拟数据集进行了比较。
4 自适应深度融合
本节描述了本文提出的自适应深度融合架构,该架构允许在出现不可见的不对称传感器失真的情况下实现多模式融合。本文在自动驾驶车辆和无人驾驶飞机所需的实时处理约束下设计架构。具体来说,本文提出了一种有效的单次融合架构。
4.1 自适应多模式单次融合
提出的网络架构如图5所示。它由多个单次检测分支组成,每个分支都分析一个传感器模式。
数据表示 相机分支使用常规的三平面RGB 输入,而对于激光雷达和雷达分支,本文的方法与最近的鸟瞰(BeV)投影[35] 方案或原始点云表示[64] 不同。BeV 投影或点云输入不允许进行深度的早期融合,因为早期图层中的特征表示与相机特征天生不同。因此,现有的BeV 融合方法只能在建议匹配区域之后进行提升空间中的特征融合,而不能提前。图5可视化了本文提出的输入数据编码,该编码有助于进行深度多模态融合。深度,高度和脉冲强度作为激光雷达网络的输入,而不是仅使用朴素的深度输入编码。对于雷达网络,假设雷达在与图像平面正交和与水平图像尺寸平行的2D 平面中进行扫描。因此,考虑沿垂直图像轴雷达的不变性,并沿垂直轴复制扫描。使用单应性映射将门控图像转换为RGB 相机的图像平面,这部分请参阅补充材料。本文所提出的输入编码使用不同流之间的逐像素对应,可以实现与位置和强度相关的融合。用零值来编码缺失的测量样本。
特征提取 作为每个流中的特征提取堆栈,本文使用了改进的VGG[54] 主干。类似于[35,11],将通道数量减少一半,并在conv4 层上切断网络。受[40,38] 的启发,使用conv4-10中的六个要素层作为SSD 检测层的输入。特征图的随尺寸减小,实现了一个用于不同比例检测的特征金字塔。如图5所示,不同特征提取堆栈的激活进行了交换。为了使融合更加可靠,为每个特征交换块提供了传感器熵。首先对熵进行卷积,应用S 形,与来自所有传感器的级联输入特征相乘,最后级联输入熵。熵的折叠和S 形的应用在区间[0,1] 中生成一个乘法矩阵,这可以根据可用信息分别缩放每个传感器的级联特征。具有低熵的区域可以被衰减,而富熵的区域可以在特征提取中被放大。这样做能够在特征提取堆栈中实现自适应融合特征,将在下一部分中深入探讨。
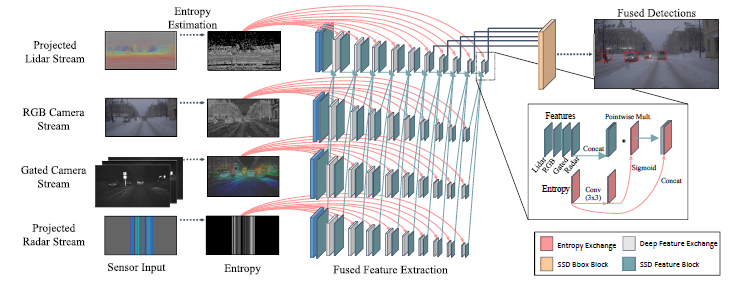
图5: 本文的体系结构概述,由四个单次检测器分支组成,具有深度特征交换和激光雷达,RGB 摄像头,门控摄像头和雷达的自适应融合。按照第4.1 节的规定,所有传感器数据都将投影到相机坐标系中。为了引导传感器之间的融合,模型依赖于传感器熵,该熵被提供给每个特征交换块(红色)。深层特征交换块(白色)与并行特征提取块交换信息(蓝色)。融合的特征图由SSD 块(橙色)分析。
4.2 熵导向融合
为了使深度融合具有冗余且可靠的信息,在每个传感器流中引入了一个熵通道,而不是像[57,59] 中那样直接推断恶劣的天气类型和强度。估计局部测量熵,
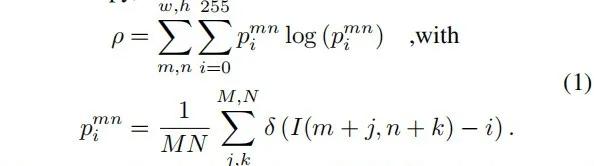
熵值是由本文提出的图像控件数据表示中,像素值i∈ [0, 255] 的每8 位二进制流I 计算得到的。每个流被分成大小为M×N = 16px×16px 的小块,从而产生w×ℎ = 1920px×1024px 的熵图。两种不同场景的多模式熵图如图6所示:左侧展示了在受控雾室内的场景,包含车辆,骑自行车的人和行人。随着雾的可见性降低,被动式RGB 相机和激光雷达会受到反向散射和衰减的影响,而门控相机则通过门控来抑制反向散射,雷达测量的性能在雾中也不会显著降低。图6中的右图显示了在变化的环境光照下的静态室外场景。在这种场景下,有源激光雷达和雷达不受环境照度变化的影响。对于门控摄像机,环境照明消失,仅保留主动照明的区域,而被动RGB 摄像机随着环境光线的减少性能逐渐下降。
控制过程完全是在晴朗的天气数据中学习的,其中包含白天到晚上的不同照明设置。在训练过程中,没有出现真正的恶劣天气模式。此外,以0.5 的概率随机放置传感器流,并将熵设置为恒定的零值。
4.3 损失功能和训练细节
各个特征图层中的锚框数量及其大小在训练过程中起着重要作用,可以在补充材料中查看。总的来说,每个带有等级yi 和概率pi 的锚框都使用带有softmax的交叉熵损失进行训练,
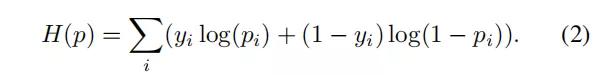
对于匹配阈值为0.5 的正锚定框和负锚定框,损耗将进行拆分。对于每个正锚点框,使用下式的Huber 损失H(x) 对边界框坐标x进行回归:
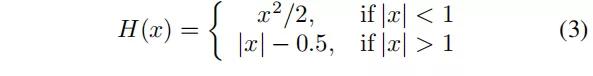
将负锚的总数限制为5× 使用示例[45,52] 的正示例的数量。从头开始训练所有网络,学习速率恒定,L2 权重衰减为0.0005。
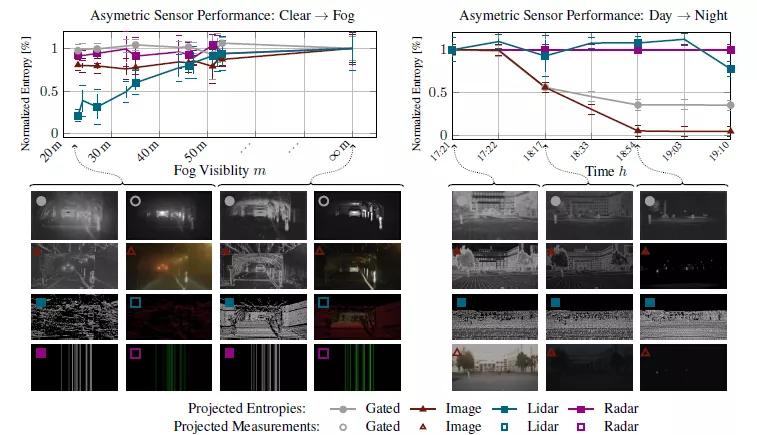
图6: 门控相机,RGB 相机,雷达和激光雷达在不同雾度(左)和光照(右)下带有清晰参考记录的归一化熵。熵是根据图4中所示的受控雾室内的动态场景(左)和具有变化的自然光照设置的静态场景(右)计算得出的。定量的数字已根据方程式1计算,注意不同传感器技术的非对称传感器故障。定性结果在下面给出,并通过箭头连接到其相应的雾密度/日间。
5 评估
本节将在恶劣天气的实验测试数据上验证所提出的融合模型。将这种方法与现有的单传感器输入和融合的检测器,以及域自适应方法进行比较。由于训练数据获取存在天气偏向,仅使用提出的数据集的晴朗天气部分进行训练。使用本文新的多模式天气数据集作为测试集来评估检测性能,请参阅补充数据以了解测试和训练分组的详细信息。
本文验证了表2中提出的基于真实恶劣天气数据的方法,将其称为“深度熵融合”。本文报告了三种不同难度级别(容易,中等,困难)的平均精度(AP),并根据KITTI 评估框架[19] 在各种雾密度,雪干扰和晴朗天气下对汽车进行了评估。将提出的模型与最新的激光雷达-照相机融合模型进行了比较,包括AVODFPN[35],Frustum PointNets[48],以及提出的方法的变体,比如另一种方式融合或传感器输入。作为基准变量,实现了两个融合和四个单传感器探测器。特别是,比较了后期融合和早期融合,后期融合有图像,激光雷达,门控和边界框回归(Fusion SSD)之前融合的雷达特征,早期融合是在一个特征提取堆栈的早期开始将所有传感器数据进行关联来融合(Concat SSD)。Fusion SSD 网络与提出的模型的结构是一样的,但没有特征交换和自适应融合层。此外,将提出的模型与具有单传感器输入的相同SSD 分支(仅图像SSD,仅门控SSD,仅激光雷达SSD,仅雷达SSD)进行了比较。所有模型都使用相同的超参数和锚点进行训练。
表2:对数据集中受真实的看不见天气影响的数据的定量检测AP,其中,数据根据天气和不同的难易程度划分(容易/中等/困难[19])除域适应法外,所有检测模型都仅针对清晰的数据进行训练,而不会出现天气失真。最佳模型以粗体突出显示。
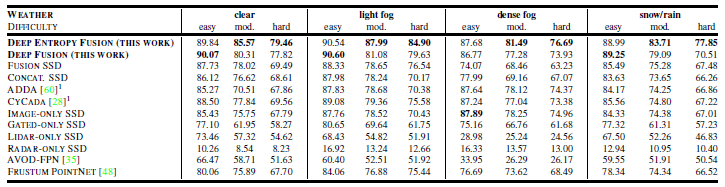
对恶劣天气情况进行评估时,所有方法的检测性能都会下降。值得一提的是,随着场景复杂度在天气分类之间变化,评估指标可能会同时增加。例如,当更少的车辆参与道路交通或者在冰雪的条件下车辆之间的距离增加时,阻塞的车辆更少。图像和门控数据的性能几乎稳定,但激光雷达数据却大幅下降,而雷达数据却有所提高。强烈的反向散射可以导致激光雷达性能的下降,请参阅补充材料。最多有100 个测量目标,这限制了雷达输入的性能,因此报告中的改进来自更简单的场景。
总体而言,在有雾条件下,激光雷达性能的大幅降低会影响仅激光雷达情况下的检测率,降低幅度为45.38%AP。此外,它还对相机-激光雷达融合模型AVOD,Concat SSD 和Fusion SSD产生了重大影响。它使得学习到的冗余不再成立,这些方法甚至低于仅使用图像的方法。
两阶段方法(例如Frustum PointNet[48])会迅速下降。但是,与AVOD 相比,它们渐近地实现了更高的结果,因为在第一阶段学习到的统计先验是基于仅图像SSD 的,这限制其性能为图像域先验。AVOD 受天气晴朗的几个假设所限制,例如在训练过程中对装有激光雷达数据的盒子进行重要性采样,从而获得最低的融合性能。此外,随着雾密度的增加,本文所提出的自适应融合模型的性能优于所有其他方法。特别是在严重失真的情况下,提出的自适应融合层在没有深度融合的情况下会在模型上产生很大的边际。总体而言,本文所提出的方法优于所有基准方法。在浓雾中,与次佳的特征融合变体相比,它提高了9.69%的边际。
为了完整起见,还将提出的模型与最新的领自适应方法进行比较。首先,根据[60]将仅图像SSD 特征从晴天转为恶劣天气。其次,利用[28] 研究从晴天到恶劣天气的特征转换,并从晴天输入中生成恶劣天气训练样本。值得一提的是,这些方法相对于所有其他比较方法均具有不公平的优势,因为它们已经从的验证集中看到了恶劣的天气情况。请注意,领域适应方法无法直接应用,因为它们需要来自特定领域的目标图像。因此,它们也无法为数据有限的罕见情况提供解决方案。此外,[28] 没有对包括雾或雪在内的失真进行建模,请参见补充材料中的实验。值得一提的是,遵循[51] 的合成数据增强或消除恶劣天气影响的图像到图像重建方法[63] 都不会影响所提出的多模式深度熵融合的边际。
6 结论和展望
本文解决了自动驾驶中的一个关键问题:场景中的多传感器融合,其中注释数据稀少且由于自然的天气偏向而难以获取。为了评估恶劣天气下的多模式融合,本文引入了一个新颖的恶劣天气数据集,涵盖了相机、激光雷达、雷达、门控NIR 和FIR 传感器数据。该数据集包含罕见的场景,例如在北欧行驶10,000 多公里时遇到的大雾,大雪和大雨。本文提出了一个实时的深度多模态融合网络,该网络不同于提案层的融合,而是由测量熵驱动自适应融合。未来研究的方向包括开发能够进行故障检测的端到端模型以及激光雷达传感器中的自适应传感器控制(例如噪声水平或功率水平控制)。
参考文献:



- 下一篇:汽车制动性评价及制动性能检测研究
- 上一篇:有感知的智能儿童安全座椅



 广告
广告 



最新资讯
-
千亩级基地开跑!比亚迪“5分钟充电”电池
2026-03-19 17:18
-
安全调试不踩坑!Workbench安全功能配置,
2026-03-19 17:10
-
联合国法规R89对车辆速度限制装置的工程化
2026-03-19 12:21
-
联合国法规R79对机动车转向装置安全性的工
2026-03-19 12:17
-
用于赛车运动车辆动力学测量的光学传感器
2026-03-18 21:31
