




 广告
广告





















































电动汽车车内主动声音系统研究
2020-11-16 21:40:56· 来源:AUTO行家

摘要针对电动汽车在行驶过程中,车内声压级较低而引起的驾驶体验感降低和驾驶疲劳问题,文章提出了一种车内主动声音系统。首先,根据发动机声音特定的谐波结构和
摘要
针对电动汽车在行驶过程中,车内声压级较低而引起的驾驶体验感降低和驾驶疲劳问题,文章提出了一种车内主动声音系统。首先,根据发动机声音特定的谐波结构和主阶次准周期特性,对原始声音信号进行分解,并搭建声音样本数据库。随后,根据油门踏板开度信号对数据库中的声音样本实时读取,同时利用时域同步叠加方法对读取的声音样本进行合成。最后,在Matlab 仿真平台对本文的时域同步叠加方法进行仿真,并与传统直接叠加方法进行对比。仿真结果表明,虽然两种方法在匀减速和匀速的阶次分析结果相差不大,但与时域同步叠加方法相比,直接叠加方法合成的声音幅值存在一定程度不连续现象;在匀加速工况下,时域同步叠加方法合成的声音幅值和阶次成分精度方面都要优于直接叠加方法。
关键词:电动汽车;发动机声音;声音合成;主动声音;时域同步叠加
作者:张贤1,史晨路2,郑明军1,苏新2
单位:1.石家庄铁道大学 2.中汽研(天津)汽车工程研究院有限公司
来源:汽车实用技术
随着电动汽车的快速发展及日益普及,人们对于车内声音提出了更高的要求。与传统燃油车相比,电动汽车在行驶过程中车内有着较低声压级的声场环境,往往会增加驾驶员对于车内声场舒适性的感知程度,导致驾驶体验感降低,由于车内过于安静还可以造成的驾驶疲劳,所以在电动汽车上安装主动式声浪系统对驾驶人的驾驶乐趣、提高安全性、交互式体验方面尤为重要[1]。针对传统发动机声音合成技术,国内外许多专家、学者进行了广泛的研究。Amman 和Das [2]提出了一种基于确定性信号和随机信号分解原理的发动机声音合成方法,根据追踪发动机转速的离散傅里叶变换和次优多脉冲激励方法来产生逼真的发动机声音。Van Rensburg等人[3]提出了相位编码器的发动机声音合成方法,先将时域声音信号变换到频域进行处理,再反变换到频域,这种方法最大特点是以牺牲算法实时性来使其失真度最小,但是很难应用到实时性高的领域中。Pascal[4]设计了电子激振器控制系统,该系统可以通过算法合成一定频率宽度的噪声带及发动机阶次声音,可用于发动机声音阶次的增强和车外行人警示声的合成。Jagla等人[5]提出了一种改进时域基音同步叠加方法,根据原始声音信号建立声音样本数据库,通过识别发动机激励频率来实时读取数据库中的短时声音信号进行发动机声音合成,并对该方法进行了实验验证。Park[6]提出一种主动发声方法,使用此方法搭建的主动发声系统可以在较少的占用硬件的条件,发出较为真实的发动机声音。
综上,本文借鉴国内外声音合成方法经验,制定了主动声音系统的实现流程。以传统的内燃机汽车车内声音为基础进行声音样本数据库建立。根据时域同步叠加方法对读取的声音样本数据进行声音合成。同时考虑了车辆行驶过程中三种工况情况对主动声音方法的影响,在Matlab 下仿真完成方法验证,并与直接叠加方法结果进行对比。验证了该方法的声音合成效果,因此研究结果对于实际工程应用具有一定的现实意义。
1
发动机声音特性分析与采集
本文中研究的目标发动机为八缸四冲程汽油发动机。首先分析传统内燃机汽车声音特性,搭建车内阶次声音数学模型,然后对发动机声音信号进行阶次分析与数据采集,作为主动声音系统的原始发动机声音样本。
1.1 阶次声音数学模型
对于传统发动机来说,发动机的一次完整做功有四个冲程,每个气缸经历“吸气、压缩、做功、排气”完成一次做功循环,曲轴旋转两圈,当发动机转速为ne时,对应的发动机声音的基频f1为:

发动机点火频率fe为:

式中:ne为发动机每分钟转速,Nc为发动机气缸数量。发动机声音是由发动机舱内多个声源产生的相当复杂的信号,可将汽车发动机声音分为确定性信号的阶次声音以及随机信号的发动机宽频带声音[7]。在时域范围内,发动机阶次声音在连续时间信号xk(t)的表达式为:

式中:Ak(t)和φk(t)为谐波幅值和初相位,ωk(n)为随机信号成分。
1.2 原始声音样本采集
为减小外界环境噪声对实验结果的影响,提高实验的效率和数据精度,声音采集在汽车整车半消声实验室中进行。车辆预热完毕后,缓慢踩下加速油门踏板,通过在整个转速范围内连续缓慢变化,同步采集并记录车内麦克风声音数据,整个加速时间不少于100s,使得具有较高精度频率分辨率,保证了各阶次声音谐波成分频率、幅值、相位信息的准确性。数据采集频率为32000Hz,量化位数为16 位,将采集好的声音数据以WAV 文件格式存储。

图1 原始声音时域信号和时谱图
图1 为通过上述步骤采集缓慢加速工况下,车内声音时域信号和时谱图。根据时域信号图可以发现,随着时间和转速不断增加,声音信号的幅值也在平稳缓慢不断变大。车内声音的动态变化由随转速变化而变化的发动机阶次声音表征。通过时谱图可以清晰的看出,声音阶次成分清晰,存在非常明显的主阶次即4 阶次声音成分。不同阶次下的能量分布区别明显,低频率阶次声音在发动机整个转速区间内有明显贡献,其中4 阶次成分对车内声音的贡献量最大,同时随着发动机转速的不断增加,其他阶次成分对车内声音的贡献量也在不断增大,但是其他各阶次声音成分量级始终要低于4阶次。
2
主动声音系统实现
2.1 主动声音系统总体方案设计
为了保留原始信号数据的有效信息,保证采样信号的重、建不失真。设计发动机主动声音系统总体方案流程图如图2所示。

图2 主动声音系统总体方案流程图
2.2 声音样本数据库建立
通过原始声音信号阶次频谱特征发现,发动机主阶次对发动机声音总量级的贡献最大,所以对采集的发动机声音信号进行主阶次标记。以主阶次准周期特性为标尺,统计每一个过零点,且主阶次中第一个过零点位置是由负到正的一个相位区间中选取的,利用发动机声音信号具有明显周期性特点,每隔8n 个过零点加Δ个采样点对整个原始声音信号进行加窗处理,使得形成的一系列声音信号片段具有相同的初始相位,即每个声音信号片段都是从同一气缸点火开始,最后建立原始发动机声音样本数据库。
依据上述操作步骤,取n=1,Δ=512。对照每个声音片段所在的转速区间,为每个声音片段添加转速区间的起始与终止值,建立声音样本数据库。为方便后续处理,需要对每个声音片段做进一步的完善,因此每个声音样本片段主要包含以下内容:
(1)声音片段对应的索引号;
(2)整零点截取的采样点个数;
(3)声音合成所需的实际波形数据;
(4)声音片段实际对应的转速区间。
2.3.1 频率特性分析
采用变采样率方法,根据目标特性实现对主频频率的分析调整[8]。通过待合成输入信号Δ位置处,相邻两个采样点中线性插入新的采样点来达到增采样目的,线性插值方法可以保证重构数据不失真,也可以通过每隔几个采样点抽取一个点来达到降采样目的。从频域角度分析,采样率增加可以实现频谱的压缩,有频率降低的作用;采样率降低可以实现频谱的拉伸,有频率升高的作用[9]。若将线性插值与抽取相结合的变速率重采样原理,则可以实现任意有理数倍频率的变化。
假设起始频率为f0,变化后频率为f1,频率变化因子为a,则

其中M 和L 为频率变化前后变周期帧个数。要实现任意有理数倍频率的变化,采用以下公式:
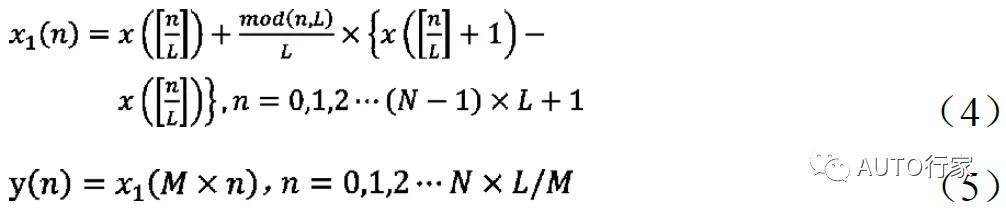
式中,N 为帧长,[]表示取整运算,mod 表示取模运算。当M>L 时,频率增大;当M




参考文献
2.3.2 幅值特性分析
相邻两个短时声音信号的叠加区会产生幅值的突变出现不连续现象,引入高频谐波。为保证叠加后的的声音信号幅值不失真,对重叠区进行变采样率处理后,在变频率的同时也会改变重叠区波形的幅值,需要对重叠区的信号幅值做衔接平滑连接处理。设叠加时输出序列用y(n)表示,所用的窗用p 表示,那么:
式中,y1(n)为前一个短时信号中后Δ'个采样点,y2(n)为后一个短时信号中的前Δ'个采样点,Δ'为平滑长度。
3
仿真与验证
车辆在道路上的行驶状况可分为加速、减速以及匀速三种运动状态,为验证本文中设计的时域同步叠加方法在三种工况下的有效性,基于MATLAB 平台对所设计的主动声音系统进行了编程实现,选择传统的直接叠加合成方法作为对比方法。进行仿真测试,匀加速和匀减速工况下得到时域信号图和时谱图,仿真结果如图3~图4 所示。匀速工况下得到时域信号图、频谱图和时谱图,仿真结果如图5 所示。
图3 匀加速工况下时域同步叠加与直接叠加方法对比
图3 为匀加速工况下时域同步叠加方法与直接叠加方法的对比图,时域信号(a)与时域信号(b)的幅值随时间变化趋势基本相同,但时域信号(b)中的幅值出现较多突变,某些阶次成分幅值变化存在一定程度不连续现象。为进一步对比时域同步叠加方法与直接叠加方法的合成效果,图中列出了两种方法的时谱图(a)、(b)。两种合成方法在匀加速过程中,主要阶次成分构成相同,且阶次成分清晰,但是直接叠加方法合成的声音引入了新的高频阶次;而时域同步叠加方法合成的声音保留了原始发动机声音丰富的发动机阶次成分,存在明显的发动机主阶次成分声音,没有明显增加新的阶次成分。
图4 匀减速工况下时域同步叠加与直接叠加方法对比
图5 匀速工况下时域同步叠加与直接叠加方法对比
图4 和图5 为两种合成方法在匀减速和匀速工况下合成 情况,通过在时域信号图(a)、(b)的对比发现,直接叠加 合成的声音幅值出现较大的波动,但对其时谱图(a)、(b) 的对比分析发现,时域同步叠加方法比直接叠加方法对合成 声音的幅值有较好的处理效果,但两种方法合成声音的主要 阶次成分和主要能量区域区别微小;匀速工况下的声音为频 率不随时间变化的稳态信号,傅里叶变换得到的频谱图(a)、 (b),可以发现两种方法的频率成分与各频率成分幅值基本 相同。
4、结论
本文提出了一种基于时域同步叠加方法的主动声音系统,它基于发动机声音主阶次准周期特性对原始发动机声音信号进行分解并建立声音样本数据库,再利用时域同步叠加固定方法对声音信号进行合成。最后在MATLAB 仿真平台下仿真验证,并与传统的直接叠加合成方法的仿真结果进行对比,得出如下结论。
(1)基于主阶次准周期特性建立的声音样本数据库,通过时域同步叠加方法与直接叠加方法均能实现对发动机声音的合成。
(2)仿真实验表明,时域同步叠加方法较直接叠加方法合成的声音质量更高,满足发动机阶次声音的合成精度要求,所以主动声音系统可用于电动汽车车内主动声音的合成。
参考文献
[1] Sarrazin M, Janssens K, Van der Auweraer H. Virtual Car SoundSynthesis Technique for Brand Sound Design of Hybrid and Electric Vehicles[J]. SAE Technical Paper 2012-36-0614, 2012.
[2] Amman S A, Das M. An efficient technique for modeling and synthesis of automotive engine sounds[J].IEEE Transactions on Industrial Electronics, 2001, 48(1): 225-234.
[3] Van Rensburg T J, Van Wyk M A, Potgieter A T, et al. Phase Vocoder Technology for the Simulation of Engine Sound[J]. International Journal of Modern Physics C, 2006, 17(05): 721-731.
[4] Pascal A. Active Sound Design[J]. SAE Technical Paper 2011-01-0927, 2011.
[5] Jagla J, Maillard J, Martin N, et al. Sample-based engine noise synthesis using an enhanced pitch-synchronous overlap-and-add method[J]. Journal of the Acoustical Society of America, 2012, 132(5): 3098-3108.
[6] Park H W, Bae M J. Virtual engine sound synthesis of eco-friendly vehicle[J]. Journal of Engineering and Applied Sciences, 2018,13(2):513-517.
[7] Min D, Park B, Park J, et al. Artificial Engine Sound Synthesis Method for Modification of the Acoustic Characteristics of Electric Vehicles[J]. Shock and Vibration, 2018:1-8.
[8] 田海津.一种改进的实时变调算法实现[J].电声技术,2009,33(09):73-76.
[9] 王艳芬,王刚,张晓光,等.数字信号处理原理及实现[M].北京:清华大学出版社,2007:102-107.



 广告
广告 

最新资讯
-
联合国法规R73对货车侧面防护装置的工程化
2026-03-09 12:14
-
联合国法规R72对HS1卤素灯摩托车前照灯的工
2026-03-09 12:13
-
《汽车环境风洞 雪模拟试验及评价方法》国
2026-03-09 10:56
-
《汽车空气动力学与声学风洞 流场校准规范
2026-03-09 10:56
-
电池耐久试验方法的工程逻辑:SRC循环与多
2026-03-09 10:55
