




 广告
广告





















































通过学习的交通先验知识产生可能出事故的驾驶场景
2022-01-23 00:37:54· 来源:计算机视觉深度学习和自动驾驶 作者:黄浴

arXiv在2021年12月9号上传论文"Generating Useful Accident-Prone Driving Scenarios via a Learned Traffic Prior",作者来自斯坦福大学、英伟达、多伦多大学和
arXiv在2021年12月9号上传论文"Generating Useful Accident-Prone Driving Scenarios via a Learned Traffic Prior",作者来自斯坦福大学、英伟达、多伦多大学和Vector Inst。

评估和改进自动驾驶车辆的规划需要可规模化的长尾交通场景生成。这些场景必须真实且具有挑战性,但并非不可能安全驾驶。该文介绍STRIVE(Stress-Test dRIVE),一种自动生成具有挑战性场景的方法,该场景会让给定规划器产生不希望的行为,如碰撞。为了保持场景的合理性,关键思想是以基于图conditional variational autoencoder(CVAE)的形式采用已学习的交通运动模型。场景生成是在该交通模型的潜空间进行优化,扰动初始真实场景产生与给定规划器发生碰撞的轨迹。随后的优化用于找到场景的“解决方案”,确保它有助于改进给定的规划器。进一步的分析,基于碰撞类型,聚类这些场景。实验中攻击了两个规划器,并证明在这两种情况下,STRIVE成功地生成了真实具有挑战性的场景。此外,实现“闭环”,并用这些场景优化一个基于规则的规划器超参数。
如图所示:STRIVE为给定的规划器生成具有挑战性的场景。对抗优化会扰乱所学习交通模型潜空间的真实场景,导致对抗(红色)与规划器(绿色)发生碰撞。后续的解决方案优化会找到规划器的轨迹避免碰撞,而验证场景有助于确定规划器的改进。

核心思想是,通过学习生成的交通运动模型可能性,衡量优化过程中场景的合理性,该模型鼓励场景具有挑战性,但又真实。因此,STRIVE不会提前选择特定的对抗,而是联合优化所有场景智体,从而产生多种多样的场景。此外,为了适应实践中广泛使用的不可微(或不可访问)规划器,所提出的优化在学习的运动模型中使用规划器的可微智体表征,从而允许用标准的基于梯度方法进行优化。
STRIVE不了解规划器的内部结构,也无法通过它计算梯度。不可取行为包括与其他车辆发生碰撞、不能驾驶地形、驾驶不舒适(如高加速)以及违反交通法规。虽然公式是一般性的,原则上可以处理其他目标(objective)函数优化,但重点是与规划器一起生成车辆碰撞相关的事故多发场景。
输入是一个规划器和一个地图(语义层),初始场景是给定2D BEV表示轨迹的多个智体,其中轨迹是2D 位置、朝向、速度和转角率。场景生成会打乱所有非自车智体的轨迹,最好地满足对抗目标:
可能自行车模型可以优化一个或一组对抗目标,这里采用VAE-type NN去学习交通模型的建模,然后在一个场景中参数化所有轨迹变成一个潜空间的向量,以此作为一个场景的合理性先验。
如图是学习的交通模型测试架构:为了对场景所有智体未来轨迹进行联合采样,首先对每个智体分别处理过去的运动和局部地图环境信息。然后,计算条件先验,输出每个节点的潜分布,该分布可通过auto regressive(AR)解码器进行采样馈入,预测未来的智体轨迹。
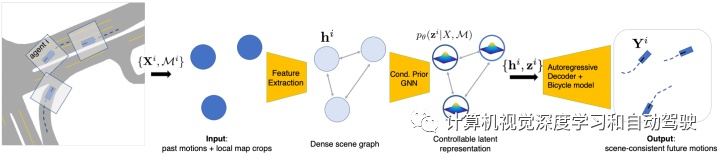
为了在测试时对未来运动进行采样,使用条件先验网络和解码器;两者都是图神经网络(GNN),在所有智体全连接的场景图运行。先验模型,包括一组智体的潜向量。输入场景图的每个节点都包含从该智体过去轨迹提取的上下文特征、局部光栅化地图、边界框大小和语义类等。消息传递(message passing)后,先验网络输出场景中每个智体的高斯分布参数,形成“分布”潜表征,捕捉未来可能的变化。
确定性解码器在场景图操作,每个节点都有采样的潜向量和过去轨迹上下文。解码是自回归(AR)方式执行的:在时间步t,一轮消息传递在预测每个智体加速之前解决交互;通过运动自行车模型,加速度立即获得下一个状态,该状态在继续展开之前更新轨迹上下文。解码器的可决定性和图结构鼓励场景一致的未来,即使在智体独立采样时也是如此。重要的是,对于潜向量优化,即使输入潜向量不太可能,解码器通过动态自行车模型确保合理的车辆动力学。
与场景交互模块一样,先验网络、后验(编码器)网络和解码器都是图神经网络(GNN),包括edge network, aggregation function, 和 update network。解码器会加入一个RNN(GRU)架构。
训练的CVAE目标函数是:
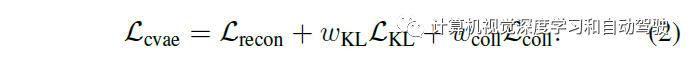
为此引入一个后验网络,类似于先验,这样得到:

其中


潜场景参数化在两个方面促进其合理性。首先,由于解码器是根据真实数据进行训练的,如果潜向量保持在学习的流形(manifold)附近,输出真实的交通模式。其次,学习的先验网络给出一个潜向量分布,用于惩罚不太可能出现的潜向量。这种强大的先验行为合理性可联合优化场景的所有智体,而不是事先选择的一小部分特定“对抗”。
如图所示:在对抗性优化的每个步骤,规划器和非自车的潜表征都用学习的解码器进行解码,非自车轨迹提供给规划器在场景中展开。最后,计算各个损失。
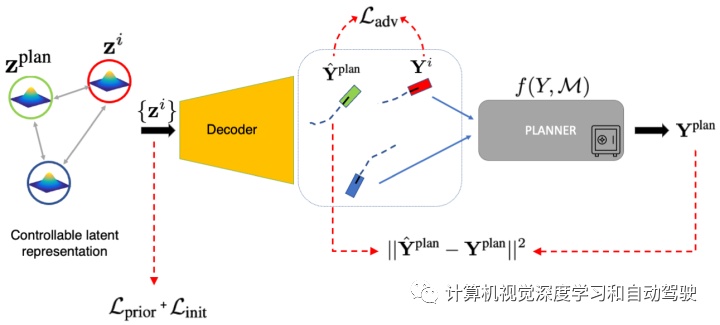
对抗优化包括两个目标:
-
Match Planner 内部近似和真规划器输出的匹配
-
Collide with Planner 让规划器和其他车辆发生碰撞

对抗项,通过最小化受控智体和规划器当前交通模型近似之间的位置距离,来鼓励碰撞:
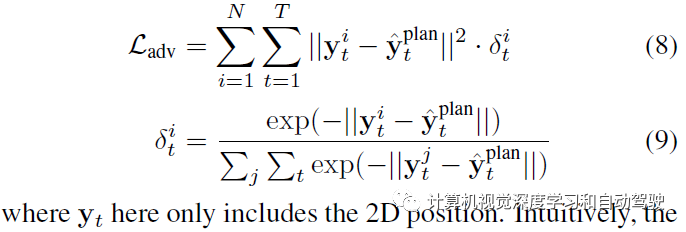
(9)的系数找到一个和规划器碰撞的候选智体及其时间步,系数最大的智体就是那个基于距离的对抗。
先验项,鼓励潜向量处在先验网络:
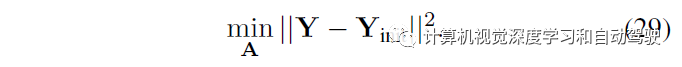
(11)的系数加权接近零的对抗,即接近与规划器发生碰撞的智体,允许偏离所学的交通流形(manifold),展示罕见且具有挑战性的行为。
初始项,鼓励在潜空间靠近初始化:
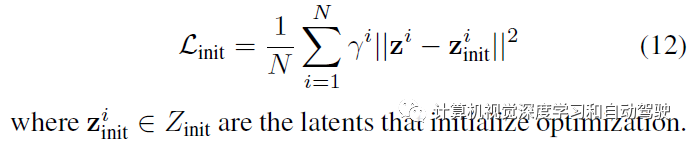
最后,碰撞项阻止非自车彼此相互碰撞以及进入不可驾驶区域。
在生成场景之后,需要进一步优化得到一个解决,即避免碰撞。非自车潜向量被调整以保持对抗轨迹,而规划的潜向量,进行优化以避免碰撞,并保持在先前的状态下。其解决方案优化和对抗优化的目标函数分别如下:
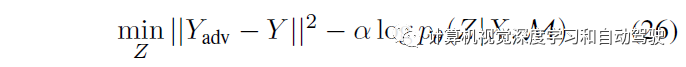
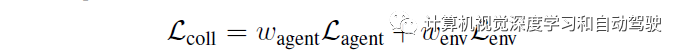
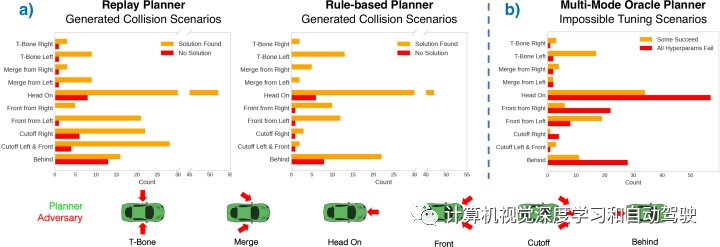
为深入了解冲突场景分布并通知下游应用,作者提出了一种简单的方法进行聚类和标记。场景的特点是在碰撞时规划器和对抗之间的关系:在规划器的局部框架中,计算对抗的相对位置和航向,对位置进行归一化,给出碰撞方向;这些碰撞特征通过k-means聚类,形成语义相似的事故分组,并通过视觉检查进行标记。
对于大量标记的碰撞场景,规划器可以通过两种方式进行改进。首先,如果生成许多相同类型的场景,可能需要对功能进行离散改进。例如,严格遵循车道的规划器在没有转向时会受到迎面或背后的碰撞,这表明必要的离开车道图(lane graph)新功能。其次,场景提供用于调整超参数或学习参数的数据。
另外,实验中有一个简单但有效的基于规则规划器,作为现实世界规划器的智体。基于规则的规划器模仿了2007年DARPA城市挑战赛成功团队使用的运动规划器结构。简而言之,它完全依赖于车道图来预测非自车的未来轨迹,并生成自车的候选轨迹。在这些候选者中,它选择覆盖距离最远且“碰撞概率”较低的那个。规划器行为受超参数影响,如最大速度/加速度以及碰撞概率如何计算。该规划器还有一个额外的限制,即它不能变道,这是STRIVE生成场景所暴露的限制。
其初始化和对抗优化目标函数分别为:
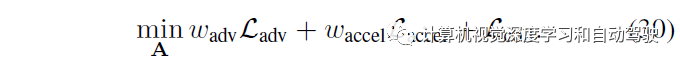
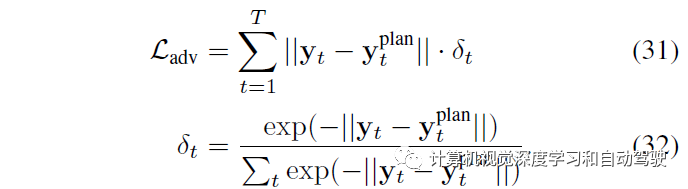
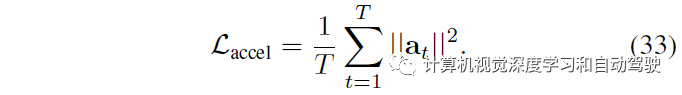
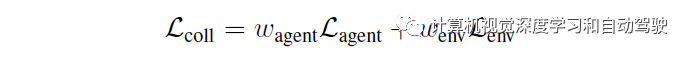
实验采用nuScenes数据集训练交通模型和初始化对抗优化。包含20秒的交通剪辑,标注频率为2赫兹,将其分为8秒场景。仅用汽车和卡车,交通模型运行在栅格化的可驾驶区域、停车场区域、道路分隔带和车道分隔带地图层。用nuScenes prediction challenge的分组和设置,即过去运动的2秒(4步)来预测未来的6秒(12步),这意味着碰撞场景的长度为8秒,但未来只有6秒轨迹得到优化。
场景生成在两个不同的规划器进行评估。回放(replay)的规划器只是从nuScenes数据中回放真值自车轨迹。这是一个开环设置,规划器未来6s完全展开,无需重新规划。基于规则的规划器允许更真实的闭环设置,其中规划器在未来的展开过程中,对周围智体的反应,是做5Hz的重新规划。
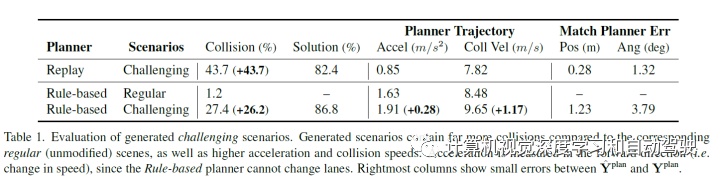
实验结果如下:
场景生成中Rule-based planner结果
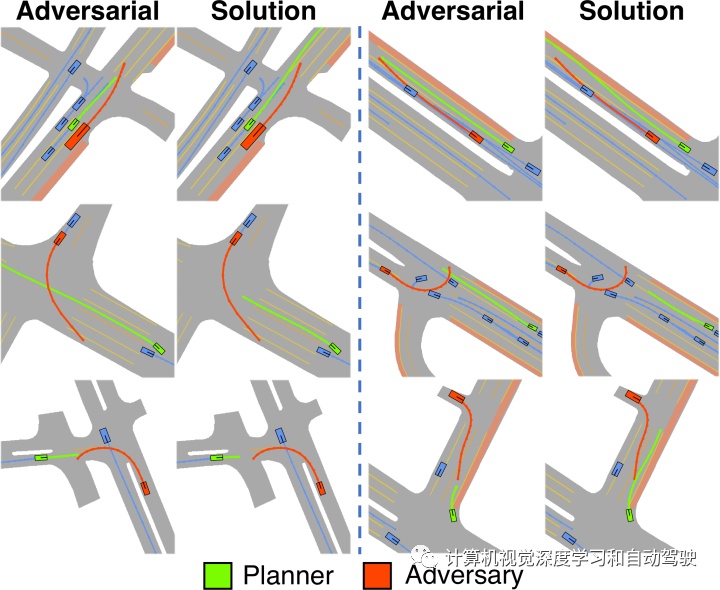
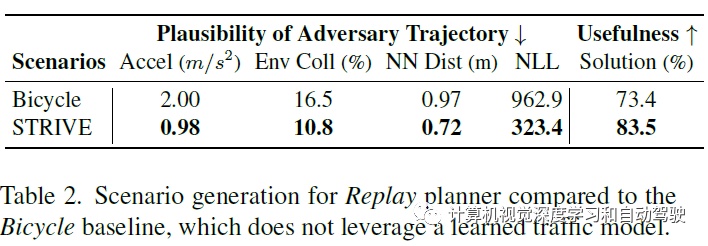
场景生成中Replay-planner和自行车模型的结果比较:
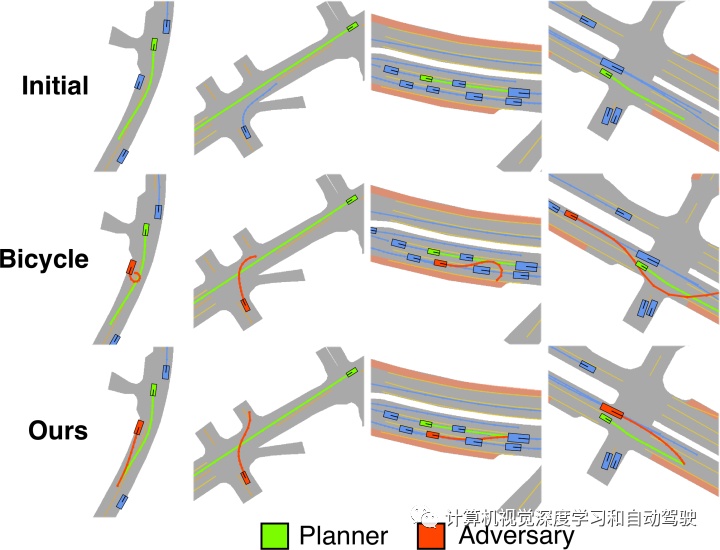
场景生成的结果比较评估:
场景生成中Replay planner和自行车模型的比较:
这是场景生成的分布比较以及用来调整多模态Oracle planner的场景:
STRIVE自动规模化地生成合理、易发生事故的场景,以改进给定的规划器。然而,其局限性提供了潜在的未来方向。假设完美的感知,并且只攻击规划器,但是交通模型场景参数化来附加攻击检测和跟踪是非常有趣的。当前版本的STRIVE根据现有数据生成场景,仅考虑车辆之间的碰撞,但其他危险或不舒适场景,如涉及行人和自行车的事件,也很重要。此外,其他类型的对抗,如添加/删除环境中的元素和更改地图拓扑,将发现额外的弱点。
该方法旨在通过将自动驾驶车暴露于类似于现实世界的挑战性罕见场景中,这样可以更安全。然而,在对抗场景下对规划器进行天真的调整可能会导致更危险的行为。必须注意以安全的方式将生成的场景集成到自动驾驶车测试和设计中。



 广告
广告 



最新资讯
-
国内首个“路空一体”国家级测试基地!南方
2026-03-23 17:23
-
1.5亿欧元项目投产,被动安全测试实验室同
2026-03-23 14:40
-
汽车测试方式大变局:工程师开始“远程做实
2026-03-23 14:38
-
国内首个螺栓式换电系统互换标准在厦门发布
2026-03-23 13:36
-
聚焦GB 45672-2025落地实施 | 中国汽研信息
2026-03-23 13:35
